 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe FACTS Leaderboard: A Comprehensive Benchmark for Large Language Model Factuality
Dec 11, 2025We introduce The FACTS Leaderboard, an online leaderboard suite and associated set of benchmarks that comprehensively evaluates the ability of language models to generate factually accurate text across diverse scenarios. The suite provides a holistic measure of factuality by aggregating the performance of models on four distinct sub-leaderboards: (1) FACTS Multimodal, which measures the factuality of responses to image-based questions; (2) FACTS Parametric, which assesses models' world knowledge by answering closed-book factoid questions from internal parameters; (3) FACTS Search, which evaluates factuality in information-seeking scenarios, where the model must use a search API; and (4) FACTS Grounding (v2), which evaluates whether long-form responses are grounded in provided documents, featuring significantly improved judge models. Each sub-leaderboard employs automated judge models to score model responses, and the final suite score is an average of the four components, designed to provide a robust and balanced assessment of a model's overall factuality. The FACTS Leaderboard Suite will be actively maintained, containing both public and private splits to allow for external participation while guarding its integrity. It can be found at https://www.kaggle.com/benchmarks/google/facts .
Optimizing Compound Retrieval Systems
Apr 16, 2025



Modern retrieval systems do not rely on a single ranking model to construct their rankings. Instead, they generally take a cascading approach where a sequence of ranking models are applied in multiple re-ranking stages. Thereby, they balance the quality of the top-K ranking with computational costs by limiting the number of documents each model re-ranks. However, the cascading approach is not the only way models can interact to form a retrieval system. We propose the concept of compound retrieval systems as a broader class of retrieval systems that apply multiple prediction models. This encapsulates cascading models but also allows other types of interactions than top-K re-ranking. In particular, we enable interactions with large language models (LLMs) which can provide relative relevance comparisons. We focus on the optimization of compound retrieval system design which uniquely involves learning where to apply the component models and how to aggregate their predictions into a final ranking. This work shows how our compound approach can combine the classic BM25 retrieval model with state-of-the-art (pairwise) LLM relevance predictions, while optimizing a given ranking metric and efficiency target. Our experimental results show optimized compound retrieval systems provide better trade-offs between effectiveness and efficiency than cascading approaches, even when applied in a self-supervised manner. With the introduction of compound retrieval systems, we hope to inspire the information retrieval field to more out-of-the-box thinking on how prediction models can interact to form rankings.
