 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval is Cheap, Show Me the Code: Executable Multi-Hop Reasoning for Retrieval-Augmented Generation
May 13, 2026Retrieval-Augmented Generation (RAG) has become a standard approach for knowledge-intensive question answering, but existing systems remain brittle on multi-hop questions, where solving the task requires chaining multiple retrieval and reasoning steps. Key challenges are that current methods represent reasoning through free-form natural language, where intermediate states are implicit, retrieval queries can drift from intended entities, and errors are detected by the same model that produces them making self-reflection an unreliable, ungrounded signal. We observe that multi-hop question answering is a typical form of step-by-step computation, and that this structured process aligns closely with how code-specialized language models are trained to operate. Motivated by this, we introduce \pyrag, a framework that reformulates multi-hop RAG as program synthesis and execution. Instead of free-form reasoning trajectories, \pyrag represents the reasoning process as an executable Python program over retrieval and QA tools, exposing intermediate states as variables, producing deterministic feedback through execution, and yielding an inspectable trace of the entire reasoning process. This formulation further enables compiler-grounded self-repair and execution-driven adaptive retrieval without any additional training. Experiments on five QA benchmarks (PopQA, HotpotQA, 2WikiMultihopQA, MuSiQue, and Bamboogle) show that \pyrag consistently outperforms strong baselines under both training-free and RL-trained settings, with especially large gains on compositional multi-hop datasets. Our code, data and models are publicly available at https://github.com/GasolSun36/PyRAG.
SPA: A Simple but Tough-to-Beat Baseline for Knowledge Injection
Mar 23, 2026While large language models (LLMs) are pretrained on massive amounts of data, their knowledge coverage remains incomplete in specialized, data-scarce domains, motivating extensive efforts to study synthetic data generation for knowledge injection. We propose SPA (Scaling Prompt-engineered Augmentation), a simple but tough-to-beat baseline that uses a small set of carefully designed prompts to generate large-scale synthetic data for knowledge injection. Through systematic comparisons, we find that SPA outperforms several strong baselines. Furthermore, we identify two key limitations of prior approaches: (1) while RL-based methods may improve the token efficiency of LLM-based data augmentation at small scale, they suffer from diversity collapse as data scales, leading to diminishing returns; and (2) while multi-stage prompting may outperform simple augmentation methods, their advantages can disappear after careful prompt tuning. Our results suggest that, for knowledge injection, careful prompt design combined with straightforward large-scale augmentation can be surprisingly effective, and we hope SPA can serve as a strong baseline for future studies in this area. Our code is available at https://github.com/Tangkexian/SPA.
TaSR-RAG: Taxonomy-guided Structured Reasoning for Retrieval-Augmented Generation
Mar 10, 2026Retrieval-Augmented Generation (RAG) helps large language models (LLMs) answer knowledge-intensive and time-sensitive questions by conditioning generation on external evidence. However, most RAG systems still retrieve unstructured chunks and rely on one-shot generation, which often yields redundant context, low information density, and brittle multi-hop reasoning. While structured RAG pipelines can improve grounding, they typically require costly and error-prone graph construction or impose rigid entity-centric structures that do not align with the query's reasoning chain. We propose \textsc{TaSR-RAG}, a taxonomy-guided structured reasoning framework for evidence selection. We represent both queries and documents as relational triples, and constrain entity semantics with a lightweight two-level taxonomy to balance generalization and precision. Given a complex question, \textsc{TaSR-RAG} decomposes it into an ordered sequence of triple sub-queries with explicit latent variables, then performs step-wise evidence selection via hybrid triple matching that combines semantic similarity over raw triples with structural consistency over typed triples. By maintaining an explicit entity binding table across steps, \textsc{TaSR-RAG} resolves intermediate variables and reduces entity conflation without explicit graph construction or exhaustive search. Experiments on multiple multi-hop question answering benchmarks show that \textsc{TaSR-RAG} consistently outperforms strong RAG and structured-RAG baselines by up to 14\%, while producing clearer evidence attribution and more faithful reasoning traces.
