 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Planning into Single-Turn Long-Form Text Generation
Oct 08, 2024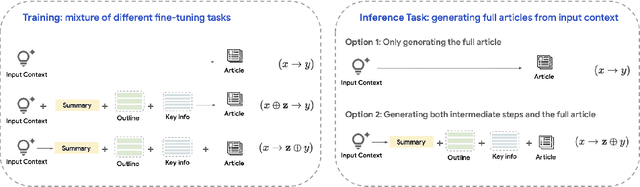

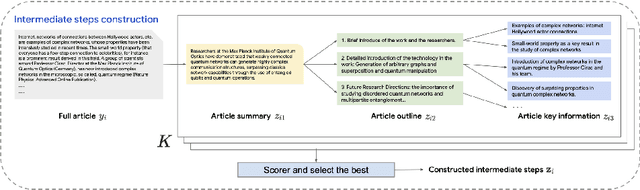
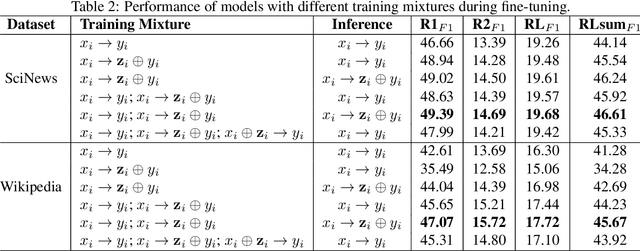
Generating high-quality, in-depth textual documents, such as academic papers, news articles, Wikipedia entries, and books, remains a significant challenge for Large Language Models (LLMs). In this paper, we propose to use planning to generate long form content. To achieve our goal, we generate intermediate steps via an auxiliary task that teaches the LLM to plan, reason and structure before generating the final text. Our main novelty lies in a single auxiliary task that does not require multiple rounds of prompting or planning. To overcome the scarcity of training data for these intermediate steps, we leverage LLMs to generate synthetic intermediate writing data such as outlines, key information and summaries from existing full articles. Our experiments demonstrate on two datasets from different domains, namely the scientific news dataset SciNews and Wikipedia datasets in KILT-Wiki and FreshWiki, that LLMs fine-tuned with the auxiliary task generate higher quality documents. We observed +2.5% improvement in ROUGE-Lsum, and a strong 3.60 overall win/loss ratio via human SxS evaluation, with clear wins in organization, relevance, and verifiability.
Building Math Agents with Multi-Turn Iterative Preference Learning
Sep 04, 2024



Recent studies have shown that large language models' (LLMs) mathematical problem-solving capabilities can be enhanced by integrating external tools, such as code interpreters, and employing multi-turn Chain-of-Thought (CoT) reasoning. While current methods focus on synthetic data generation and Supervised Fine-Tuning (SFT), this paper studies the complementary direct preference learning approach to further improve model performance. However, existing direct preference learning algorithms are originally designed for the single-turn chat task, and do not fully address the complexities of multi-turn reasoning and external tool integration required for tool-integrated mathematical reasoning tasks. To fill in this gap, we introduce a multi-turn direct preference learning framework, tailored for this context, that leverages feedback from code interpreters and optimizes trajectory-level preferences. This framework includes multi-turn DPO and multi-turn KTO as specific implementations. The effectiveness of our framework is validated through training of various language models using an augmented prompt set from the GSM8K and MATH datasets. Our results demonstrate substantial improvements: a supervised fine-tuned Gemma-1.1-it-7B model's performance increased from 77.5% to 83.9% on GSM8K and from 46.1% to 51.2% on MATH. Similarly, a Gemma-2-it-9B model improved from 84.1% to 86.3% on GSM8K and from 51.0% to 54.5% on MATH.
