 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHypercube-RAG: Hypercube-Based Retrieval-Augmented Generation for In-domain Scientific Question-Answering
May 25, 2025

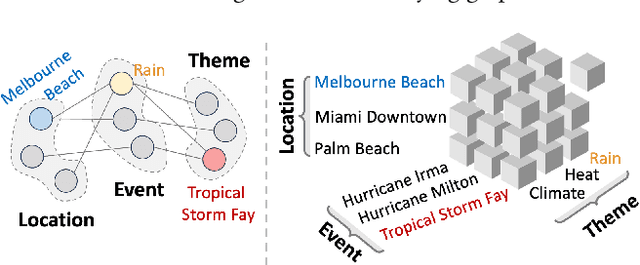
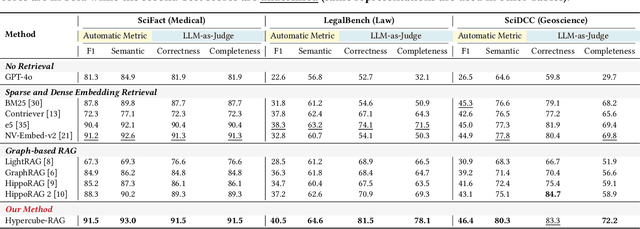
Large language models (LLMs) often need to incorporate external knowledge to solve theme-specific problems. Retrieval-augmented generation (RAG), which empowers LLMs to generate more qualified responses with retrieved external data and knowledge, has shown its high promise. However, traditional semantic similarity-based RAGs struggle to return concise yet highly relevant information for domain knowledge-intensive tasks, such as scientific question-answering (QA). Built on a multi-dimensional (cube) structure called Hypercube, which can index documents in an application-driven, human-defined, multi-dimensional space, we introduce the Hypercube-RAG, a novel RAG framework for precise and efficient retrieval. Given a query, Hypercube-RAG first decomposes it based on its entities and topics and then retrieves relevant documents from cubes by aligning these decomposed components with hypercube dimensions. Experiments on three in-domain scientific QA datasets demonstrate that our method improves accuracy by 3.7% and boosts retrieval efficiency by 81.2%, measured as relative gains over the strongest RAG baseline. More importantly, our Hypercube-RAG inherently offers explainability by revealing the underlying predefined hypercube dimensions used for retrieval. The code and data sets are available at https://github.com/JimengShi/Hypercube-RAG.
DynamicRAG: Leveraging Outputs of Large Language Model as Feedback for Dynamic Reranking in Retrieval-Augmented Generation
May 12, 2025Retrieval-augmented generation (RAG) systems combine large language models (LLMs) with external knowledge retrieval, making them highly effective for knowledge-intensive tasks. A crucial but often under-explored component of these systems is the reranker, which refines retrieved documents to enhance generation quality and explainability. The challenge of selecting the optimal number of documents (k) remains unsolved: too few may omit critical information, while too many introduce noise and inefficiencies. Although recent studies have explored LLM-based rerankers, they primarily leverage internal model knowledge and overlook the rich supervisory signals that LLMs can provide, such as using response quality as feedback for optimizing reranking decisions. In this paper, we propose DynamicRAG, a novel RAG framework where the reranker dynamically adjusts both the order and number of retrieved documents based on the query. We model the reranker as an agent optimized through reinforcement learning (RL), using rewards derived from LLM output quality. Across seven knowledge-intensive datasets, DynamicRAG demonstrates superior performance, achieving state-of-the-art results. The model, data and code are available at https://github.com/GasolSun36/DynamicRAG
From RAG to Memory: Non-Parametric Continual Learning for Large Language Models
Feb 20, 2025

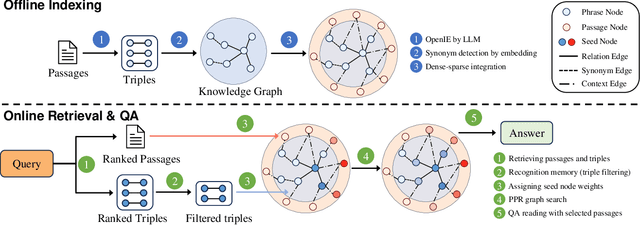
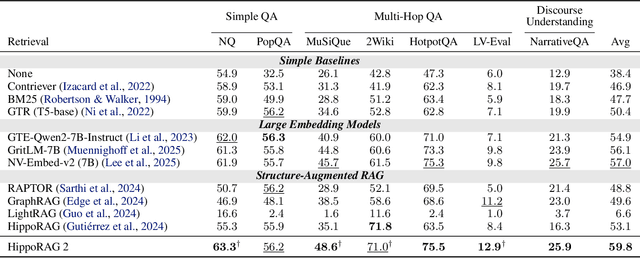
Our ability to continuously acquire, organize, and leverage knowledge is a key feature of human intelligence that AI systems must approximate to unlock their full potential. Given the challenges in continual learning with large language models (LLMs), retrieval-augmented generation (RAG) has become the dominant way to introduce new information. However, its reliance on vector retrieval hinders its ability to mimic the dynamic and interconnected nature of human long-term memory. Recent RAG approaches augment vector embeddings with various structures like knowledge graphs to address some of these gaps, namely sense-making and associativity. However, their performance on more basic factual memory tasks drops considerably below standard RAG. We address this unintended deterioration and propose HippoRAG 2, a framework that outperforms standard RAG comprehensively on factual, sense-making, and associative memory tasks. HippoRAG 2 builds upon the Personalized PageRank algorithm used in HippoRAG and enhances it with deeper passage integration and more effective online use of an LLM. This combination pushes this RAG system closer to the effectiveness of human long-term memory, achieving a 7% improvement in associative memory tasks over the state-of-the-art embedding model while also exhibiting superior factual knowledge and sense-making memory capabilities. This work paves the way for non-parametric continual learning for LLMs. Our code and data will be released at https://github.com/OSU-NLP-Group/HippoRAG.
