 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdma-GAN: Attribute-Driven Memory Augmented GANs for Text-to-Image Generation
Sep 28, 2022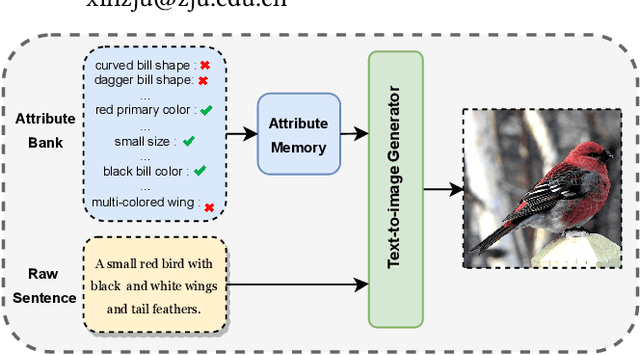
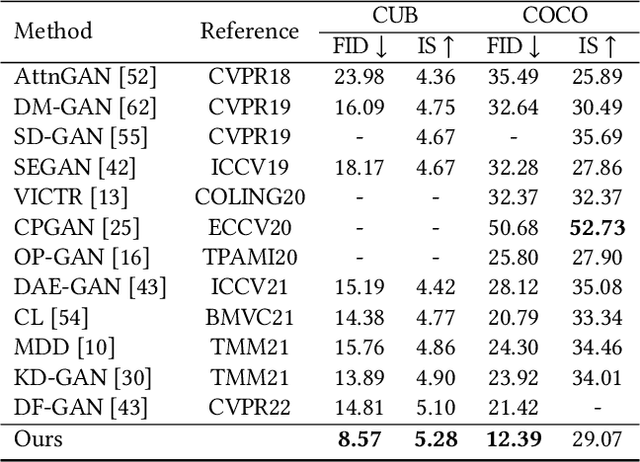

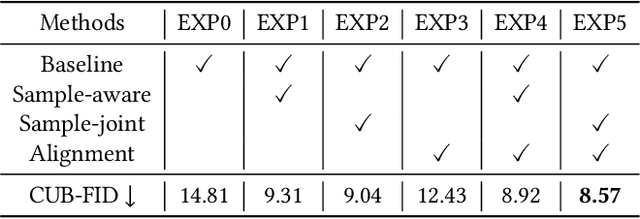
As a challenging task, text-to-image generation aims to generate photo-realistic and semantically consistent images according to the given text descriptions. Existing methods mainly extract the text information from only one sentence to represent an image and the text representation effects the quality of the generated image well. However, directly utilizing the limited information in one sentence misses some key attribute descriptions, which are the crucial factors to describe an image accurately. To alleviate the above problem, we propose an effective text representation method with the complements of attribute information. Firstly, we construct an attribute memory to jointly control the text-to-image generation with sentence input. Secondly, we explore two update mechanisms, sample-aware and sample-joint mechanisms, to dynamically optimize a generalized attribute memory. Furthermore, we design an attribute-sentence-joint conditional generator learning scheme to align the feature embeddings among multiple representations, which promotes the cross-modal network training. Experimental results illustrate that the proposed method obtains substantial performance improvements on both the CUB (FID from 14.81 to 8.57) and COCO (FID from 21.42 to 12.39) datasets.
F3A-GAN: Facial Flow for Face Animation with Generative Adversarial Networks
May 13, 2022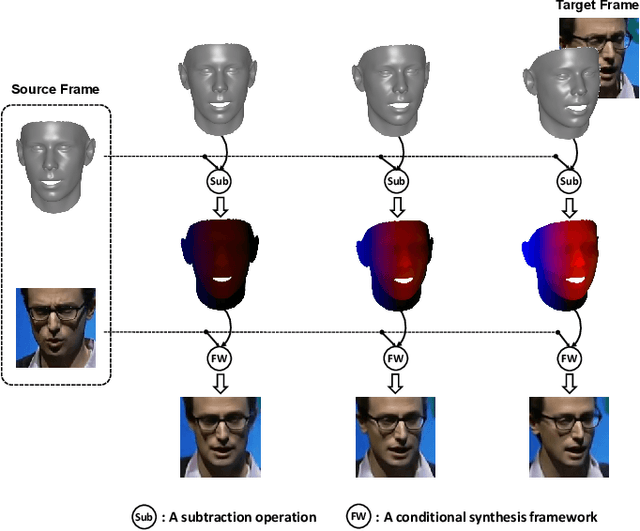



Formulated as a conditional generation problem, face animation aims at synthesizing continuous face images from a single source image driven by a set of conditional face motion. Previous works mainly model the face motion as conditions with 1D or 2D representation (e.g., action units, emotion codes, landmark), which often leads to low-quality results in some complicated scenarios such as continuous generation and largepose transformation. To tackle this problem, the conditions are supposed to meet two requirements, i.e., motion information preserving and geometric continuity. To this end, we propose a novel representation based on a 3D geometric flow, termed facial flow, to represent the natural motion of the human face at any pose. Compared with other previous conditions, the proposed facial flow well controls the continuous changes to the face. After that, in order to utilize the facial flow for face editing, we build a synthesis framework generating continuous images with conditional facial flows. To fully take advantage of the motion information of facial flows, a hierarchical conditional framework is designed to combine the extracted multi-scale appearance features from images and motion features from flows in a hierarchical manner. The framework then decodes multiple fused features back to images progressively. Experimental results demonstrate the effectiveness of our method compared to other state-of-the-art methods.