LAMPO: Large Language Models as Preference Machines for Few-shot Ordinal Classification
Aug 06, 2024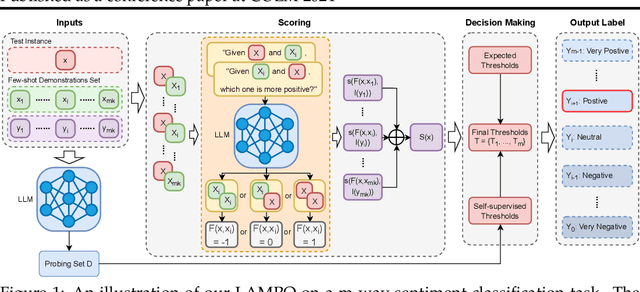
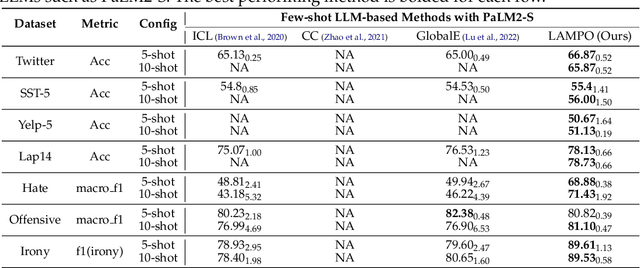
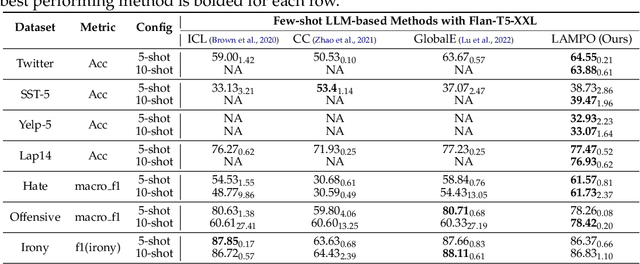
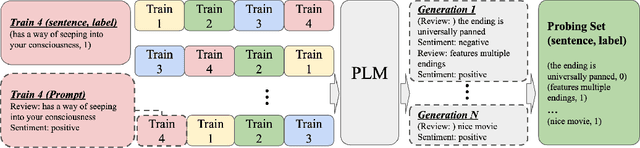
We introduce LAMPO, a novel paradigm that leverages Large Language Models (LLMs) for solving few-shot multi-class ordinal classification tasks. Unlike conventional methods, which concatenate all demonstration examples with the test instance and prompt LLMs to produce the pointwise prediction, our framework uses the LLM as a preference machine that makes a relative comparative decision between the test instance and each demonstration. A self-supervised method is then introduced to aggregate these binary comparisons into the final ordinal decision. LAMPO addresses several limitations inherent in previous methods, including context length constraints, ordering biases, and challenges associated with absolute point-wise estimation. Extensive experiments on seven public datasets demonstrate LAMPO's remarkably competitive performance across a diverse spectrum of applications (e.g., movie review analysis and hate speech detection). Notably, in certain applications, the improvement can be substantial, exceeding 20% in an absolute term. Moreover, we believe LAMPO represents an interesting addition to the non-parametric application layered on top of LLMs, as it supports black-box LLMs without necessitating the outputting of LLM's internal states (e.g., embeddings), as seen in previous approaches.