Deep Learning and Foundation Models for Weather Prediction: A Survey
Jan 12, 2025Physics-based numerical models have been the bedrock of atmospheric sciences for decades, offering robust solutions but often at the cost of significant computational resources. Deep learning (DL) models have emerged as powerful tools in meteorology, capable of analyzing complex weather and climate data by learning intricate dependencies and providing rapid predictions once trained. While these models demonstrate promising performance in weather prediction, often surpassing traditional physics-based methods, they still face critical challenges. This paper presents a comprehensive survey of recent deep learning and foundation models for weather prediction. We propose a taxonomy to classify existing models based on their training paradigms: deterministic predictive learning, probabilistic generative learning, and pre-training and fine-tuning. For each paradigm, we delve into the underlying model architectures, address major challenges, offer key insights, and propose targeted directions for future research. Furthermore, we explore real-world applications of these methods and provide a curated summary of open-source code repositories and widely used datasets, aiming to bridge research advancements with practical implementations while fostering open and trustworthy scientific practices in adopting cutting-edge artificial intelligence for weather prediction. The related sources are available at https://github.com/JimengShi/ DL-Foundation-Models-Weather.
Large Language Models as User-Agents for Evaluating Task-Oriented-Dialogue Systems
Nov 15, 2024Traditionally, offline datasets have been used to evaluate task-oriented dialogue (TOD) models. These datasets lack context awareness, making them suboptimal benchmarks for conversational systems. In contrast, user-agents, which are context-aware, can simulate the variability and unpredictability of human conversations, making them better alternatives as evaluators. Prior research has utilized large language models (LLMs) to develop user-agents. Our work builds upon this by using LLMs to create user-agents for the evaluation of TOD systems. This involves prompting an LLM, using in-context examples as guidance, and tracking the user-goal state. Our evaluation of diversity and task completion metrics for the user-agents shows improved performance with the use of better prompts. Additionally, we propose methodologies for the automatic evaluation of TOD models within this dynamic framework.
Establishing Knowledge Preference in Language Models
Jul 17, 2024Language models are known to encode a great amount of factual knowledge through pretraining. However, such knowledge might be insufficient to cater to user requests, requiring the model to integrate external knowledge sources and adhere to user-provided specifications. When answering questions about ongoing events, the model should use recent news articles to update its response; when asked to provide recommendations, the model should prioritize user specifications over retrieved product reviews; when some facts are edited in the model, the updated facts should override all prior knowledge learned by the model even if they are conflicting. In all of the cases above, the model faces a decision between its own parametric knowledge, (retrieved) contextual knowledge, and user instruction knowledge. In this paper, we (1) unify such settings into the problem of knowledge preference and define a three-level preference hierarchy over these knowledge sources; (2) compile a collection of existing datasets IfQA, MQuAKE, and MRQA covering a combination of settings (with/without user specifications, with/without context documents) to systematically evaluate how well models obey the intended knowledge preference; and (3) propose a dataset synthesis method that composes diverse question-answer pairs with user assumptions and related context to directly fine-tune LMs for instilling the hierarchy of knowledge. We demonstrate that a 7B model, fine-tuned on only a few thousand examples automatically generated by our proposed method, effectively achieves superior performance (more than 18% improvement across all evaluation benchmarks) in adhering to the desired knowledge preference hierarchy.