Adapting Decoder-Based Language Models for Diverse Encoder Downstream Tasks
Mar 04, 2025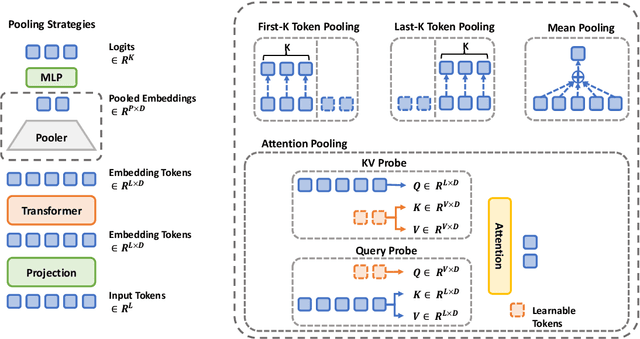
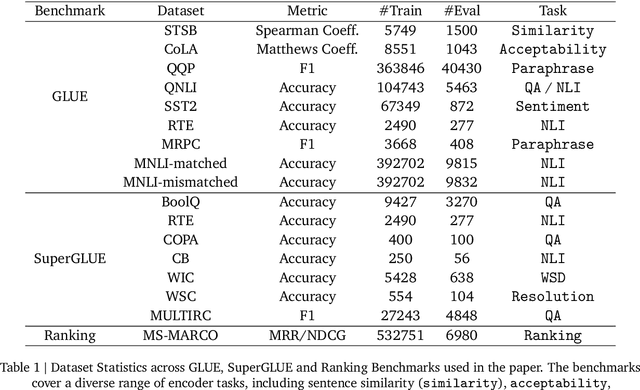
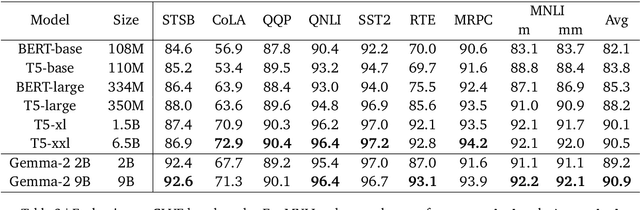
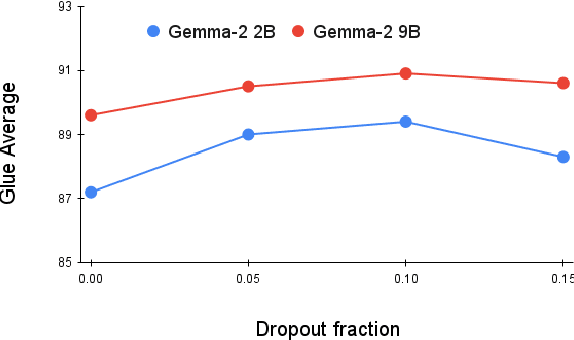
Decoder-based transformers, while revolutionizing language modeling and scaling to immense sizes, have not completely overtaken encoder-heavy architectures in natural language processing. Specifically, encoder-only models remain dominant in tasks like classification, regression, and ranking. This is primarily due to the inherent structure of decoder-based models, which limits their direct applicability to these tasks. In this paper, we introduce Gemma Encoder, adapting the powerful Gemma decoder model to an encoder architecture, thereby unlocking its potential for a wider range of non-generative applications. To optimize the adaptation from decoder to encoder, we systematically analyze various pooling strategies, attention mechanisms, and hyperparameters (e.g., dropout rate). Furthermore, we benchmark Gemma Encoder against established approaches on the GLUE benchmarks, and MS MARCO ranking benchmark, demonstrating its effectiveness and versatility.
Searching Personal Collections
Dec 16, 2024This article describes the history of information retrieval on personal document collections.
Integrating Planning into Single-Turn Long-Form Text Generation
Oct 08, 2024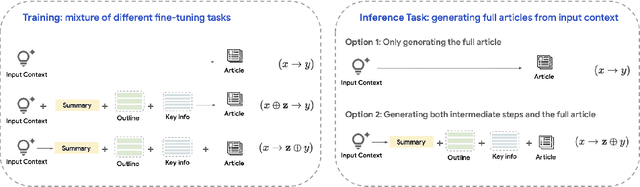

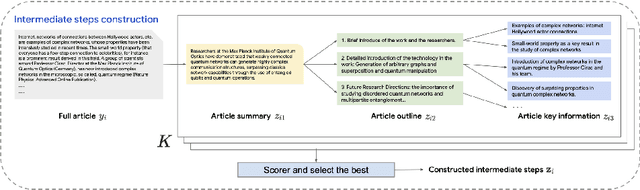
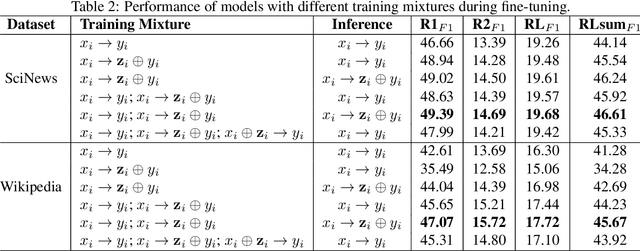
Generating high-quality, in-depth textual documents, such as academic papers, news articles, Wikipedia entries, and books, remains a significant challenge for Large Language Models (LLMs). In this paper, we propose to use planning to generate long form content. To achieve our goal, we generate intermediate steps via an auxiliary task that teaches the LLM to plan, reason and structure before generating the final text. Our main novelty lies in a single auxiliary task that does not require multiple rounds of prompting or planning. To overcome the scarcity of training data for these intermediate steps, we leverage LLMs to generate synthetic intermediate writing data such as outlines, key information and summaries from existing full articles. Our experiments demonstrate on two datasets from different domains, namely the scientific news dataset SciNews and Wikipedia datasets in KILT-Wiki and FreshWiki, that LLMs fine-tuned with the auxiliary task generate higher quality documents. We observed +2.5% improvement in ROUGE-Lsum, and a strong 3.60 overall win/loss ratio via human SxS evaluation, with clear wins in organization, relevance, and verifiability.
