 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Planning into Single-Turn Long-Form Text Generation
Oct 08, 2024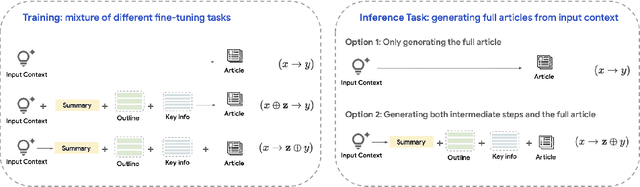

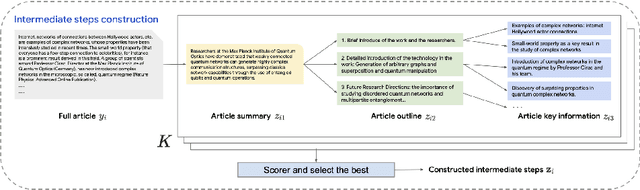
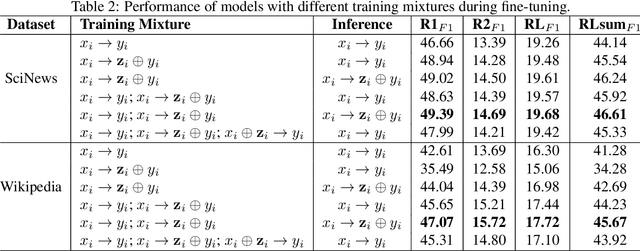
Generating high-quality, in-depth textual documents, such as academic papers, news articles, Wikipedia entries, and books, remains a significant challenge for Large Language Models (LLMs). In this paper, we propose to use planning to generate long form content. To achieve our goal, we generate intermediate steps via an auxiliary task that teaches the LLM to plan, reason and structure before generating the final text. Our main novelty lies in a single auxiliary task that does not require multiple rounds of prompting or planning. To overcome the scarcity of training data for these intermediate steps, we leverage LLMs to generate synthetic intermediate writing data such as outlines, key information and summaries from existing full articles. Our experiments demonstrate on two datasets from different domains, namely the scientific news dataset SciNews and Wikipedia datasets in KILT-Wiki and FreshWiki, that LLMs fine-tuned with the auxiliary task generate higher quality documents. We observed +2.5% improvement in ROUGE-Lsum, and a strong 3.60 overall win/loss ratio via human SxS evaluation, with clear wins in organization, relevance, and verifiability.
Outlier Weighed Layerwise Sparsity (OWL): A Missing Secret Sauce for Pruning LLMs to High Sparsity
Oct 08, 2023Large Language Models (LLMs), renowned for their remarkable performance, present a challenge due to their colossal model size when it comes to practical deployment. In response to this challenge, efforts have been directed toward the application of traditional network pruning techniques to LLMs, uncovering a massive number of parameters can be pruned in one-shot without hurting performance. Building upon insights gained from pre-LLM models, prevailing LLM pruning strategies have consistently adhered to the practice of uniformly pruning all layers at equivalent sparsity. However, this observation stands in contrast to the prevailing trends observed in the field of vision models, where non-uniform layerwise sparsity typically yields substantially improved results. To elucidate the underlying reasons for this disparity, we conduct a comprehensive analysis of the distribution of token features within LLMs. In doing so, we discover a strong correlation with the emergence of outliers, defined as features exhibiting significantly greater magnitudes compared to their counterparts in feature dimensions. Inspired by this finding, we introduce a novel LLM pruning methodology that incorporates a tailored set of non-uniform layerwise sparsity ratios specifically designed for LLM pruning, termed as Outlier Weighed Layerwise sparsity (OWL). The sparsity ratio of OWL is directly proportional to the outlier ratio observed within each layer, facilitating a more effective alignment between layerwise weight sparsity and outlier ratios. Our empirical evaluation, conducted across the LLaMA-V1 family and OPT, spanning various benchmarks, demonstrates the distinct advantages offered by OWL over previous methods. For instance, our approach exhibits a remarkable performance gain, surpassing the state-of-the-art Wanda and SparseGPT by 61.22 and 6.80 perplexity at a high sparsity level of 70%, respectively.
