 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniMesh: Unifying 3D Mesh Understanding and Generation
Apr 19, 2026Recent advances in 3D vision have led to specialized models for either 3D understanding (e.g., shape classification, segmentation, reconstruction) or 3D generation (e.g., synthesis, completion, and editing). However, these tasks are often tackled in isolation, resulting in fragmented architectures and representations that hinder knowledge transfer and holistic scene modeling. To address these challenges, we propose UniMesh, a unified framework that jointly learns 3D generation and understanding within a single architecture. First, we introduce a novel Mesh Head that acts as a cross model interface, bridging diffusion based image generation with implicit shape decoders. Second, we develop Chain of Mesh (CoM), a geometric instantiation of iterative reasoning that enables user driven semantic mesh editing through a closed loop latent, prompting, and re generation cycle. Third, we incorporate a self reflection mechanism based on an Actor Evaluator Self reflection triad to diagnose and correct failures in high level tasks like 3D captioning. Experimental results demonstrate that UniMesh not only achieves competitive performance on standard benchmarks but also unlocks novel capabilities in iterative editing and mutual enhancement between generation and understanding. Code: https://github.com/AIGeeksGroup/UniMesh. Website: https://aigeeksgroup.github.io/UniMesh.
Gait Cycle-Inspired Learning Strategy for Continuous Prediction of Knee Joint Trajectory from sEMG
Jul 25, 2023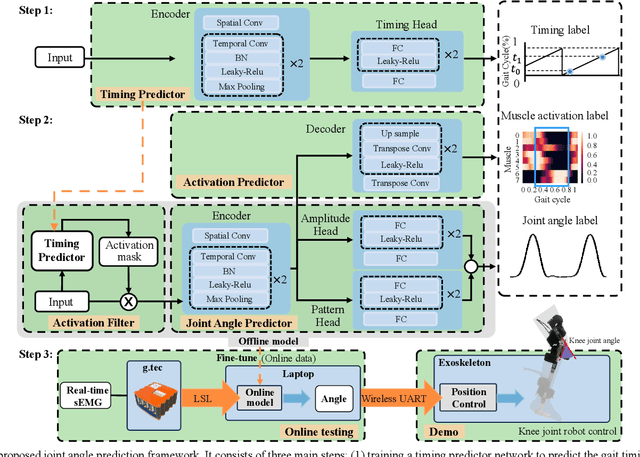
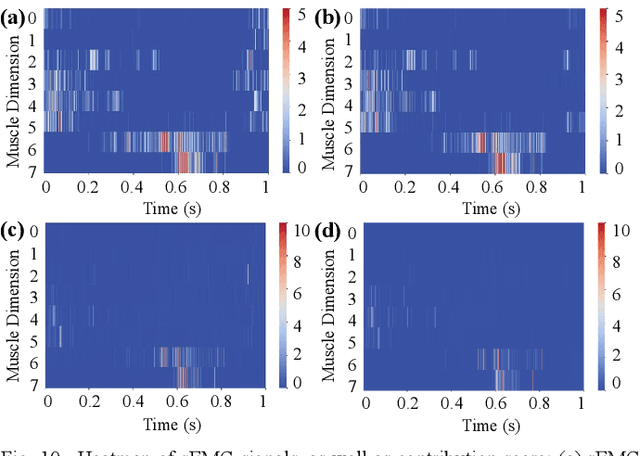
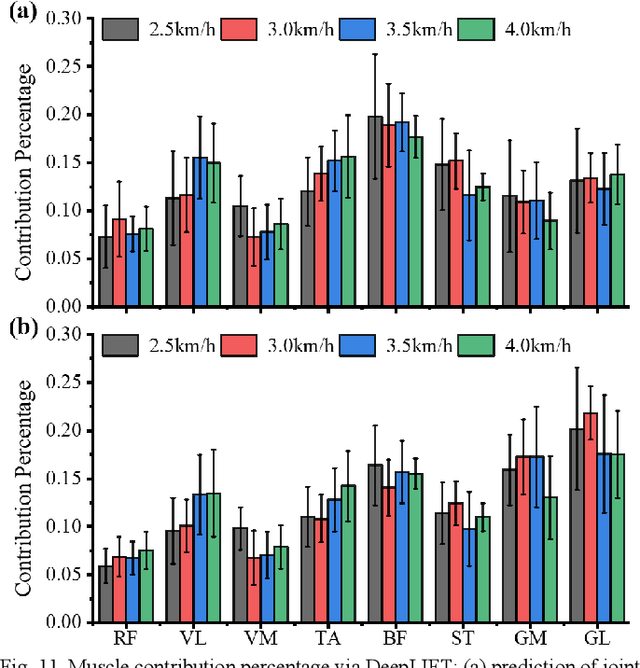
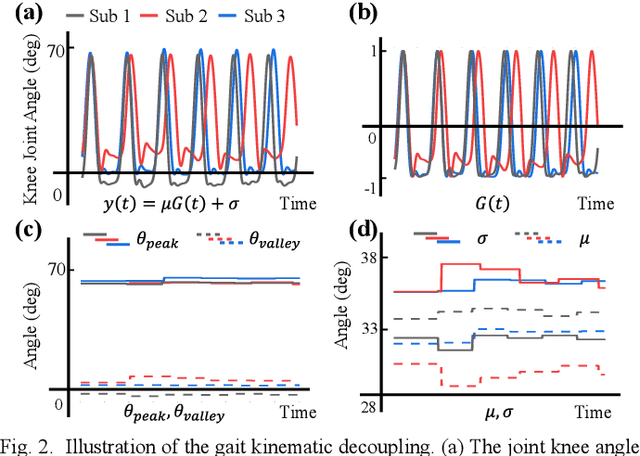
Predicting lower limb motion intent is vital for controlling exoskeleton robots and prosthetic limbs. Surface electromyography (sEMG) attracts increasing attention in recent years as it enables ahead-of-time prediction of motion intentions before actual movement. However, the estimation performance of human joint trajectory remains a challenging problem due to the inter- and intra-subject variations. The former is related to physiological differences (such as height and weight) and preferred walking patterns of individuals, while the latter is mainly caused by irregular and gait-irrelevant muscle activity. This paper proposes a model integrating two gait cycle-inspired learning strategies to mitigate the challenge for predicting human knee joint trajectory. The first strategy is to decouple knee joint angles into motion patterns and amplitudes former