 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdma-GAN: Attribute-Driven Memory Augmented GANs for Text-to-Image Generation
Sep 28, 2022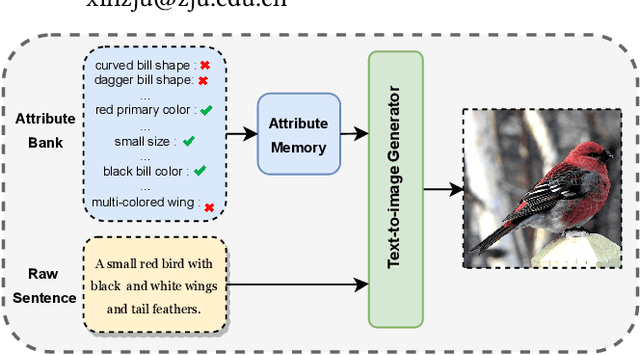
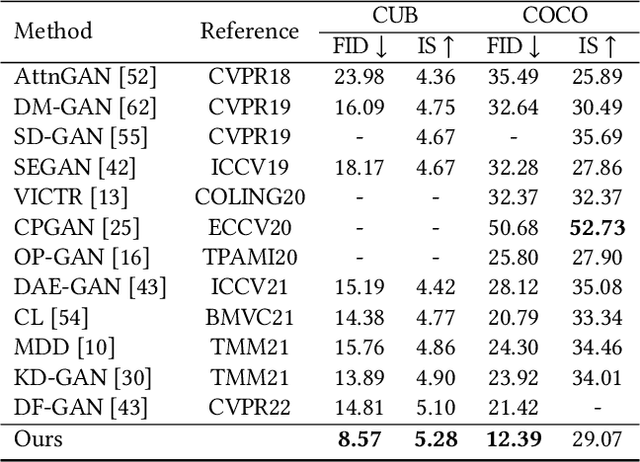

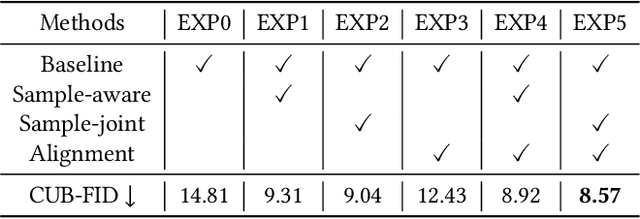
As a challenging task, text-to-image generation aims to generate photo-realistic and semantically consistent images according to the given text descriptions. Existing methods mainly extract the text information from only one sentence to represent an image and the text representation effects the quality of the generated image well. However, directly utilizing the limited information in one sentence misses some key attribute descriptions, which are the crucial factors to describe an image accurately. To alleviate the above problem, we propose an effective text representation method with the complements of attribute information. Firstly, we construct an attribute memory to jointly control the text-to-image generation with sentence input. Secondly, we explore two update mechanisms, sample-aware and sample-joint mechanisms, to dynamically optimize a generalized attribute memory. Furthermore, we design an attribute-sentence-joint conditional generator learning scheme to align the feature embeddings among multiple representations, which promotes the cross-modal network training. Experimental results illustrate that the proposed method obtains substantial performance improvements on both the CUB (FID from 14.81 to 8.57) and COCO (FID from 21.42 to 12.39) datasets.
Multitask Identity-Aware Image Steganography via Minimax Optimization
Jul 13, 2021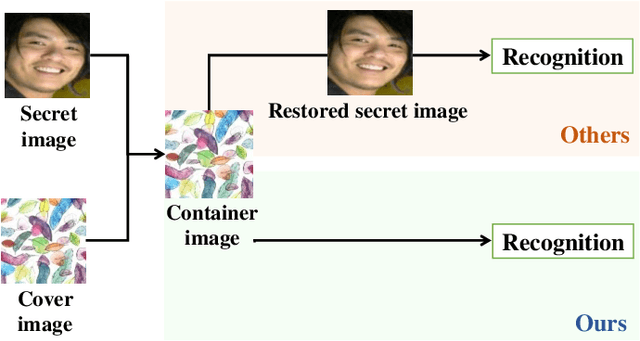

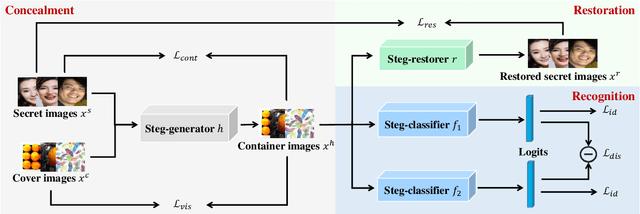
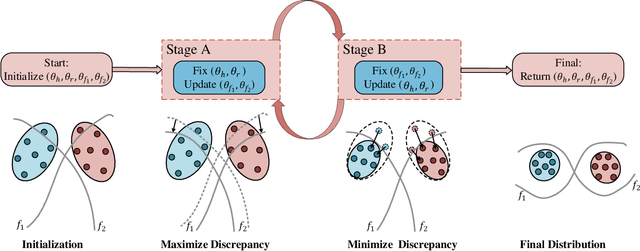
High-capacity image steganography, aimed at concealing a secret image in a cover image, is a technique to preserve sensitive data, e.g., faces and fingerprints. Previous methods focus on the security during transmission and subsequently run a risk of privacy leakage after the restoration of secret images at the receiving end. To address this issue, we propose a framework, called Multitask Identity-Aware Image Steganography (MIAIS), to achieve direct recognition on container images without restoring secret images. The key issue of the direct recognition is to preserve identity information of secret images into container images and make container images look similar to cover images at the same time. Thus, we introduce a simple content loss to preserve the identity information, and design a minimax optimization to deal with the contradictory aspects. We demonstrate that the robustness results can be transferred across different cover datasets. In order to be flexible for the secret image restoration in some cases, we incorporate an optional restoration network into our method, providing a multitask framework. The experiments under the multitask scenario show the effectiveness of our framework compared with other visual information hiding methods and state-of-the-art high-capacity image steganography methods.