 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Vision-Language-Action-Critic Model for Robotic Real-World Reinforcement Learning
Sep 19, 2025Robotic real-world reinforcement learning (RL) with vision-language-action (VLA) models is bottlenecked by sparse, handcrafted rewards and inefficient exploration. We introduce VLAC, a general process reward model built upon InternVL and trained on large scale heterogeneous datasets. Given pairwise observations and a language goal, it outputs dense progress delta and done signal, eliminating task-specific reward engineering, and supports one-shot in-context transfer to unseen tasks and environments. VLAC is trained on vision-language datasets to strengthen perception, dialogic and reasoning capabilities, together with robot and human trajectories data that ground action generation and progress estimation, and additionally strengthened to reject irrelevant prompts as well as detect regression or stagnation by constructing large numbers of negative and semantically mismatched samples. With prompt control, a single VLAC model alternately generating reward and action tokens, unifying critic and policy. Deployed inside an asynchronous real-world RL loop, we layer a graded human-in-the-loop protocol (offline demonstration replay, return and explore, human guided explore) that accelerates exploration and stabilizes early learning. Across four distinct real-world manipulation tasks, VLAC lifts success rates from about 30\% to about 90\% within 200 real-world interaction episodes; incorporating human-in-the-loop interventions yields a further 50% improvement in sample efficiency and achieves up to 100% final success.
CLSP: High-Fidelity Contrastive Language-State Pre-training for Agent State Representation
Sep 24, 2024With the rapid development of artificial intelligence, multimodal learning has become an important research area. For intelligent agents, the state is a crucial modality to convey precise information alongside common modalities like images, videos, and language. This becomes especially clear with the broad adoption of reinforcement learning and multimodal large language models. Nevertheless, the representation of state modality still lags in development. To this end, we propose a High-Fidelity Contrastive Language-State Pre-training (CLSP) method, which can accurately encode state information into general representations for both reinforcement learning and multimodal large language models. Specifically, we first design a pre-training task based on the classification to train an encoder with coarse-grained information. Next, we construct data pairs of states and language descriptions, utilizing the pre-trained encoder to initialize the CLSP encoder. Then, we deploy contrastive learning to train the CLSP encoder to effectively represent precise state information. Additionally, we enhance the representation of numerical information using the Random Fourier Features (RFF) method for high-fidelity mapping. Extensive experiments demonstrate the superior precision and generalization capabilities of our representation, achieving outstanding results in text-state retrieval, reinforcement learning navigation tasks, and multimodal large language model understanding.
Building Open-Ended Embodied Agent via Language-Policy Bidirectional Adaptation
Dec 12, 2023Building open-ended learning agents involves challenges in pre-trained language model (LLM) and reinforcement learning (RL) approaches. LLMs struggle with context-specific real-time interactions, while RL methods face efficiency issues for exploration. To this end, we propose OpenContra, a co-training framework that cooperates LLMs and GRL to construct an open-ended agent capable of comprehending arbitrary human instructions. The implementation comprises two stages: (1) fine-tuning an LLM to translate human instructions into structured goals, and curriculum training a goal-conditioned RL policy to execute arbitrary goals; (2) collaborative training to make the LLM and RL policy learn to adapt each, achieving open-endedness on instruction space. We conduct experiments on Contra, a battle royale FPS game with a complex and vast goal space. The results show that an agent trained with OpenContra comprehends arbitrary human instructions and completes goals with a high completion ratio, which proves that OpenContra may be the first practical solution for constructing open-ended embodied agents.
How to Train Your Dragon: Tamed Warping Network for Semantic Video Segmentation
May 04, 2020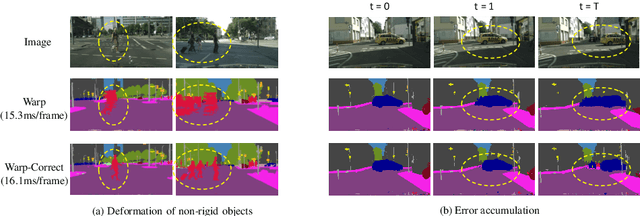
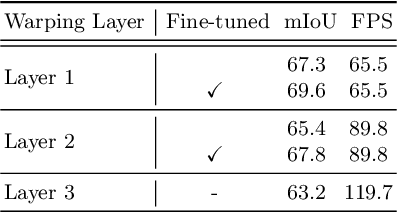
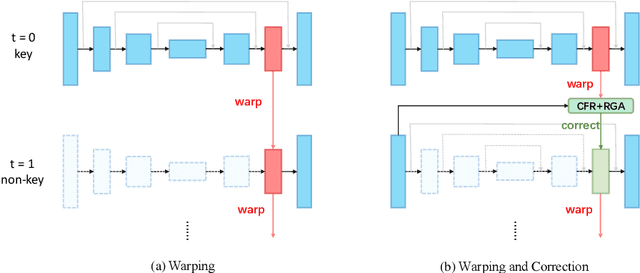
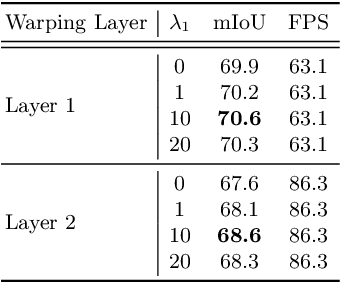
Real-time semantic segmentation on high-resolution videos is challenging due to the strict requirements of speed. Recent approaches have utilized the inter-frame continuity to reduce redundant computation by warping the feature maps across adjacent frames, greatly speeding up the inference phase. However, their accuracy drops significantly owing to the imprecise motion estimation and error accumulation. In this paper, we propose to introduce a simple and effective correction stage right after the warping stage to form a framework named Tamed Warping Network (TWNet), aiming to improve the accuracy and robustness of warping-based models. The experimental results on the Cityscapes dataset show that with the correction, the accuracy (mIoU) significantly increases from 67.3% to 71.6%, and the speed edges down from 65.5 FPS to 61.8 FPS. For non-rigid categories such as "human" and "object", the improvements of IoU are even higher than 18 percentage points.