D3T-GAN: Data-Dependent Domain Transfer GANs for Few-shot Image Generation
May 12, 2022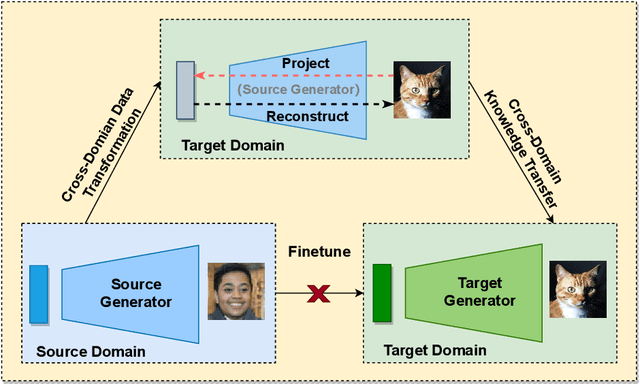
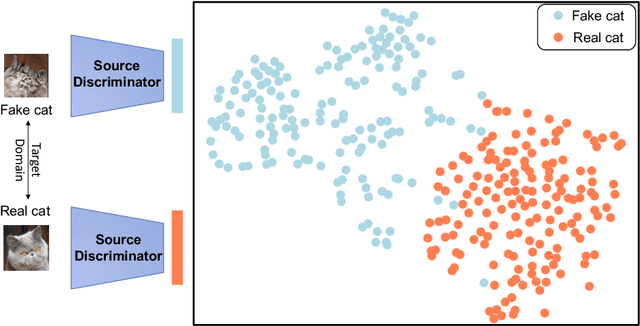
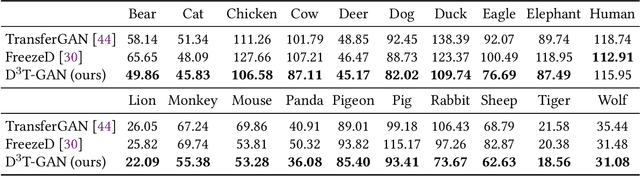
As an important and challenging problem, few-shot image generation aims at generating realistic images through training a GAN model given few samples. A typical solution for few-shot generation is to transfer a well-trained GAN model from a data-rich source domain to the data-deficient target domain. In this paper, we propose a novel self-supervised transfer scheme termed D3T-GAN, addressing the cross-domain GANs transfer in few-shot image generation. Specifically, we design two individual strategies to transfer knowledge between generators and discriminators, respectively. To transfer knowledge between generators, we conduct a data-dependent transformation, which projects and reconstructs the target samples into the source generator space. Then, we perform knowledge transfer from transformed samples to generated samples. To transfer knowledge between discriminators, we design a multi-level discriminant knowledge distillation from the source discriminator to the target discriminator on both the real and fake samples. Extensive experiments show that our method improve the quality of generated images and achieves the state-of-the-art FID scores on commonly used datasets.