Multilingual Fine-Grained News Headline Hallucination Detection
Jul 22, 2024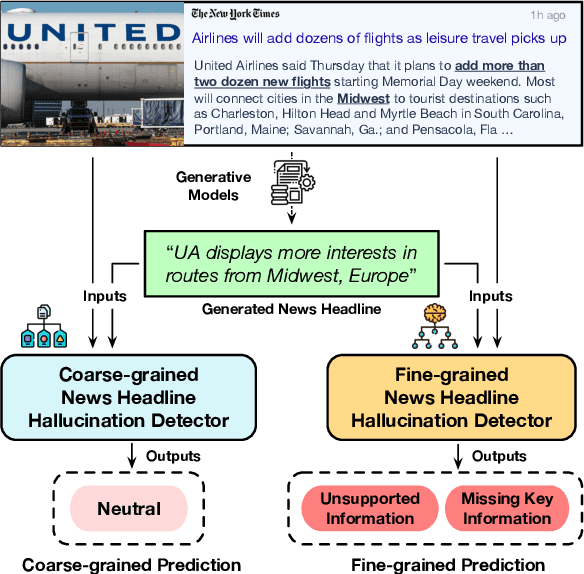
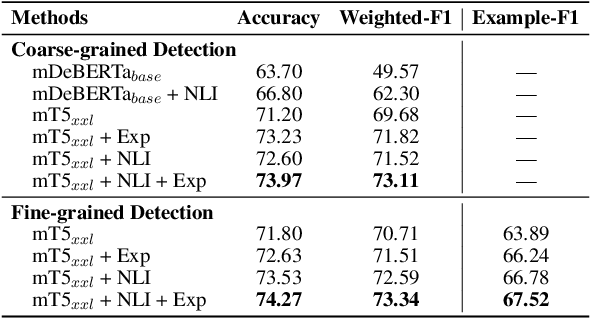
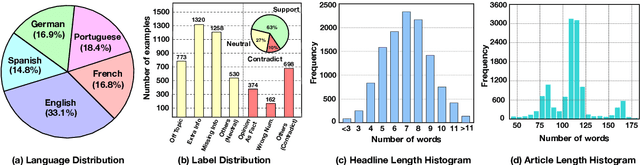
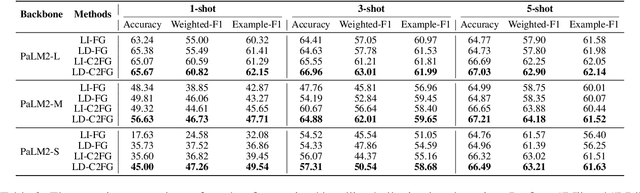
The popularity of automated news headline generation has surged with advancements in pre-trained language models. However, these models often suffer from the ``hallucination'' problem, where the generated headline is not fully supported by its source article. Efforts to address this issue have predominantly focused on English, using over-simplistic classification schemes that overlook nuanced hallucination types. In this study, we introduce the first multilingual, fine-grained news headline hallucination detection dataset that contains over 11 thousand pairs in 5 languages, each annotated with detailed hallucination types by experts. We conduct extensive experiments on this dataset under two settings. First, we implement several supervised fine-tuning approaches as preparatory solutions and demonstrate this dataset's challenges and utilities. Second, we test various large language models' in-context learning abilities and propose two novel techniques, language-dependent demonstration selection and coarse-to-fine prompting, to boost the few-shot hallucination detection performance in terms of the example-F1 metric. We release this dataset to foster further research in multilingual, fine-grained headline hallucination detection.
Boosting Reward Model with Preference-Conditional Multi-Aspect Synthetic Data Generation
Jul 22, 2024



Reward models (RMs) are crucial for aligning large language models (LLMs) with human preferences. They are trained using preference datasets where each example consists of one input prompt, two responses, and a preference label. As curating a high-quality human labeled preference dataset is both time-consuming and expensive, people often rely on existing powerful LLMs for preference label generation. This can potentially introduce noise and impede RM training. In this work, we present RMBoost, a novel synthetic preference data generation paradigm to boost reward model quality. Unlike traditional methods, which generate two responses before obtaining the preference label, RMBoost first generates one response and selects a preference label, followed by generating the second more (or less) preferred response conditioned on the pre-selected preference label and the first response. This approach offers two main advantages. First, RMBoost reduces labeling noise since preference pairs are constructed intentionally. Second, RMBoost facilitates the creation of more diverse responses by incorporating various quality aspects (e.g., helpfulness, relevance, completeness) into the prompts. We conduct extensive experiments across three diverse datasets and demonstrate that RMBoost outperforms other synthetic preference data generation techniques and significantly boosts the performance of four distinct reward models.
PLaD: Preference-based Large Language Model Distillation with Pseudo-Preference Pairs
Jun 06, 2024



Large Language Models (LLMs) have exhibited impressive capabilities in various tasks, yet their vast parameter sizes restrict their applicability in resource-constrained settings. Knowledge distillation (KD) offers a viable solution by transferring expertise from large teacher models to compact student models. However, traditional KD techniques face specific challenges when applied to LLMs, including restricted access to LLM outputs, significant teacher-student capacity gaps, and the inherited mis-calibration issue. In this work, we present PLaD, a novel preference-based LLM distillation framework. PLaD exploits the teacher-student capacity discrepancy to generate pseudo-preference pairs where teacher outputs are preferred over student outputs. Then, PLaD leverages a ranking loss to re-calibrate student's estimation of sequence likelihood, which steers the student's focus towards understanding the relative quality of outputs instead of simply imitating the teacher. PLaD bypasses the need for access to teacher LLM's internal states, tackles the student's expressivity limitations, and mitigates the student mis-calibration issue. Through extensive experiments on two sequence generation tasks and with various LLMs, we demonstrate the effectiveness of our proposed PLaD framework.
