 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExecutable Agentic Memory for GUI Agent
May 12, 2026Modern GUI agents typically rely on a model-centric and step-wise interaction paradigm, where LLMs must re-interpret the UI and re-decide actions at every screen, which is fragile in long-horizon tasks. In this paper, we propose Executable Agentic Memory (EAM), a structured Knowledge Graph (KG) that shifts GUI planning from free-form generation to a robust retrieval-and-execution process. Our approach includes a sample-efficient memory construction pipeline using state-aware DFS and action-group mining to compress multi-step routines. To ensure efficient planning, we introduce a value-guided graph search where a lightweight Q-function model steers Monte Carlo Tree Search (MCTS) over the KG. We theoretically establish bias-consistency for the Q-model and derive sample complexity bounds for path recovery. Empirically, EAM outperforms state-of-the-art baselines like UI-TARS-7B by up to $19.6\%$ on AndroidWorld, while reducing token costs $6\times$ relative to GPT-4o. With a $2.8$s average latency, EAM enables reliable, quick, and long-horizon GUI automation.
MANA: Towards Efficient Mobile Ad Detection via Multimodal Agentic UI Navigation
Mar 20, 2026Mobile advertising dominates app monetization but introduces risks ranging from intrusive user experience to malware delivery. Existing detection methods rely either on static analysis, which misses runtime behaviors, or on heuristic UI exploration, which struggles with sparse and obfuscated ads. In this paper, we present MANA, the first agentic multimodal reasoning framework for mobile ad detection. MANA integrates static, visual, temporal, and experiential signals into a reasoning-guided navigation strategy that determines not only how to traverse interfaces but also where to focus, enabling efficient and robust exploration. We implement and evaluate MANA on commercial smartphones over 200 apps, achieving state-of-the-art accuracy and efficiency. Compared to baselines, it improves detection accuracy by 30.5%-56.3% and reduces exploration steps by 29.7%-63.3%. Case studies further demonstrate its ability to uncover obfuscated and malicious ads, underscoring its practicality for mobile ad auditing and its potential for broader runtime UI analysis (e.g., permission abuse). Code and dataset are available at https://github.com/MANA-2026/MANA.
Wideband RF Radiance Field Modeling Using Frequency-embedded 3D Gaussian Splatting
May 27, 2025This paper presents an innovative frequency-embedded 3D Gaussian splatting (3DGS) algorithm for wideband radio-frequency (RF) radiance field modeling, offering an advancement over the existing works limited to single-frequency modeling. Grounded in fundamental physics, we uncover the complex relationship between EM wave propagation behaviors and RF frequencies. Inspired by this, we design an EM feature network with attenuation and radiance modules to learn the complex relationships between RF frequencies and the key properties of each 3D Gaussian, specifically the attenuation factor and RF signal intensity. By training the frequency-embedded 3DGS model, we can efficiently reconstruct RF radiance fields at arbitrary unknown frequencies within a given 3D environment. Finally, we propose a large-scale power angular spectrum (PAS) dataset containing 50000 samples ranging from 1 to 100 GHz in 6 indoor environments, and conduct extensive experiments to verify the effectiveness of our method. Our approach achieves an average Structural Similarity Index Measure (SSIM) up to 0.72, and a significant improvement up to 17.8% compared to the current state-of-the-art (SOTA) methods trained on individual test frequencies. Additionally, our method achieves an SSIM of 0.70 without prior training on these frequencies, which represents only a 2.8% performance drop compared to models trained with full PAS data. This demonstrates our model's capability to estimate PAS at unknown frequencies. For related code and datasets, please refer to https://github.com/sim-2-real/Wideband3DGS.