A Comprehensive Survey on Data-Efficient GANs in Image Generation
Apr 18, 2022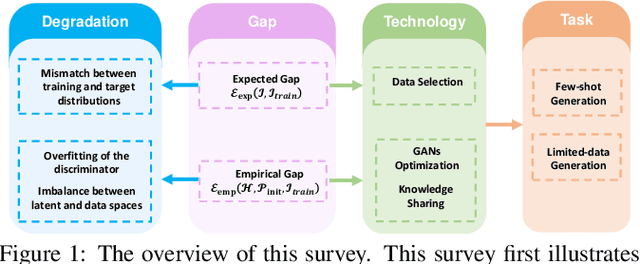
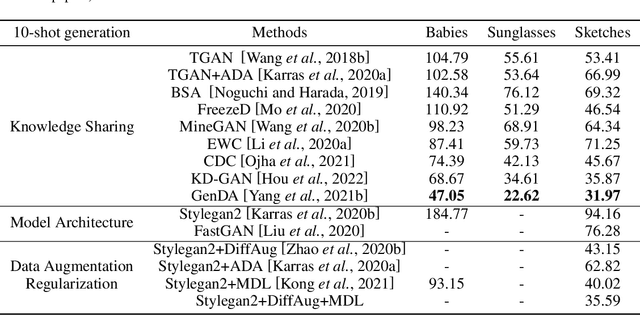
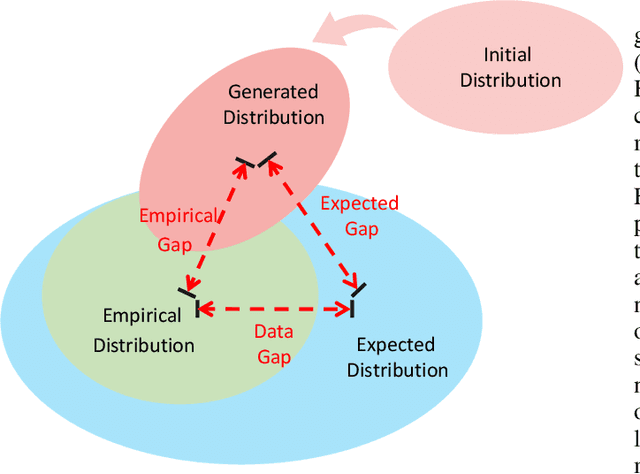
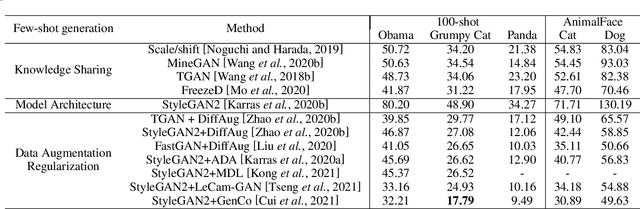
Generative Adversarial Networks (GANs) have achieved remarkable achievements in image synthesis. These successes of GANs rely on large scale datasets, requiring too much cost. With limited training data, how to stable the training process of GANs and generate realistic images have attracted more attention. The challenges of Data-Efficient GANs (DE-GANs) mainly arise from three aspects: (i) Mismatch Between Training and Target Distributions, (ii) Overfitting of the Discriminator, and (iii) Imbalance Between Latent and Data Spaces. Although many augmentation and pre-training strategies have been proposed to alleviate these issues, there lacks a systematic survey to summarize the properties, challenges, and solutions of DE-GANs. In this paper, we revisit and define DE-GANs from the perspective of distribution optimization. We conclude and analyze the challenges of DE-GANs. Meanwhile, we propose a taxonomy, which classifies the existing methods into three categories: Data Selection, GANs Optimization, and Knowledge Sharing. Last but not the least, we attempt to highlight the current problems and the future directions.
