 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultitask Identity-Aware Image Steganography via Minimax Optimization
Jul 13, 2021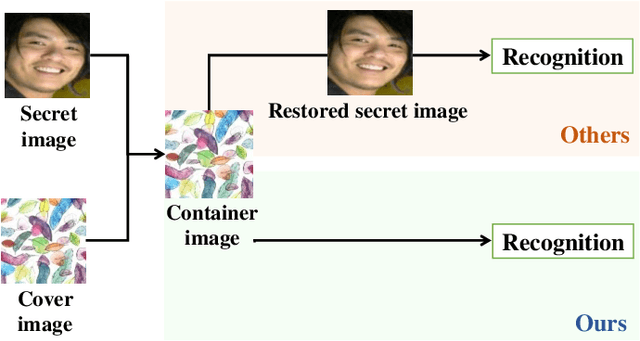

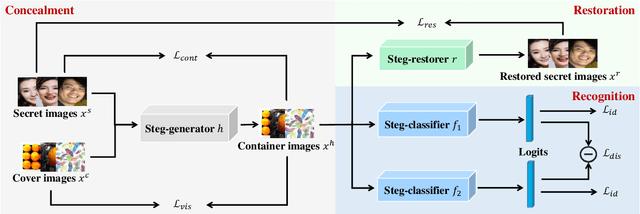
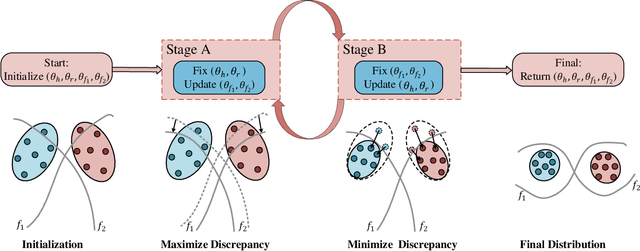
High-capacity image steganography, aimed at concealing a secret image in a cover image, is a technique to preserve sensitive data, e.g., faces and fingerprints. Previous methods focus on the security during transmission and subsequently run a risk of privacy leakage after the restoration of secret images at the receiving end. To address this issue, we propose a framework, called Multitask Identity-Aware Image Steganography (MIAIS), to achieve direct recognition on container images without restoring secret images. The key issue of the direct recognition is to preserve identity information of secret images into container images and make container images look similar to cover images at the same time. Thus, we introduce a simple content loss to preserve the identity information, and design a minimax optimization to deal with the contradictory aspects. We demonstrate that the robustness results can be transferred across different cover datasets. In order to be flexible for the secret image restoration in some cases, we incorporate an optional restoration network into our method, providing a multitask framework. The experiments under the multitask scenario show the effectiveness of our framework compared with other visual information hiding methods and state-of-the-art high-capacity image steganography methods.
Epoch-evolving Gaussian Process Guided Learning
Jun 25, 2020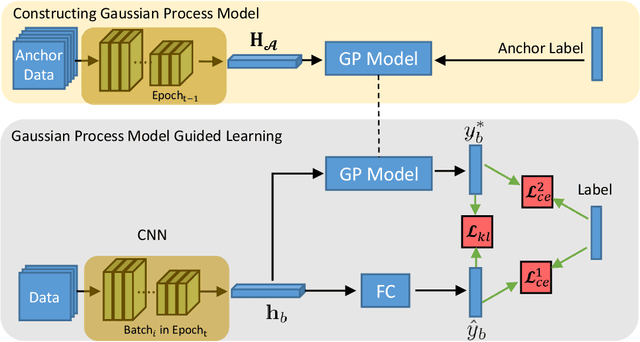
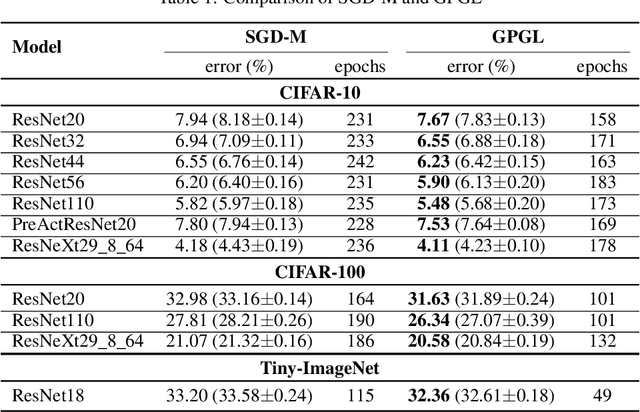
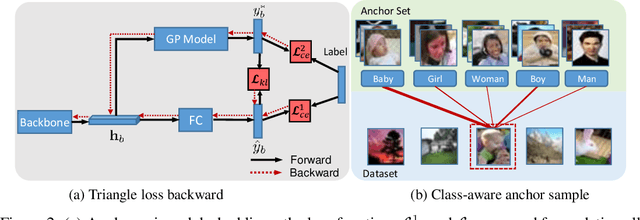
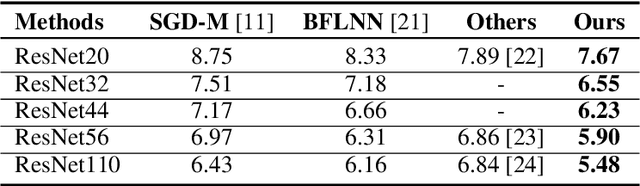