Enabling Cardiac Monitoring using In-ear Ballistocardiogram on COTS Wireless Earbuds
Jan 12, 2025The human ear offers a unique opportunity for cardiac monitoring due to its physiological and practical advantages. However, existing earable solutions require additional hardware and complex processing, posing challenges for commercial True Wireless Stereo (TWS) earbuds which are limited by their form factor and resources. In this paper, we propose TWSCardio, a novel system that repurposes the IMU sensors in TWS earbuds for cardiac monitoring. Our key finding is that these sensors can capture in-ear ballistocardiogram (BCG) signals. TWSCardio reuses the unstable Bluetooth channel to stream the IMU data to a smartphone for BCG processing. It incorporates a signal enhancement framework to address issues related to missing data and low sampling rate, while mitigating motion artifacts by fusing multi-axis information. Furthermore, it employs a region-focused signal reconstruction method to translate the multi-axis in-ear BCG signals into fine-grained seismocardiogram (SCG) signals. We have implemented TWSCardio as an efficient real-time app. Our experiments on 100 subjects verify that TWSCardio can accurately reconstruct cardiac signals while showing resilience to motion artifacts, missing data, and low sampling rates. Our case studies further demonstrate that TWSCardio can support diverse cardiac monitoring applications.
Referring Expression Comprehension Using Language Adaptive Inference
Jun 06, 2023



Different from universal object detection, referring expression comprehension (REC) aims to locate specific objects referred to by natural language expressions. The expression provides high-level concepts of relevant visual and contextual patterns, which vary significantly with different expressions and account for only a few of those encoded in the REC model. This leads us to a question: do we really need the entire network with a fixed structure for various referring expressions? Ideally, given an expression, only expression-relevant components of the REC model are required. These components should be small in number as each expression only contains very few visual and contextual clues. This paper explores the adaptation between expressions and REC models for dynamic inference. Concretely, we propose a neat yet efficient framework named Language Adaptive Dynamic Subnets (LADS), which can extract language-adaptive subnets from the REC model conditioned on the referring expressions. By using the compact subnet, the inference can be more economical and efficient. Extensive experiments on RefCOCO, RefCOCO+, RefCOCOg, and Referit show that the proposed method achieves faster inference speed and higher accuracy against state-of-the-art approaches.
Referring Expression Comprehension via Cross-Level Multi-Modal Fusion
Apr 21, 2022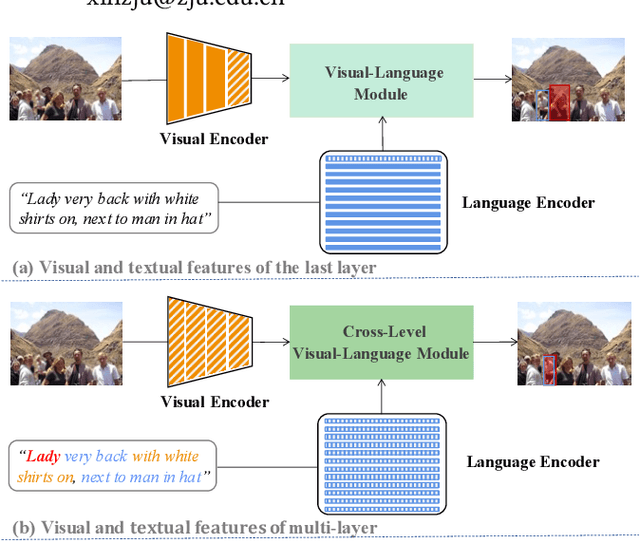
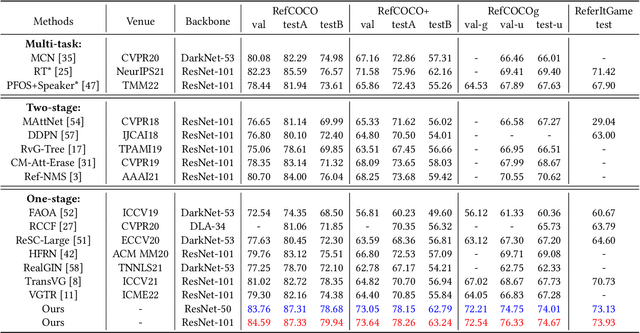


As an important and challenging problem in vision-language tasks, referring expression comprehension (REC) aims to localize the target object specified by a given referring expression. Recently, most of the state-of-the-art REC methods mainly focus on multi-modal fusion while overlooking the inherent hierarchical information contained in visual and language encoders. Considering that REC requires visual and textual hierarchical information for accurate target localization, and encoders inherently extract features in a hierarchical fashion, we propose to effectively utilize the rich hierarchical information contained in different layers of visual and language encoders. To this end, we design a Cross-level Multi-modal Fusion (CMF) framework, which gradually integrates visual and textual features of multi-layer through intra- and inter-modal. Experimental results on RefCOCO, RefCOCO+, RefCOCOg, and ReferItGame datasets demonstrate the proposed framework achieves significant performance improvements over state-of-the-art methods.