Any Model, Any Place, Any Time: Get Remote Sensing Foundation Model Embeddings On Demand
Feb 27, 2026The remote sensing community is witnessing a rapid growth of foundation models, which provide powerful embeddings for a wide range of downstream tasks. However, practical adoption and fair comparison remain challenging due to substantial heterogeneity in model release formats, platforms and interfaces, and input data specifications. These inconsistencies significantly increase the cost of obtaining, using, and benchmarking embeddings across models. To address this issue, we propose rs-embed, a Python library that offers a unified, region of interst (ROI) centric interface: with a single line of code, users can retrieve embeddings from any supported model for any location and any time range. The library also provides efficient batch processing to enable large-scale embedding generation and evaluation. The code is available at: https://github.com/cybergis/rs-embed
Uni-Animator: Towards Unified Visual Colorization
Feb 26, 2026We propose Uni-Animator, a novel Diffusion Transformer (DiT)-based framework for unified image and video sketch colorization. Existing sketch colorization methods struggle to unify image and video tasks, suffering from imprecise color transfer with single or multiple references, inadequate preservation of high-frequency physical details, and compromised temporal coherence with motion artifacts in large-motion scenes. To tackle imprecise color transfer, we introduce visual reference enhancement via instance patch embedding, enabling precise alignment and fusion of reference color information. To resolve insufficient physical detail preservation, we design physical detail reinforcement using physical features that effectively capture and retain high-frequency textures. To mitigate motion-induced temporal inconsistency, we propose sketch-based dynamic RoPE encoding that adaptively models motion-aware spatial-temporal dependencies. Extensive experimental results demonstrate that Uni-Animator achieves competitive performance on both image and video sketch colorization, matching that of task-specific methods while unlocking unified cross-domain capabilities with high detail fidelity and robust temporal consistency.
Target noise: A pre-training based neural network initialization for efficient high resolution learning
Feb 06, 2026Weight initialization plays a crucial role in the optimization behavior and convergence efficiency of neural networks. Most existing initialization methods, such as Xavier and Kaiming initializations, rely on random sampling and do not exploit information from the optimization process itself. We propose a simple, yet effective, initialization strategy based on self-supervised pre-training using random noise as the target. Instead of directly training the network from random weights, we first pre-train it to fit random noise, which leads to a structured and non-random parameter configuration. We show that this noise-driven pre-training significantly improves convergence speed in subsequent tasks, without requiring additional data or changes to the network architecture. The proposed method is particularly effective for implicit neural representations (INRs) and Deep Image Prior (DIP)-style networks, which are known to exhibit a strong low-frequency bias during optimization. After noise-based pre-training, the network is able to capture high-frequency components much earlier in training, leading to faster and more stable convergence. Although random noise contains no semantic information, it serves as an effective self-supervised signal (considering its white spectrum nature) for shaping the initialization of neural networks. Overall, this work demonstrates that noise-based pre-training offers a lightweight and general alternative to traditional random initialization, enabling more efficient optimization of deep neural networks.
Dynamic Large Concept Models: Latent Reasoning in an Adaptive Semantic Space
Dec 31, 2025Large Language Models (LLMs) apply uniform computation to all tokens, despite language exhibiting highly non-uniform information density. This token-uniform regime wastes capacity on locally predictable spans while under-allocating computation to semantically critical transitions. We propose $\textbf{Dynamic Large Concept Models (DLCM)}$, a hierarchical language modeling framework that learns semantic boundaries from latent representations and shifts computation from tokens to a compressed concept space where reasoning is more efficient. DLCM discovers variable-length concepts end-to-end without relying on predefined linguistic units. Hierarchical compression fundamentally changes scaling behavior. We introduce the first $\textbf{compression-aware scaling law}$, which disentangles token-level capacity, concept-level reasoning capacity, and compression ratio, enabling principled compute allocation under fixed FLOPs. To stably train this heterogeneous architecture, we further develop a $\textbf{decoupled $μ$P parametrization}$ that supports zero-shot hyperparameter transfer across widths and compression regimes. At a practical setting ($R=4$, corresponding to an average of four tokens per concept), DLCM reallocates roughly one-third of inference compute into a higher-capacity reasoning backbone, achieving a $\textbf{+2.69$\%$ average improvement}$ across 12 zero-shot benchmarks under matched inference FLOPs.
CEMG: Collaborative-Enhanced Multimodal Generative Recommendation
Dec 25, 2025Generative recommendation models often struggle with two key challenges: (1) the superficial integration of collaborative signals, and (2) the decoupled fusion of multimodal features. These limitations hinder the creation of a truly holistic item representation. To overcome this, we propose CEMG, a novel Collaborative-Enhaned Multimodal Generative Recommendation framework. Our approach features a Multimodal Fusion Layer that dynamically integrates visual and textual features under the guidance of collaborative signals. Subsequently, a Unified Modality Tokenization stage employs a Residual Quantization VAE (RQ-VAE) to convert this fused representation into discrete semantic codes. Finally, in the End-to-End Generative Recommendation stage, a large language model is fine-tuned to autoregressively generate these item codes. Extensive experiments demonstrate that CEMG significantly outperforms state-of-the-art baselines.