HeMeNet: Heterogeneous Multichannel Equivariant Network for Protein Multitask Learning
Apr 02, 2024



Understanding and leveraging the 3D structures of proteins is central to a variety of biological and drug discovery tasks. While deep learning has been applied successfully for structure-based protein function prediction tasks, current methods usually employ distinct training for each task. However, each of the tasks is of small size, and such a single-task strategy hinders the models' performance and generalization ability. As some labeled 3D protein datasets are biologically related, combining multi-source datasets for larger-scale multi-task learning is one way to overcome this problem. In this paper, we propose a neural network model to address multiple tasks jointly upon the input of 3D protein structures. In particular, we first construct a standard structure-based multi-task benchmark called Protein-MT, consisting of 6 biologically relevant tasks, including affinity prediction and property prediction, integrated from 4 public datasets. Then, we develop a novel graph neural network for multi-task learning, dubbed Heterogeneous Multichannel Equivariant Network (HeMeNet), which is E(3) equivariant and able to capture heterogeneous relationships between different atoms. Besides, HeMeNet can achieve task-specific learning via the task-aware readout mechanism. Extensive evaluations on our benchmark verify the effectiveness of multi-task learning, and our model generally surpasses state-of-the-art models.
TELEClass: Taxonomy Enrichment and LLM-Enhanced Hierarchical Text Classification with Minimal Supervision
Feb 29, 2024



Hierarchical text classification aims to categorize each document into a set of classes in a label taxonomy. Most earlier works focus on fully or semi-supervised methods that require a large amount of human annotated data which is costly and time-consuming to acquire. To alleviate human efforts, in this paper, we work on hierarchical text classification with the minimal amount of supervision: using the sole class name of each node as the only supervision. Recently, large language models (LLM) show competitive performance on various tasks through zero-shot prompting, but this method performs poorly in the hierarchical setting, because it is ineffective to include the large and structured label space in a prompt. On the other hand, previous weakly-supervised hierarchical text classification methods only utilize the raw taxonomy skeleton and ignore the rich information hidden in the text corpus that can serve as additional class-indicative features. To tackle the above challenges, we propose TELEClass, Taxonomy Enrichment and LLM-Enhanced weakly-supervised hierarchical text classification, which (1) automatically enriches the label taxonomy with class-indicative topical terms mined from the corpus to facilitate classifier training and (2) utilizes LLMs for both data annotation and creation tailored for the hierarchical label space. Experiments show that TELEClass can outperform previous weakly-supervised hierarchical text classification methods and LLM-based zero-shot prompting methods on two public datasets.
LiPO: Listwise Preference Optimization through Learning-to-Rank
Feb 02, 2024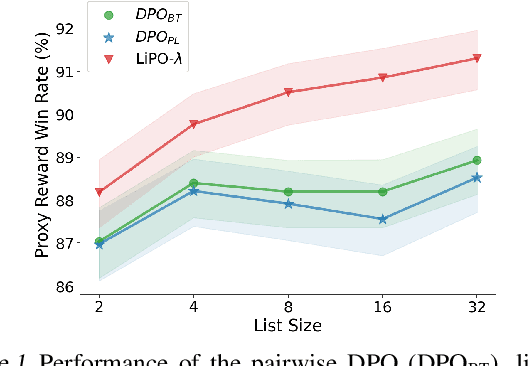



Aligning language models (LMs) with curated human feedback is critical to control their behaviors in real-world applications. Several recent policy optimization methods, such as DPO and SLiC, serve as promising alternatives to the traditional Reinforcement Learning from Human Feedback (RLHF) approach. In practice, human feedback often comes in a format of a ranked list over multiple responses to amortize the cost of reading prompt. Multiple responses can also be ranked by reward models or AI feedback. There lacks such a study on directly fitting upon a list of responses. In this work, we formulate the LM alignment as a listwise ranking problem and describe the Listwise Preference Optimization (LiPO) framework, where the policy can potentially learn more effectively from a ranked list of plausible responses given the prompt. This view draws an explicit connection to Learning-to-Rank (LTR), where most existing preference optimization work can be mapped to existing ranking objectives, especially pairwise ones. Following this connection, we provide an examination of ranking objectives that are not well studied for LM alignment withDPO and SLiC as special cases when list size is two. In particular, we highlight a specific method, LiPO-{\lambda}, which leverages a state-of-the-art listwise ranking objective and weights each preference pair in a more advanced manner. We show that LiPO-{\lambda} can outperform DPO and SLiC by a clear margin on two preference alignment tasks.
