 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePcmNet: Position-Sensitive Context Modeling Network for Temporal Action Localization
Mar 09, 2021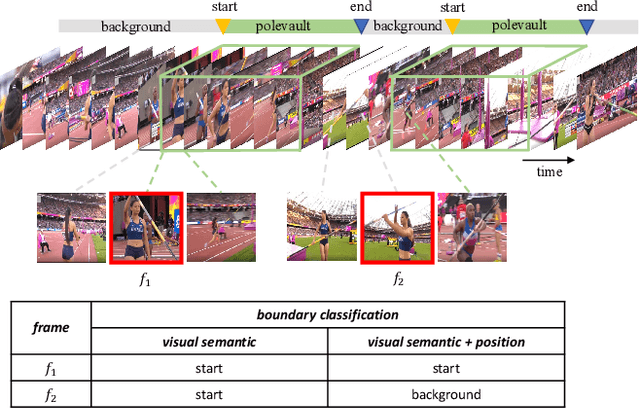
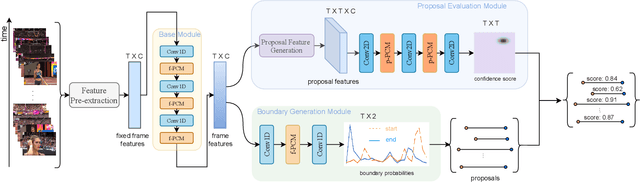
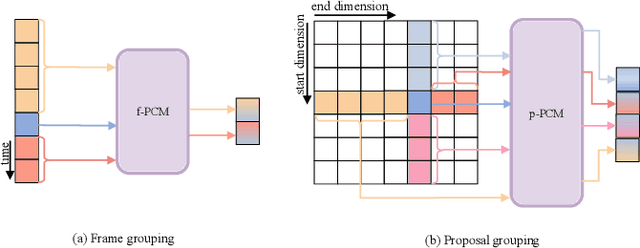
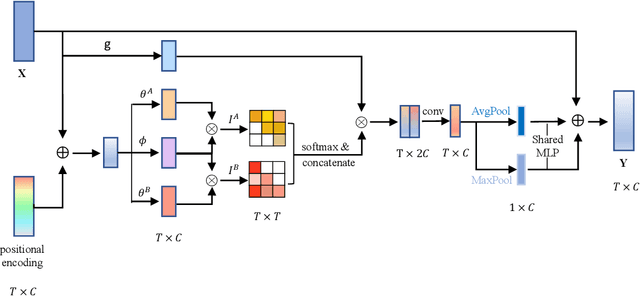
Temporal action localization is an important and challenging task that aims to locate temporal regions in real-world untrimmed videos where actions occur and recognize their classes. It is widely acknowledged that video context is a critical cue for video understanding, and exploiting the context has become an important strategy to boost localization performance. However, previous state-of-the-art methods focus more on exploring semantic context which captures the feature similarity among frames or proposals, and neglect positional context which is vital for temporal localization. In this paper, we propose a temporal-position-sensitive context modeling approach to incorporate both positional and semantic information for more precise action localization. Specifically, we first augment feature representations with directed temporal positional encoding, and then conduct attention-based information propagation, in both frame-level and proposal-level. Consequently, the generated feature representations are significantly empowered with the discriminative capability of encoding the position-aware context information, and thus benefit boundary detection and proposal evaluation. We achieve state-of-the-art performance on both two challenging datasets, THUMOS-14 and ActivityNet-1.3, demonstrating the effectiveness and generalization ability of our method.
BANet: Bidirectional Aggregation Network with Occlusion Handling for Panoptic Segmentation
Mar 31, 2020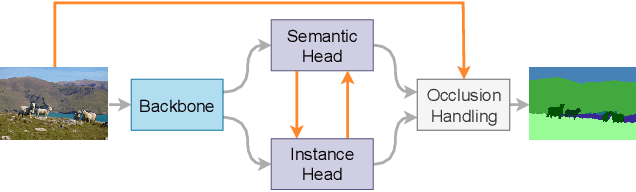
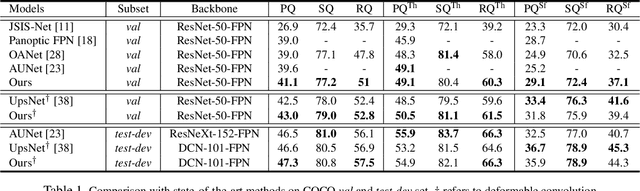
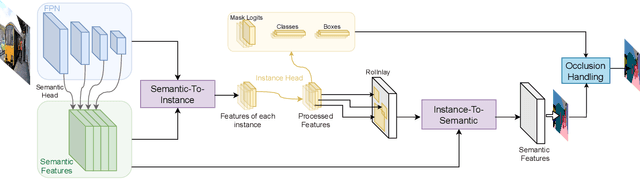

Panoptic segmentation aims to perform instance segmentation for foreground instances and semantic segmentation for background stuff simultaneously. The typical top-down pipeline concentrates on two key issues: 1) how to effectively model the intrinsic interaction between semantic segmentation and instance segmentation, and 2) how to properly handle occlusion for panoptic segmentation. Intuitively, the complementarity between semantic segmentation and instance segmentation can be leveraged to improve the performance. Besides, we notice that using detection/mask scores is insufficient for resolving the occlusion problem. Motivated by these observations, we propose a novel deep panoptic segmentation scheme based on a bidirectional learning pipeline. Moreover, we introduce a plug-and-play occlusion handling algorithm to deal with the occlusion between different object instances. The experimental results on COCO panoptic benchmark validate the effectiveness of our proposed method. Codes will be released soon at https://github.com/Mooonside/BANet.