Memory Efficient Class-Incremental Learning for Image Classification
Aug 04, 2020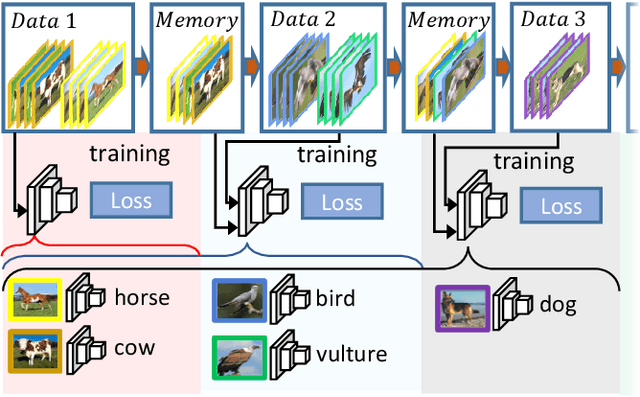

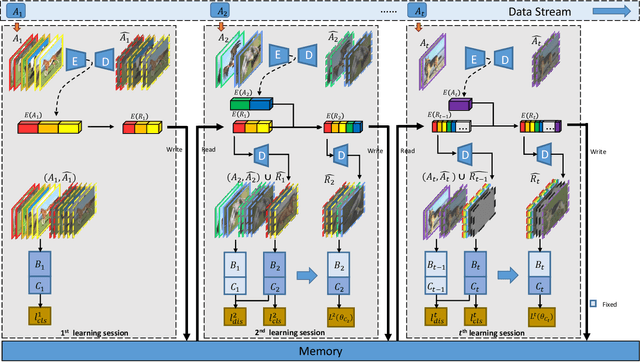

With the memory-resource-limited constraints, class-incremental learning (CIL) usually suffers from the "catastrophic forgetting" problem when updating the joint classification model on the arrival of newly added classes. To cope with the forgetting problem, many CIL methods transfer the knowledge of old classes by preserving some exemplar samples into the size-constrained memory buffer. To utilize the memory buffer more efficiently, we propose to keep more auxiliary low-fidelity exemplar samples rather than the original real high-fidelity exemplar samples. Such memory-efficient exemplar preserving scheme make the old-class knowledge transfer more effective. However, the low-fidelity exemplar samples are often distributed in a different domain away from that of the original exemplar samples, that is, a domain shift. To alleviate this problem, we propose a duplet learning scheme that seeks to construct domain-compatible feature extractors and classifiers, which greatly narrows down the above domain gap. As a result, these low-fidelity auxiliary exemplar samples have the ability to moderately replace the original exemplar samples with a lower memory cost. In addition, we present a robust classifier adaptation scheme, which further refines the biased classifier (learned with the samples containing distillation label knowledge about old classes) with the help of the samples of pure true class labels. Experimental results demonstrate the effectiveness of this work against the state-of-the-art approaches. We will release the code, baselines, and training statistics for all models to facilitate future research.