When Bias Pretends to Be Truth: How Spurious Correlations Undermine Hallucination Detection in LLMs
Nov 10, 2025Despite substantial advances, large language models (LLMs) continue to exhibit hallucinations, generating plausible yet incorrect responses. In this paper, we highlight a critical yet previously underexplored class of hallucinations driven by spurious correlations -- superficial but statistically prominent associations between features (e.g., surnames) and attributes (e.g., nationality) present in the training data. We demonstrate that these spurious correlations induce hallucinations that are confidently generated, immune to model scaling, evade current detection methods, and persist even after refusal fine-tuning. Through systematically controlled synthetic experiments and empirical evaluations on state-of-the-art open-source and proprietary LLMs (including GPT-5), we show that existing hallucination detection methods, such as confidence-based filtering and inner-state probing, fundamentally fail in the presence of spurious correlations. Our theoretical analysis further elucidates why these statistical biases intrinsically undermine confidence-based detection techniques. Our findings thus emphasize the urgent need for new approaches explicitly designed to address hallucinations caused by spurious correlations.
Learning to Decide with Just Enough: Information-Theoretic Context Summarization for CDMPs
Oct 02, 2025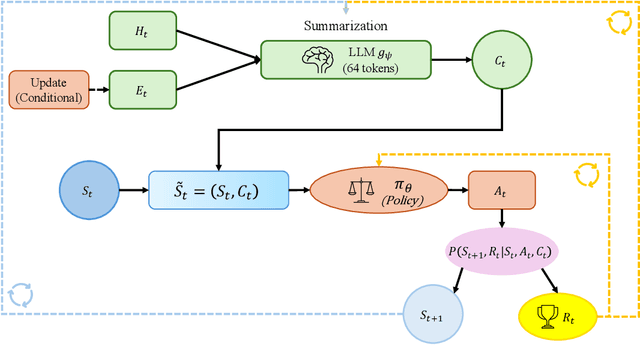

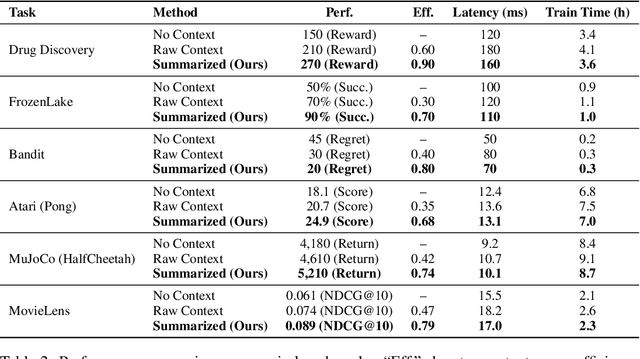
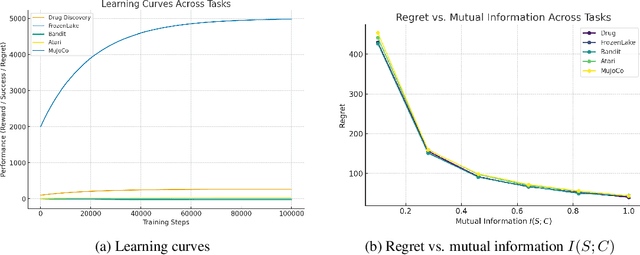
Contextual Markov Decision Processes (CMDPs) offer a framework for sequential decision-making under external signals, but existing methods often fail to generalize in high-dimensional or unstructured contexts, resulting in excessive computation and unstable performance. We propose an information-theoretic summarization approach that uses large language models (LLMs) to compress contextual inputs into low-dimensional, semantically rich summaries. These summaries augment states by preserving decision-critical cues while reducing redundancy. Building on the notion of approximate context sufficiency, we provide, to our knowledge, the first regret bounds and a latency-entropy trade-off characterization for CMDPs. Our analysis clarifies how informativeness impacts computational cost. Experiments across discrete, continuous, visual, and recommendation benchmarks show that our method outperforms raw-context and non-context baselines, improving reward, success rate, and sample efficiency, while reducing latency and memory usage. These findings demonstrate that LLM-based summarization offers a scalable and interpretable solution for efficient decision-making in context-rich, resource-constrained environments.