Inference Scaling for Long-Context Retrieval Augmented Generation
Oct 06, 2024



The scaling of inference computation has unlocked the potential of long-context large language models (LLMs) across diverse settings. For knowledge-intensive tasks, the increased compute is often allocated to incorporate more external knowledge. However, without effectively utilizing such knowledge, solely expanding context does not always enhance performance. In this work, we investigate inference scaling for retrieval augmented generation (RAG), exploring strategies beyond simply increasing the quantity of knowledge. We focus on two inference scaling strategies: in-context learning and iterative prompting. These strategies provide additional flexibility to scale test-time computation (e.g., by increasing retrieved documents or generation steps), thereby enhancing LLMs' ability to effectively acquire and utilize contextual information. We address two key questions: (1) How does RAG performance benefit from the scaling of inference computation when optimally configured? (2) Can we predict the optimal test-time compute allocation for a given budget by modeling the relationship between RAG performance and inference parameters? Our observations reveal that increasing inference computation leads to nearly linear gains in RAG performance when optimally allocated, a relationship we describe as the inference scaling laws for RAG. Building on this, we further develop the computation allocation model to estimate RAG performance across different inference configurations. The model predicts optimal inference parameters under various computation constraints, which align closely with the experimental results. By applying these optimal configurations, we demonstrate that scaling inference compute on long-context LLMs achieves up to 58.9% gains on benchmark datasets compared to standard RAG.
LAMPO: Large Language Models as Preference Machines for Few-shot Ordinal Classification
Aug 06, 2024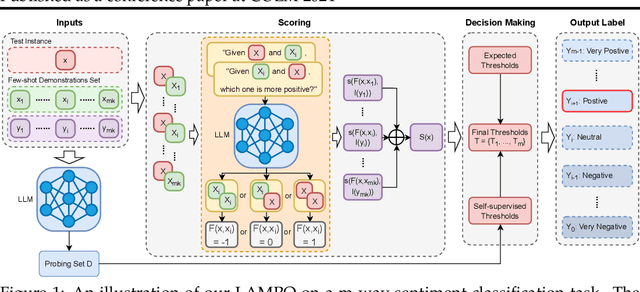
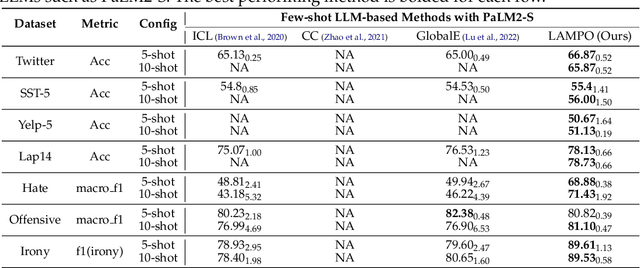
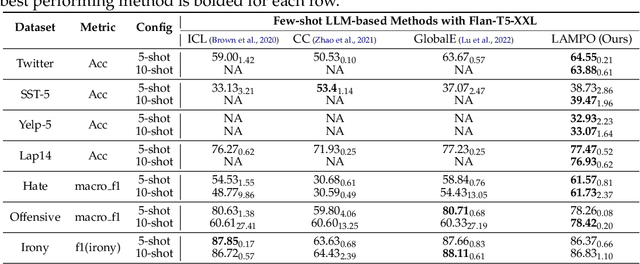
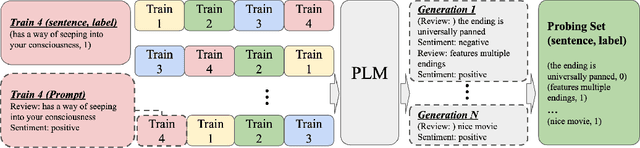
We introduce LAMPO, a novel paradigm that leverages Large Language Models (LLMs) for solving few-shot multi-class ordinal classification tasks. Unlike conventional methods, which concatenate all demonstration examples with the test instance and prompt LLMs to produce the pointwise prediction, our framework uses the LLM as a preference machine that makes a relative comparative decision between the test instance and each demonstration. A self-supervised method is then introduced to aggregate these binary comparisons into the final ordinal decision. LAMPO addresses several limitations inherent in previous methods, including context length constraints, ordering biases, and challenges associated with absolute point-wise estimation. Extensive experiments on seven public datasets demonstrate LAMPO's remarkably competitive performance across a diverse spectrum of applications (e.g., movie review analysis and hate speech detection). Notably, in certain applications, the improvement can be substantial, exceeding 20% in an absolute term. Moreover, we believe LAMPO represents an interesting addition to the non-parametric application layered on top of LLMs, as it supports black-box LLMs without necessitating the outputting of LLM's internal states (e.g., embeddings), as seen in previous approaches.