MGH: Metadata Guided Hypergraph Modeling for Unsupervised Person Re-identification
Oct 12, 2021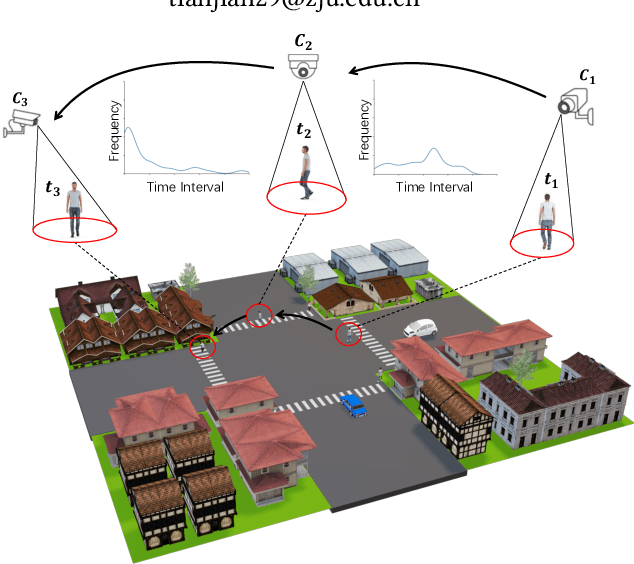

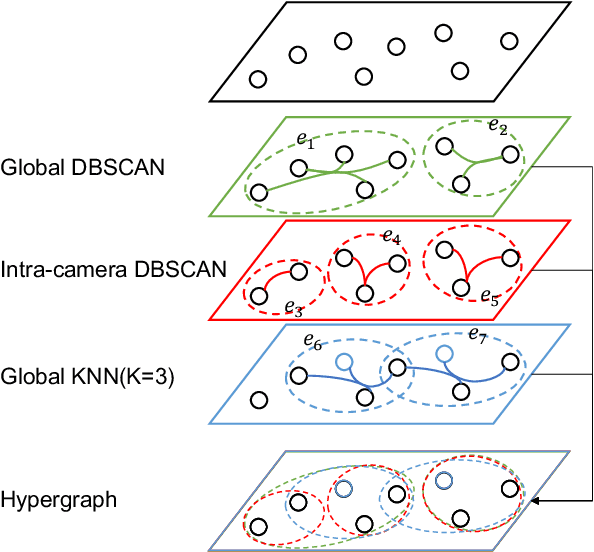
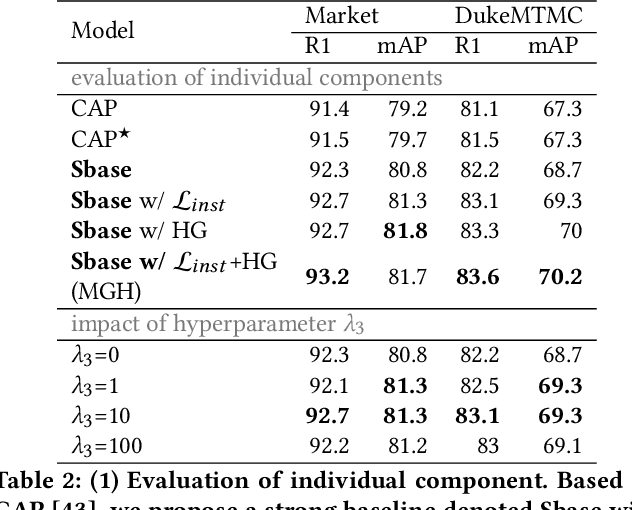
As a challenging task, unsupervised person ReID aims to match the same identity with query images which does not require any labeled information. In general, most existing approaches focus on the visual cues only, leaving potentially valuable auxiliary metadata information (e.g., spatio-temporal context) unexplored. In the real world, such metadata is normally available alongside captured images, and thus plays an important role in separating several hard ReID matches. With this motivation in mind, we propose~\textbf{MGH}, a novel unsupervised person ReID approach that uses meta information to construct a hypergraph for feature learning and label refinement. In principle, the hypergraph is composed of camera-topology-aware hyperedges, which can model the heterogeneous data correlations across cameras. Taking advantage of label propagation on the hypergraph, the proposed approach is able to effectively refine the ReID results, such as correcting the wrong labels or smoothing the noisy labels. Given the refined results, We further present a memory-based listwise loss to directly optimize the average precision in an approximate manner. Extensive experiments on three benchmarks demonstrate the effectiveness of the proposed approach against the state-of-the-art.