exhibit low variability while latter show high variability among individuals. By learning through separate network entities, the model manages to capture both the common and personalized gait features. In the second, muscle principal activation masks are extracted from gait cycles in a prolonged walk. These masks are used to filter out components unrelated to walking from raw sEMG and provide auxiliary guidance to capture more gait-related features. Experimental results indicate that our model could predict knee angles with the average root mean square error (RMSE) of 3.03(0.49) degrees and 50ms ahead of time. To our knowledge this is the best performance in relevant literatures that has been reported, with reduced RMSE by at least 9.5%.
CFNet: Learning Correlation Functions for One-Stage Panoptic Segmentation
Jan 13, 2022
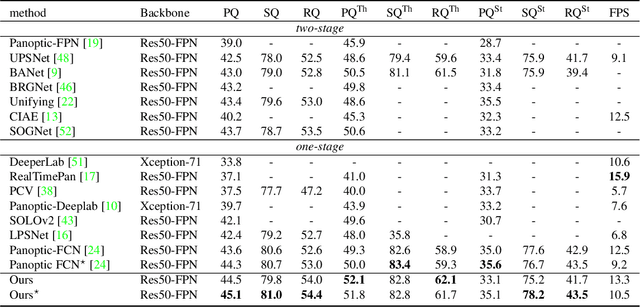
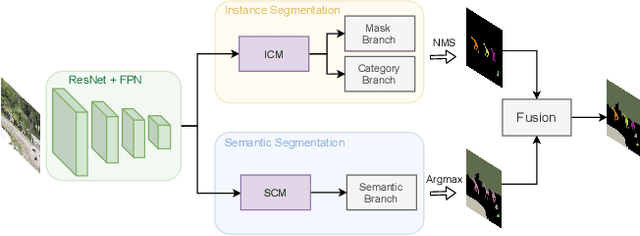
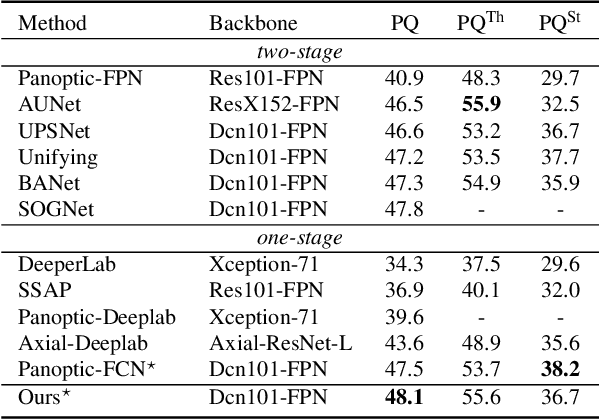
Recently, there is growing attention on one-stage panoptic segmentation methods which aim to segment instances and stuff jointly within a fully convolutional pipeline efficiently. However, most of the existing works directly feed the backbone features to various segmentation heads ignoring the demands for semantic and instance segmentation are different: The former needs semantic-level discriminative features, while the latter requires features to be distinguishable across instances. To alleviate this, we propose to first predict semantic-level and instance-level correlations among different locations that are utilized to enhance the backbone features, and then feed the improved discriminative features into the corresponding segmentation heads, respectively. Specifically, we organize the correlations between a given location and all locations as a continuous sequence and predict it as a whole. Considering that such a sequence can be extremely complicated, we adopt Discrete Fourier Transform (DFT), a tool that can approximate an arbitrary sequence parameterized by amplitudes and phrases. For different tasks, we generate these parameters from the backbone features in a fully convolutional way which is optimized implicitly by corresponding tasks. As a result, these accurate and consistent correlations contribute to producing plausible discriminative features which meet the requirements of the complicated panoptic segmentation task. To verify the effectiveness of our methods, we conduct experiments on several challenging panoptic segmentation datasets and achieve state-of-the-art performance on MS COCO with $45.1$\% PQ and ADE20k with $32.6$\% PQ.