Automated Construction of Theme-specific Knowledge Graphs
Apr 29, 2024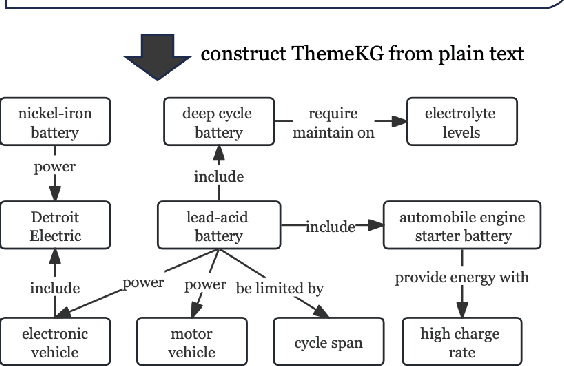
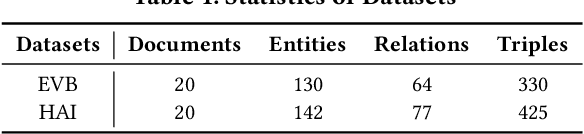
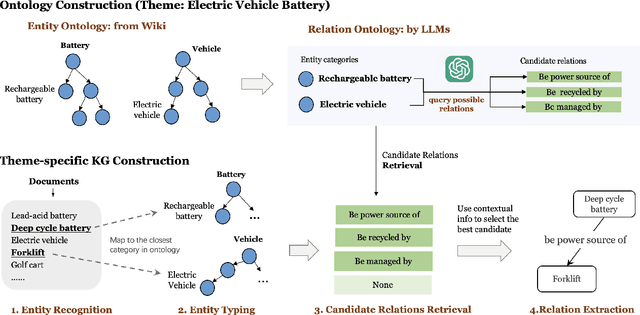
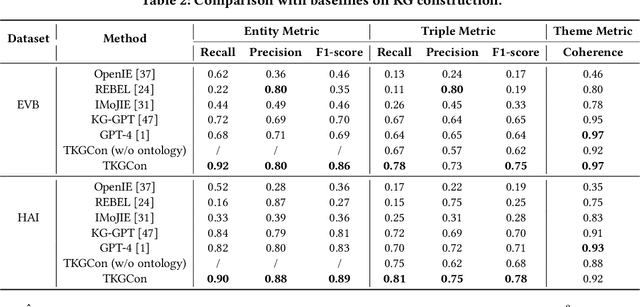
Despite widespread applications of knowledge graphs (KGs) in various tasks such as question answering and intelligent conversational systems, existing KGs face two major challenges: information granularity and deficiency in timeliness. These hinder considerably the retrieval and analysis of in-context, fine-grained, and up-to-date knowledge from KGs, particularly in highly specialized themes (e.g., specialized scientific research) and rapidly evolving contexts (e.g., breaking news or disaster tracking). To tackle such challenges, we propose a theme-specific knowledge graph (i.e., ThemeKG), a KG constructed from a theme-specific corpus, and design an unsupervised framework for ThemeKG construction (named TKGCon). The framework takes raw theme-specific corpus and generates a high-quality KG that includes salient entities and relations under the theme. Specifically, we start with an entity ontology of the theme from Wikipedia, based on which we then generate candidate relations by Large Language Models (LLMs) to construct a relation ontology. To parse the documents from the theme corpus, we first map the extracted entity pairs to the ontology and retrieve the candidate relations. Finally, we incorporate the context and ontology to consolidate the relations for entity pairs. We observe that directly prompting GPT-4 for theme-specific KG leads to inaccurate entities (such as "two main types" as one entity in the query result) and unclear (such as "is", "has") or wrong relations (such as "have due to", "to start"). In contrast, by constructing the theme-specific KG step by step, our model outperforms GPT-4 and could consistently identify accurate entities and relations. Experimental results also show that our framework excels in evaluations compared with various KG construction baselines.
