 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVPO: Aligning Text-to-Video Generation Models with Prompt Optimization
Mar 26, 2025

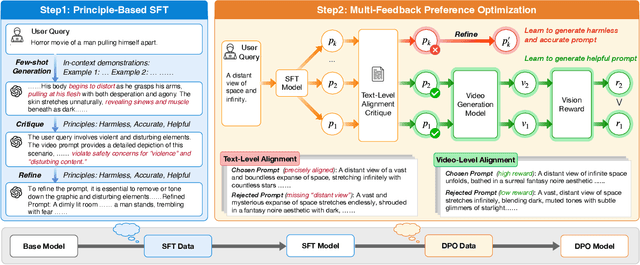
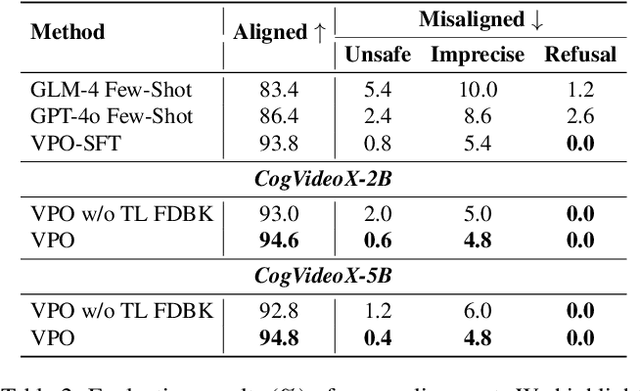
Video generation models have achieved remarkable progress in text-to-video tasks. These models are typically trained on text-video pairs with highly detailed and carefully crafted descriptions, while real-world user inputs during inference are often concise, vague, or poorly structured. This gap makes prompt optimization crucial for generating high-quality videos. Current methods often rely on large language models (LLMs) to refine prompts through in-context learning, but suffer from several limitations: they may distort user intent, omit critical details, or introduce safety risks. Moreover, they optimize prompts without considering the impact on the final video quality, which can lead to suboptimal results. To address these issues, we introduce VPO, a principled framework that optimizes prompts based on three core principles: harmlessness, accuracy, and helpfulness. The generated prompts faithfully preserve user intents and, more importantly, enhance the safety and quality of generated videos. To achieve this, VPO employs a two-stage optimization approach. First, we construct and refine a supervised fine-tuning (SFT) dataset based on principles of safety and alignment. Second, we introduce both text-level and video-level feedback to further optimize the SFT model with preference learning. Our extensive experiments demonstrate that VPO significantly improves safety, alignment, and video quality compared to baseline methods. Moreover, VPO shows strong generalization across video generation models. Furthermore, we demonstrate that VPO could outperform and be combined with RLHF methods on video generation models, underscoring the effectiveness of VPO in aligning video generation models. Our code and data are publicly available at https://github.com/thu-coai/VPO.
Large Language Models as User-Agents for Evaluating Task-Oriented-Dialogue Systems
Nov 15, 2024Traditionally, offline datasets have been used to evaluate task-oriented dialogue (TOD) models. These datasets lack context awareness, making them suboptimal benchmarks for conversational systems. In contrast, user-agents, which are context-aware, can simulate the variability and unpredictability of human conversations, making them better alternatives as evaluators. Prior research has utilized large language models (LLMs) to develop user-agents. Our work builds upon this by using LLMs to create user-agents for the evaluation of TOD systems. This involves prompting an LLM, using in-context examples as guidance, and tracking the user-goal state. Our evaluation of diversity and task completion metrics for the user-agents shows improved performance with the use of better prompts. Additionally, we propose methodologies for the automatic evaluation of TOD models within this dynamic framework.
Mining Entity Synonyms with Efficient Neural Set Generation
Nov 16, 2018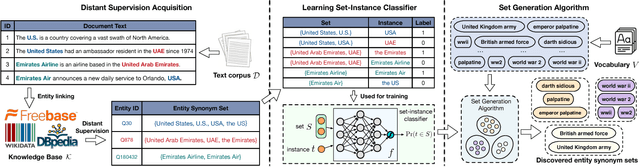
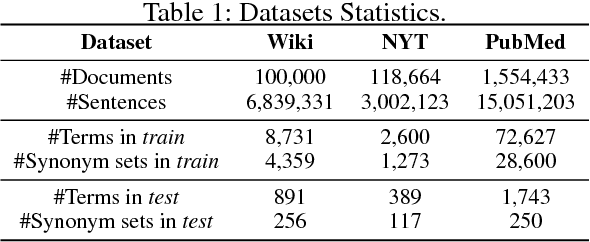
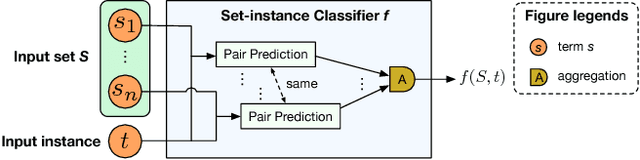

Mining entity synonym sets (i.e., sets of terms referring to the same entity) is an important task for many entity-leveraging applications. Previous work either rank terms based on their similarity to a given query term, or treats the problem as a two-phase task (i.e., detecting synonymy pairs, followed by organizing these pairs into synonym sets). However, these approaches fail to model the holistic semantics of a set and suffer from the error propagation issue. Here we propose a new framework, named SynSetMine, that efficiently generates entity synonym sets from a given vocabulary, using example sets from external knowledge bases as distant supervision. SynSetMine consists of two novel modules: (1) a set-instance classifier that jointly learns how to represent a permutation invariant synonym set and whether to include a new instance (i.e., a term) into the set, and (2) a set generation algorithm that enumerates the vocabulary only once and applies the learned set-instance classifier to detect all entity synonym sets in it. Experiments on three real datasets from different domains demonstrate both effectiveness and efficiency of SynSetMine for mining entity synonym sets.