TextRay: Contour-based Geometric Modeling for Arbitrary-shaped Scene Text Detection
Aug 12, 2020
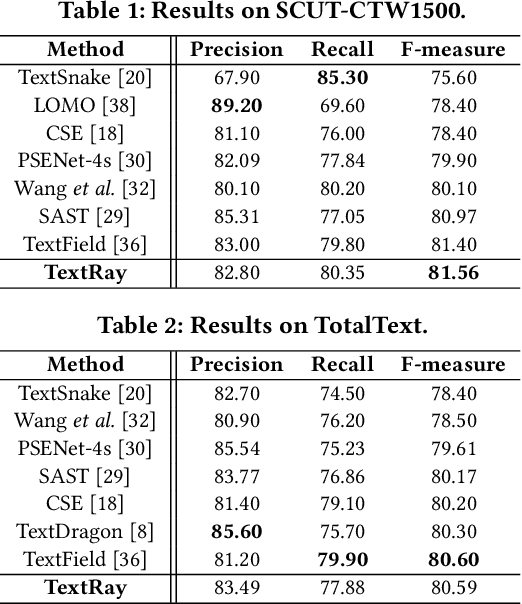
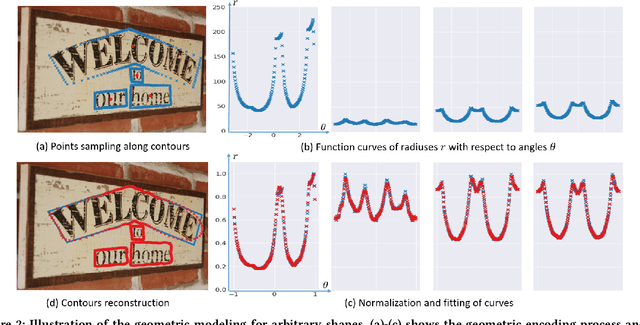
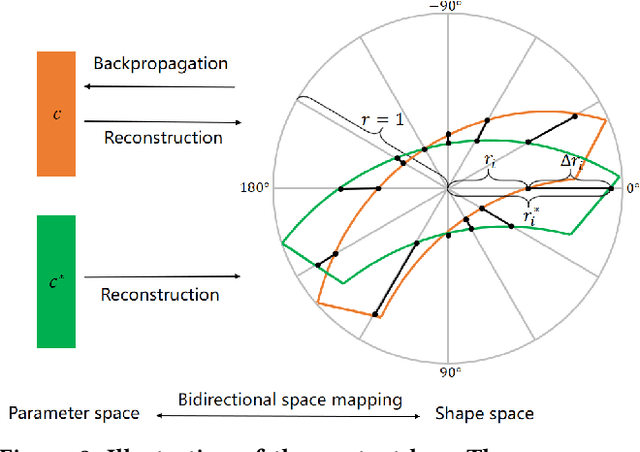
Arbitrary-shaped text detection is a challenging task due to the complex geometric layouts of texts such as large aspect ratios, various scales, random rotations and curve shapes. Most state-of-the-art methods solve this problem from bottom-up perspectives, seeking to model a text instance of complex geometric layouts with simple local units (e.g., local boxes or pixels) and generate detections with heuristic post-processings. In this work, we propose an arbitrary-shaped text detection method, namely TextRay, which conducts top-down contour-based geometric modeling and geometric parameter learning within a single-shot anchor-free framework. The geometric modeling is carried out under polar system with a bidirectional mapping scheme between shape space and parameter space, encoding complex geometric layouts into unified representations. For effective learning of the representations, we design a central-weighted training strategy and a content loss which builds propagation paths between geometric encodings and visual content. TextRay outputs simple polygon detections at one pass with only one NMS post-processing. Experiments on several benchmark datasets demonstrate the effectiveness of the proposed approach. The code is available at https://github.com/LianaWang/TextRay.