Reliable Confidence Intervals for Information Retrieval Evaluation Using Generative A.I
Jul 02, 2024



The traditional evaluation of information retrieval (IR) systems is generally very costly as it requires manual relevance annotation from human experts. Recent advancements in generative artificial intelligence -- specifically large language models (LLMs) -- can generate relevance annotations at an enormous scale with relatively small computational costs. Potentially, this could alleviate the costs traditionally associated with IR evaluation and make it applicable to numerous low-resource applications. However, generated relevance annotations are not immune to (systematic) errors, and as a result, directly using them for evaluation produces unreliable results. In this work, we propose two methods based on prediction-powered inference and conformal risk control that utilize computer-generated relevance annotations to place reliable confidence intervals (CIs) around IR evaluation metrics. Our proposed methods require a small number of reliable annotations from which the methods can statistically analyze the errors in the generated annotations. Using this information, we can place CIs around evaluation metrics with strong theoretical guarantees. Unlike existing approaches, our conformal risk control method is specifically designed for ranking metrics and can vary its CIs per query and document. Our experimental results show that our CIs accurately capture both the variance and bias in evaluation based on LLM annotations, better than the typical empirical bootstrapping estimates. We hope our contributions bring reliable evaluation to the many IR applications where this was traditionally infeasible.
Consolidating Ranking and Relevance Predictions of Large Language Models through Post-Processing
Apr 17, 2024



The powerful generative abilities of large language models (LLMs) show potential in generating relevance labels for search applications. Previous work has found that directly asking about relevancy, such as ``How relevant is document A to query Q?", results in sub-optimal ranking. Instead, the pairwise ranking prompting (PRP) approach produces promising ranking performance through asking about pairwise comparisons, e.g., ``Is document A more relevant than document B to query Q?". Thus, while LLMs are effective at their ranking ability, this is not reflected in their relevance label generation. In this work, we propose a post-processing method to consolidate the relevance labels generated by an LLM with its powerful ranking abilities. Our method takes both LLM generated relevance labels and pairwise preferences. The labels are then altered to satisfy the pairwise preferences of the LLM, while staying as close to the original values as possible. Our experimental results indicate that our approach effectively balances label accuracy and ranking performance. Thereby, our work shows it is possible to combine both the ranking and labeling abilities of LLMs through post-processing.
LiPO: Listwise Preference Optimization through Learning-to-Rank
Feb 02, 2024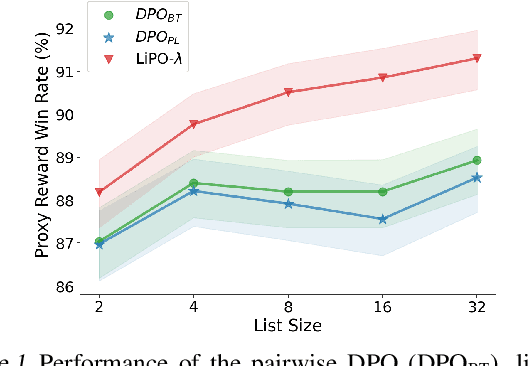



Aligning language models (LMs) with curated human feedback is critical to control their behaviors in real-world applications. Several recent policy optimization methods, such as DPO and SLiC, serve as promising alternatives to the traditional Reinforcement Learning from Human Feedback (RLHF) approach. In practice, human feedback often comes in a format of a ranked list over multiple responses to amortize the cost of reading prompt. Multiple responses can also be ranked by reward models or AI feedback. There lacks such a study on directly fitting upon a list of responses. In this work, we formulate the LM alignment as a listwise ranking problem and describe the Listwise Preference Optimization (LiPO) framework, where the policy can potentially learn more effectively from a ranked list of plausible responses given the prompt. This view draws an explicit connection to Learning-to-Rank (LTR), where most existing preference optimization work can be mapped to existing ranking objectives, especially pairwise ones. Following this connection, we provide an examination of ranking objectives that are not well studied for LM alignment withDPO and SLiC as special cases when list size is two. In particular, we highlight a specific method, LiPO-{\lambda}, which leverages a state-of-the-art listwise ranking objective and weights each preference pair in a more advanced manner. We show that LiPO-{\lambda} can outperform DPO and SLiC by a clear margin on two preference alignment tasks.