Progressive Multi-Stage Learning for Discriminative Tracking
Apr 01, 2020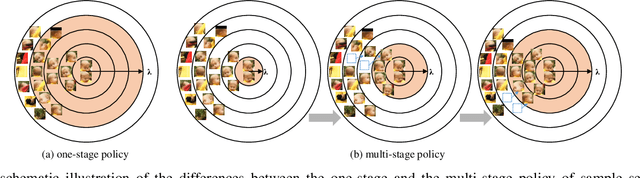

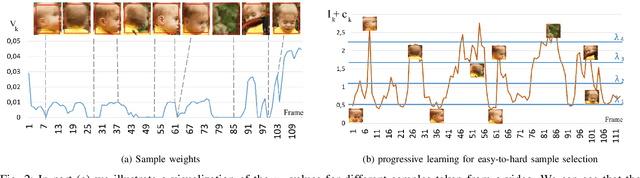
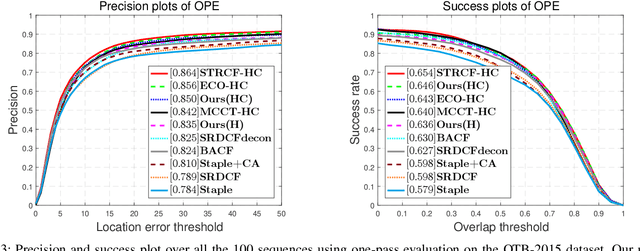
Visual tracking is typically solved as a discriminative learning problem that usually requires high-quality samples for online model adaptation. It is a critical and challenging problem to evaluate the training samples collected from previous predictions and employ sample selection by their quality to train the model. To tackle the above problem, we propose a joint discriminative learning scheme with the progressive multi-stage optimization policy of sample selection for robust visual tracking. The proposed scheme presents a novel time-weighted and detection-guided self-paced learning strategy for easy-to-hard sample selection, which is capable of tolerating relatively large intra-class variations while maintaining inter-class separability. Such a self-paced learning strategy is jointly optimized in conjunction with the discriminative tracking process, resulting in robust tracking results. Experiments on the benchmark datasets demonstrate the effectiveness of the proposed learning framework.
State Distribution-aware Sampling for Deep Q-learning
Apr 23, 2018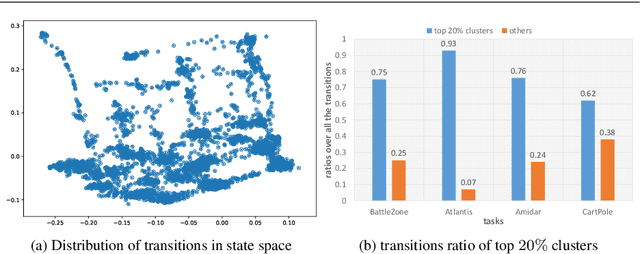
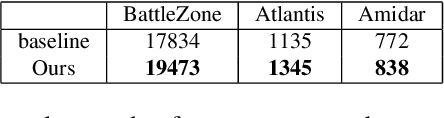
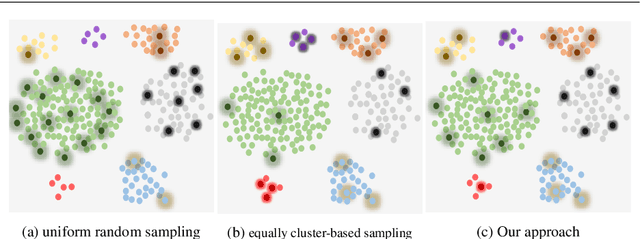
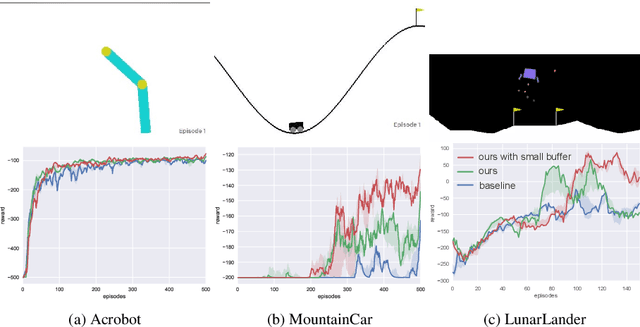
A critical and challenging problem in reinforcement learning is how to learn the state-action value function from the experience replay buffer and simultaneously keep sample efficiency and faster convergence to a high quality solution. In prior works, transitions are uniformly sampled at random from the replay buffer or sampled based on their priority measured by temporal-difference (TD) error. However, these approaches do not fully take into consideration the intrinsic characteristics of transition distribution in the state space and could result in redundant and unnecessary TD updates, slowing down the convergence of the learning procedure. To overcome this problem, we propose a novel state distribution-aware sampling method to balance the replay times for transitions with skew distribution, which takes into account both the occurrence frequencies of transitions and the uncertainty of state-action values. Consequently, our approach could reduce the unnecessary TD updates and increase the TD updates for state-action value with more uncertainty, making the experience replay more effective and efficient. Extensive experiments are conducted on both classic control tasks and Atari 2600 games based on OpenAI gym platform and the experimental results demonstrate the effectiveness of our approach in comparison with the standard DQN approach.