Grasping the Essentials: Tailoring Large Language Models for Zero-Shot Relation Extraction
Feb 17, 2024



Relation extraction (RE), a crucial task in NLP, aims to identify semantic relationships between entities mentioned in texts. Despite significant advancements in this field, existing models typically rely on extensive annotated data for training, which can be both costly and time-consuming to acquire. Moreover, these models often struggle to adapt to new or unseen relationships. In contrast, few-shot learning settings, which aim to reduce annotation requirements, may offer incomplete and biased supervision for understanding target relation semantics, leading to degraded and unstable performance. To provide the model with accurate and explicit descriptions of the relations types and meanwhile minimize the annotation requirements, we study the definition only zero-shot RE setting where only relation definitions expressed in natural language are used to train a RE model. Motivated by the strong synthetic data generation power of LLMs, we propose a framework REPaL which consists of three stages: (1) We utilize LLMs to generate initial seed instances based on relation definitions and an unlabeled corpora. (2) We fine-tune a bidirectional Small Language Model (SLM) using these initial seeds to learn the relations for the target domain. (3) We enhance pattern coverage and mitigate bias resulting from the limited number of initial seeds by incorporating feedback acquired from SLM's predictions on unlabeled corpora. To accomplish this, we leverage the multi-turn conversation ability of LLMs to generate new instances in follow-up dialogues. Experiments on two datasets show REPaL achieves better zero-shot performance with large margins over baseline methods.
Towards End-to-End Open Conversational Machine Reading
Oct 13, 2022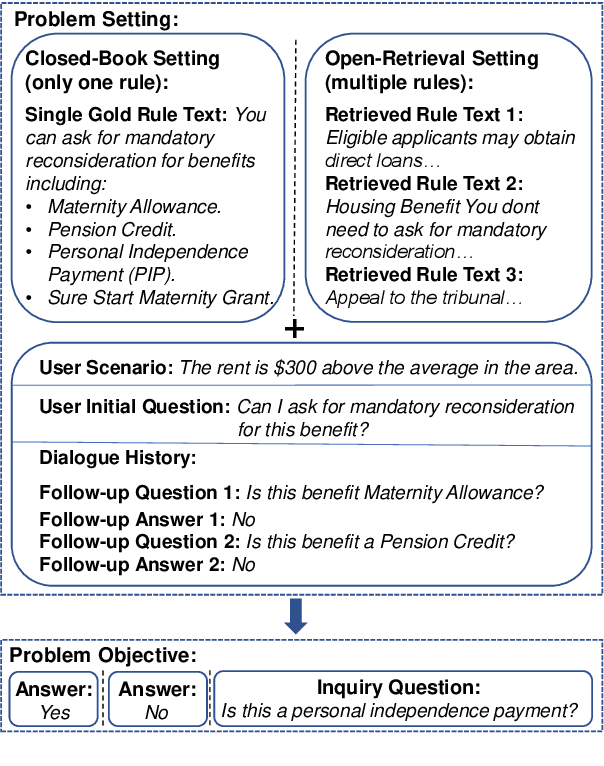

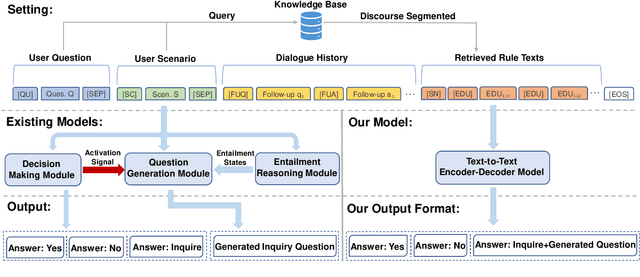
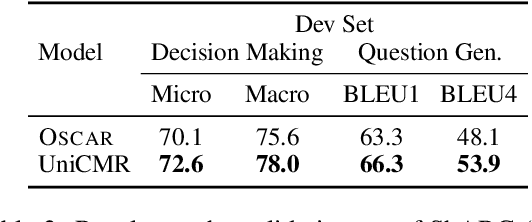
In open-retrieval conversational machine reading (OR-CMR) task, machines are required to do multi-turn question answering given dialogue history and a textual knowledge base. Existing works generally utilize two independent modules to approach this problem's two successive sub-tasks: first with a hard-label decision making and second with a question generation aided by various entailment reasoning methods. Such usual cascaded modeling is vulnerable to error propagation and prevents the two sub-tasks from being consistently optimized. In this work, we instead model OR-CMR as a unified text-to-text task in a fully end-to-end style. Experiments on the OR-ShARC dataset show the effectiveness of our proposed end-to-end framework on both sub-tasks by a large margin, achieving new state-of-the-art results. Further ablation studies support that our framework can generalize to different backbone models.