How to Train Your Dragon: Tamed Warping Network for Semantic Video Segmentation
May 04, 2020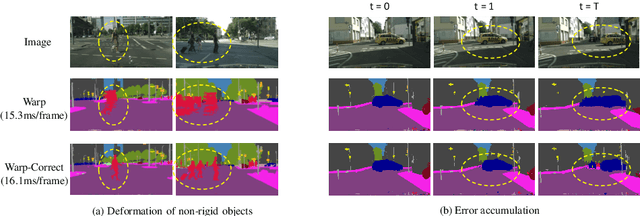
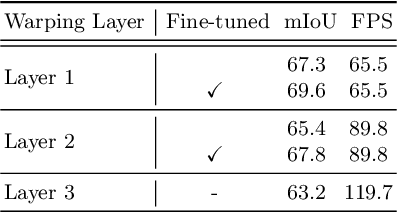
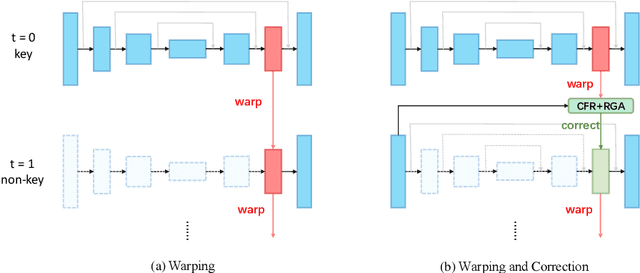
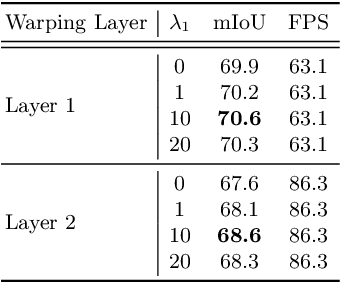
Real-time semantic segmentation on high-resolution videos is challenging due to the strict requirements of speed. Recent approaches have utilized the inter-frame continuity to reduce redundant computation by warping the feature maps across adjacent frames, greatly speeding up the inference phase. However, their accuracy drops significantly owing to the imprecise motion estimation and error accumulation. In this paper, we propose to introduce a simple and effective correction stage right after the warping stage to form a framework named Tamed Warping Network (TWNet), aiming to improve the accuracy and robustness of warping-based models. The experimental results on the Cityscapes dataset show that with the correction, the accuracy (mIoU) significantly increases from 67.3% to 71.6%, and the speed edges down from 65.5 FPS to 61.8 FPS. For non-rigid categories such as "human" and "object", the improvements of IoU are even higher than 18 percentage points.
BANet: Bidirectional Aggregation Network with Occlusion Handling for Panoptic Segmentation
Mar 31, 2020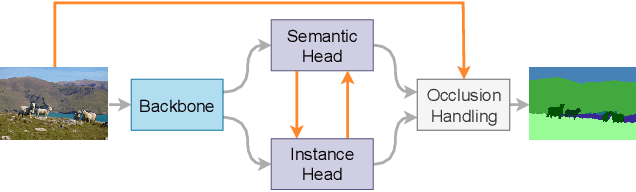
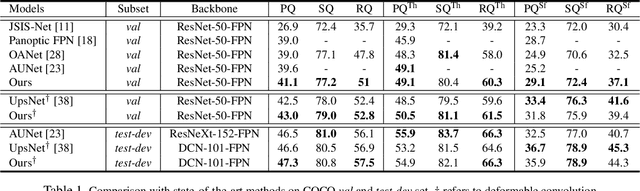
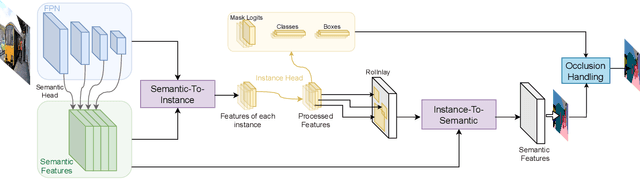

Panoptic segmentation aims to perform instance segmentation for foreground instances and semantic segmentation for background stuff simultaneously. The typical top-down pipeline concentrates on two key issues: 1) how to effectively model the intrinsic interaction between semantic segmentation and instance segmentation, and 2) how to properly handle occlusion for panoptic segmentation. Intuitively, the complementarity between semantic segmentation and instance segmentation can be leveraged to improve the performance. Besides, we notice that using detection/mask scores is insufficient for resolving the occlusion problem. Motivated by these observations, we propose a novel deep panoptic segmentation scheme based on a bidirectional learning pipeline. Moreover, we introduce a plug-and-play occlusion handling algorithm to deal with the occlusion between different object instances. The experimental results on COCO panoptic benchmark validate the effectiveness of our proposed method. Codes will be released soon at https://github.com/Mooonside/BANet.