On What Basis? Predicting Text Preference Via Structured Comparative Reasoning
Nov 14, 2023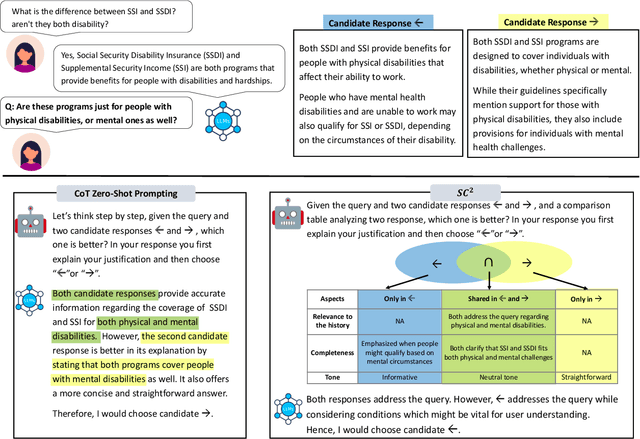

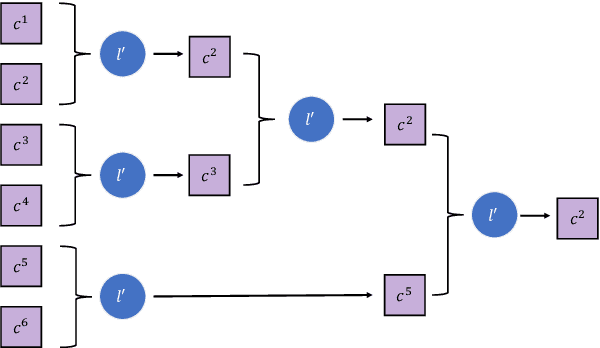
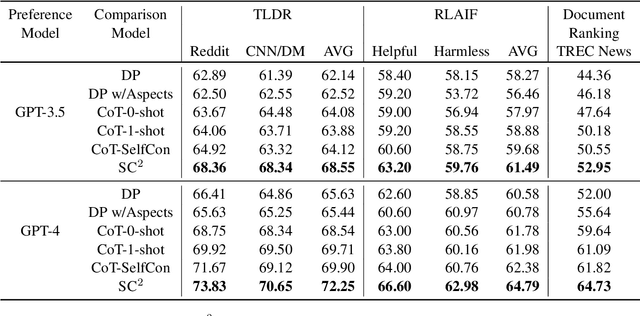
Comparative reasoning plays a crucial role in text preference prediction; however, large language models (LLMs) often demonstrate inconsistencies in their reasoning. While approaches like Chain-of-Thought improve accuracy in many other settings, they struggle to consistently distinguish the similarities and differences of complex texts. We introduce SC, a prompting approach that predicts text preferences by generating structured intermediate comparisons. SC begins by proposing aspects of comparison, followed by generating textual comparisons under each aspect. We select consistent comparisons with a pairwise consistency comparator that ensures each aspect's comparisons clearly distinguish differences between texts, significantly reducing hallucination and improving consistency. Our comprehensive evaluations across various NLP tasks, including summarization, retrieval, and automatic rating, demonstrate that SC equips LLMs to achieve state-of-the-art performance in text preference prediction.