In this paper, we propose a novel learning scheme called epoch-evolving Gaussian Process Guided Learning (GPGL), which aims at characterizing the correlation information between the batch-level distribution and the global data distribution. Such correlation information is encoded as context labels and needs renewal every epoch. With the guidance of the context label and ground truth label, GPGL scheme provides a more efficient optimization through updating the model parameters with a triangle consistency loss. Furthermore, our GPGL scheme can be further generalized and naturally applied to the current deep models, outperforming the existing batch-based state-of-the-art models on mainstream datasets (CIFAR-10, CIFAR-100, and Tiny-ImageNet) remarkably.
How to Train Your Dragon: Tamed Warping Network for Semantic Video Segmentation
May 04, 2020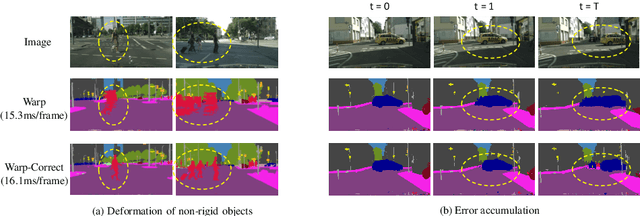
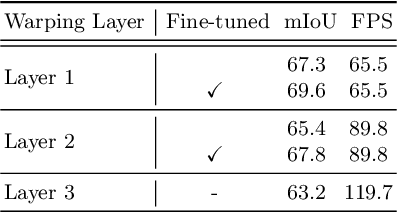
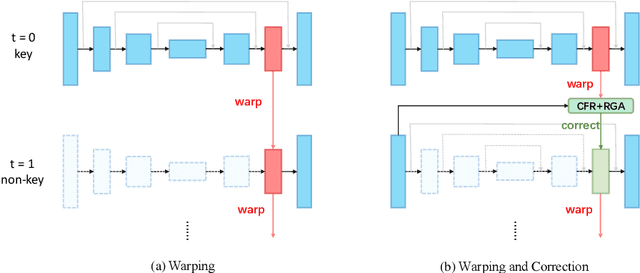
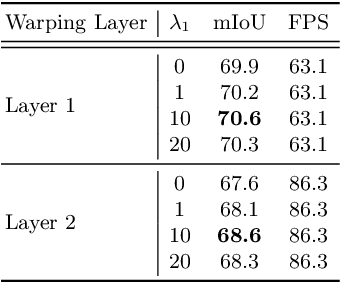
Real-time semantic segmentation on high-resolution videos is challenging due to the strict requirements of speed. Recent approaches have utilized the inter-frame continuity to reduce redundant computation by warping the feature maps across adjacent frames, greatly speeding up the inference phase. However, their accuracy drops significantly owing to the imprecise motion estimation and error accumulation. In this paper, we propose to introduce a simple and effective correction stage right after the warping stage to form a framework named Tamed Warping Network (TWNet), aiming to improve the accuracy and robustness of warping-based models. The experimental results on the Cityscapes dataset show that with the correction, the accuracy (mIoU) significantly increases from 67.3% to 71.6%, and the speed edges down from 65.5 FPS to 61.8 FPS. For non-rigid categories such as "human" and "object", the improvements of IoU are even higher than 18 percentage points.