What and Where: Learn to Plug Adapters via NAS for Multi-Domain Learning
Jul 24, 2020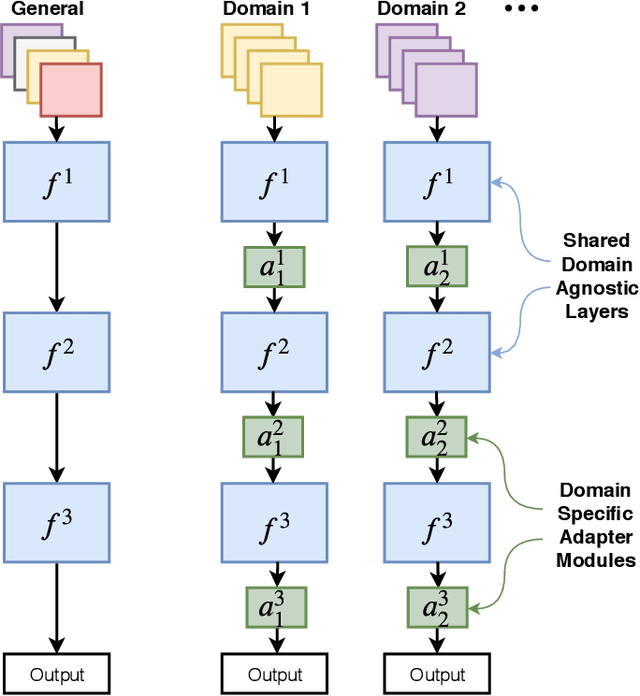
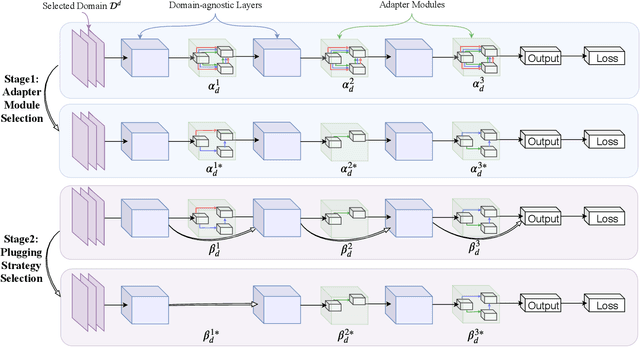
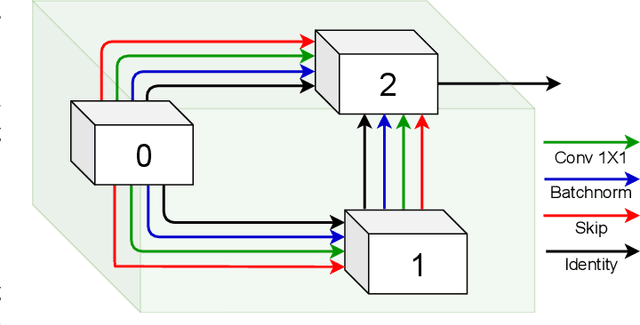
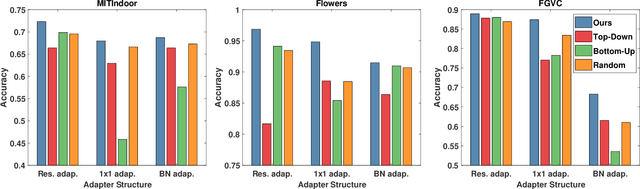
As an important and challenging problem, multi-domain learning (MDL) typically seeks for a set of effective lightweight domain-specific adapter modules plugged into a common domain-agnostic network. Usually, existing ways of adapter plugging and structure design are handcrafted and fixed for all domains before model learning, resulting in the learning inflexibility and computational intensiveness. With this motivation, we propose to learn a data-driven adapter plugging strategy with Neural Architecture Search (NAS), which automatically determines where to plug for those adapter modules. Furthermore, we propose a NAS-adapter module for adapter structure design in a NAS-driven learning scheme, which automatically discovers effective adapter module structures for different domains. Experimental results demonstrate the effectiveness of our MDL model against existing approaches under the conditions of comparable performance. We will release the code, baselines, and training statistics for all models to facilitate future research.