Extend the FFmpeg Framework to Analyze Media Content
Mar 05, 2021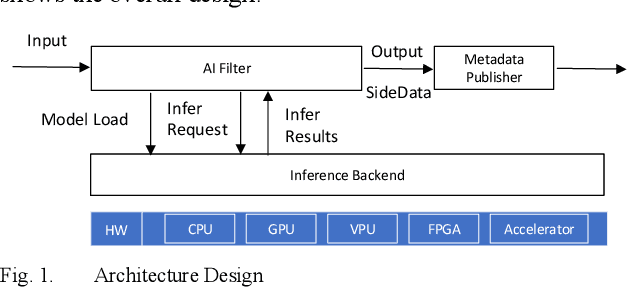
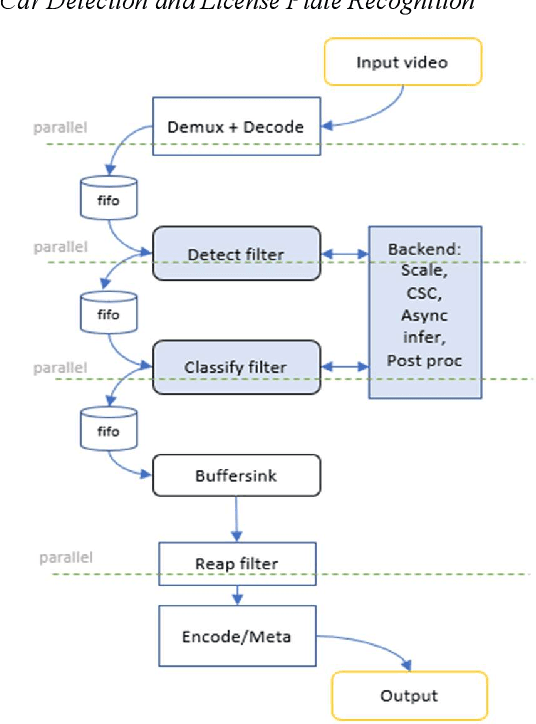

This paper introduces a new set of video analytics plugins developed for the FFmpeg framework. Multimedia applications that increasingly utilize the FFmpeg media features for its comprehensive media encoding, decoding, muxing, and demuxing capabilities can now additionally analyze the video content based on AI models. The plugins are thread optimized for best performance overcoming certain FFmpeg threading limitations. The plugins utilize the Intel OpenVINO Toolkit inference engine as the backend. The analytics workloads are accelerated on different platforms such as CPU, GPU, FPGA or specialized analytics accelerators. With our reference implementation, the feature of OpenVINO as inference backend has been pushed into FFmpeg mainstream repository. We plan to submit more patches later.
Semantic Neighborhood-Aware Deep Facial Expression Recognition
Apr 27, 2020
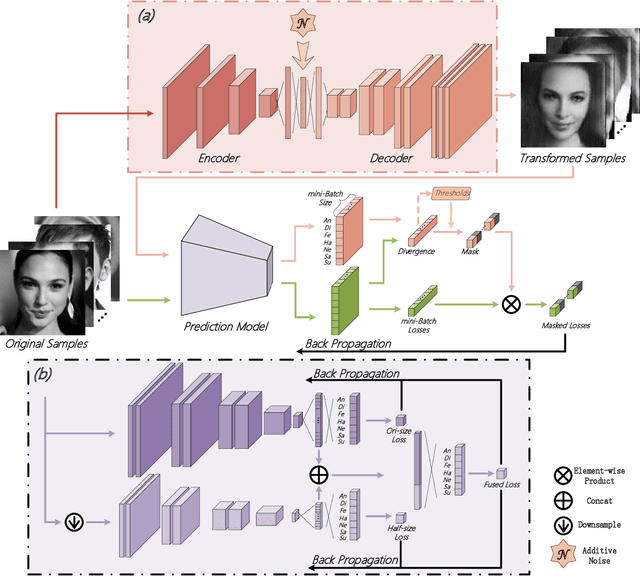

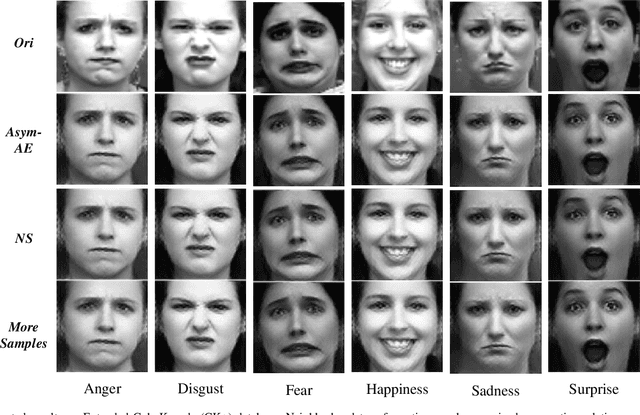
Different from many other attributes, facial expression can change in a continuous way, and therefore, a slight semantic change of input should also lead to the output fluctuation limited in a small scale. This consistency is important. However, current Facial Expression Recognition (FER) datasets may have the extreme imbalance problem, as well as the lack of data and the excessive amounts of noise, hindering this consistency and leading to a performance decreasing when testing. In this paper, we not only consider the prediction accuracy on sample points, but also take the neighborhood smoothness of them into consideration, focusing on the stability of the output with respect to slight semantic perturbations of the input. A novel method is proposed to formulate semantic perturbation and select unreliable samples during training, reducing the bad effect of them. Experiments show the effectiveness of the proposed method and state-of-the-art results are reported, getting closer to an upper limit than the state-of-the-art methods by a factor of 30\% in AffectNet, the largest in-the-wild FER database by now.