Few-Shot Class-Incremental Learning via Feature Space Composition
Jun 28, 2020
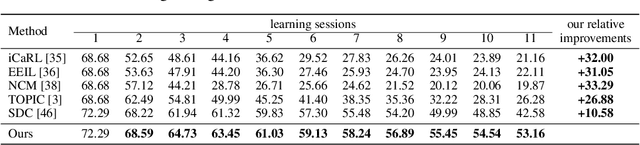


As a challenging problem in machine learning, few-shot class-incremental learning asynchronously learns a sequence of tasks, acquiring the new knowledge from new tasks (with limited new samples) while keeping the learned knowledge from previous tasks (with old samples discarded). In general, existing approaches resort to one unified feature space for balancing old-knowledge preserving and new-knowledge adaptation. With a limited embedding capacity of feature representation, the unified feature space often makes the learner suffer from semantic drift or overfitting as the number of tasks increases. With this motivation, we propose a novel few-shot class-incremental learning pipeline based on a composite representation space, which makes old-knowledge preserving and new-knowledge adaptation mutually compatible by feature space composition (enlarging the embedding capacity). The composite representation space is generated by integrating two space components (i.e. stable base knowledge space and dynamic lifelong-learning knowledge space) in terms of distance metric construction. With the composite feature space, our method performs remarkably well on the CUB200 and CIFAR100 datasets, outperforming the state-of-the-art algorithms by 10.58% and 14.65% respectively.
Semantic Neighborhood-Aware Deep Facial Expression Recognition
Apr 27, 2020
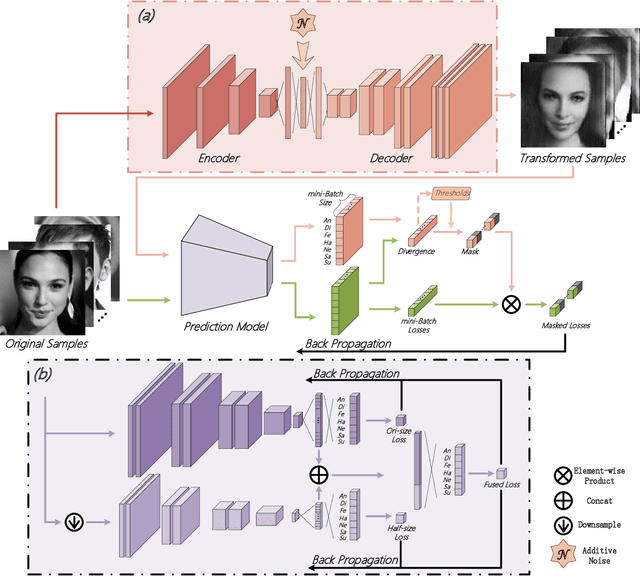

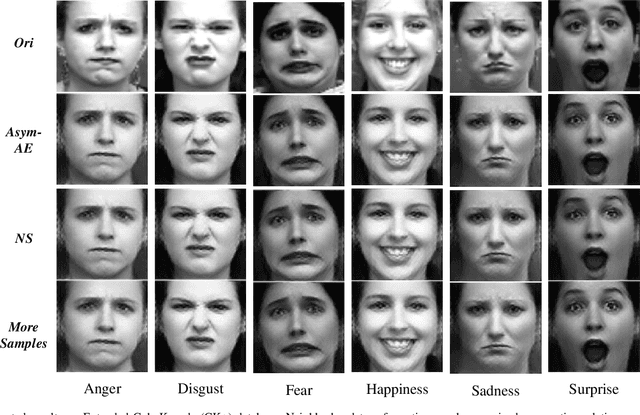
Different from many other attributes, facial expression can change in a continuous way, and therefore, a slight semantic change of input should also lead to the output fluctuation limited in a small scale. This consistency is important. However, current Facial Expression Recognition (FER) datasets may have the extreme imbalance problem, as well as the lack of data and the excessive amounts of noise, hindering this consistency and leading to a performance decreasing when testing. In this paper, we not only consider the prediction accuracy on sample points, but also take the neighborhood smoothness of them into consideration, focusing on the stability of the output with respect to slight semantic perturbations of the input. A novel method is proposed to formulate semantic perturbation and select unreliable samples during training, reducing the bad effect of them. Experiments show the effectiveness of the proposed method and state-of-the-art results are reported, getting closer to an upper limit than the state-of-the-art methods by a factor of 30\% in AffectNet, the largest in-the-wild FER database by now.