Scalable Exploration for Neural Online Learning to Rank with Perturbed Feedback
Jun 13, 2022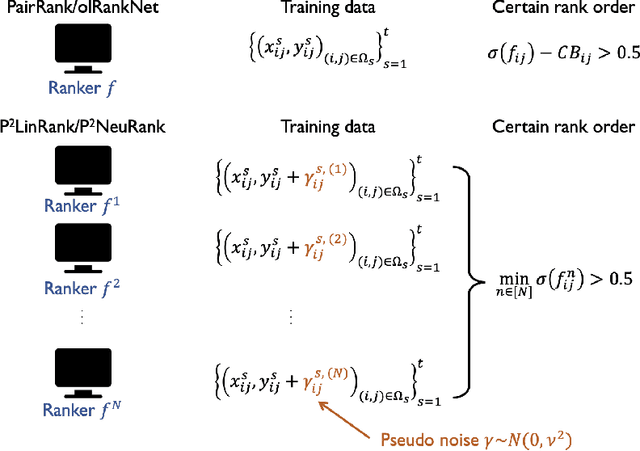
Deep neural networks (DNNs) demonstrate significant advantages in improving ranking performance in retrieval tasks. Driven by the recent technical developments in optimization and generalization of DNNs, learning a neural ranking model online from its interactions with users becomes possible. However, the required exploration for model learning has to be performed in the entire neural network parameter space, which is prohibitively expensive and limits the application of such online solutions in practice. In this work, we propose an efficient exploration strategy for online interactive neural ranker learning based on the idea of bootstrapping. Our solution employs an ensemble of ranking models trained with perturbed user click feedback. The proposed method eliminates explicit confidence set construction and the associated computational overhead, which enables the online neural rankers' training to be efficiently executed in practice with theoretical guarantees. Extensive comparisons with an array of state-of-the-art OL2R algorithms on two public learning to rank benchmark datasets demonstrate the effectiveness and computational efficiency of our proposed neural OL2R solution.
Learning Contextual Bandits Through Perturbed Rewards
Jan 24, 2022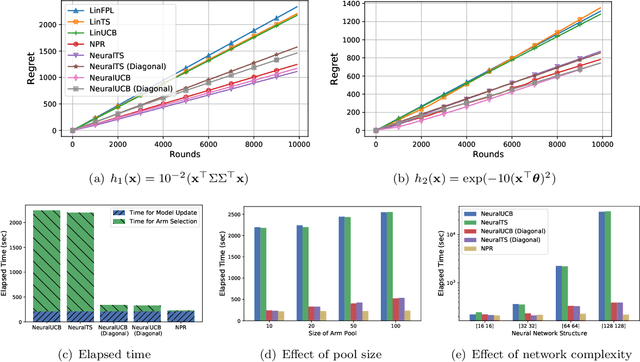

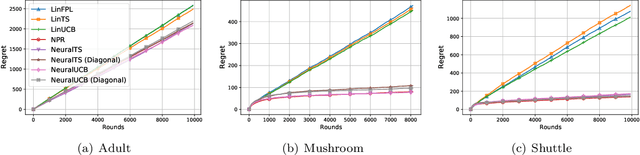
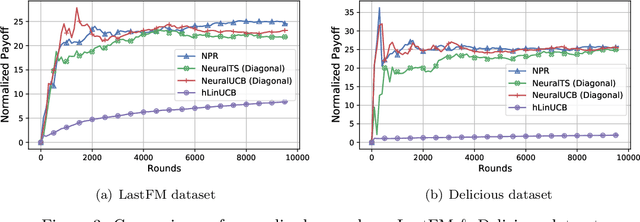
Thanks to the power of representation learning, neural contextual bandit algorithms demonstrate remarkable performance improvement against their classical counterparts. But because their exploration has to be performed in the entire neural network parameter space to obtain nearly optimal regret, the resulting computational cost is prohibitively high. We perturb the rewards when updating the neural network to eliminate the need of explicit exploration and the corresponding computational overhead. We prove that a $\tilde{O}(\tilde{d}\sqrt{T})$ regret upper bound is still achievable under standard regularity conditions, where $T$ is the number of rounds of interactions and $\tilde{d}$ is the effective dimension of a neural tangent kernel matrix. Extensive comparisons with several benchmark contextual bandit algorithms, including two recent neural contextual bandit models, demonstrate the effectiveness and computational efficiency of our proposed neural bandit algorithm.
Learning Neural Ranking Models Online from Implicit User Feedback
Jan 17, 2022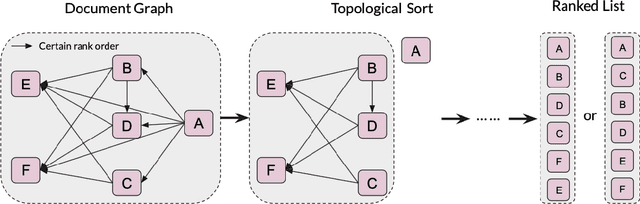
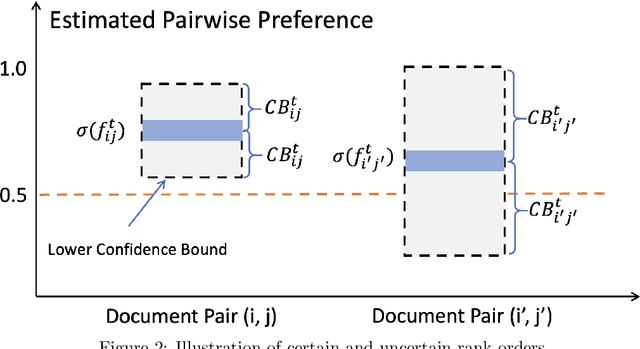

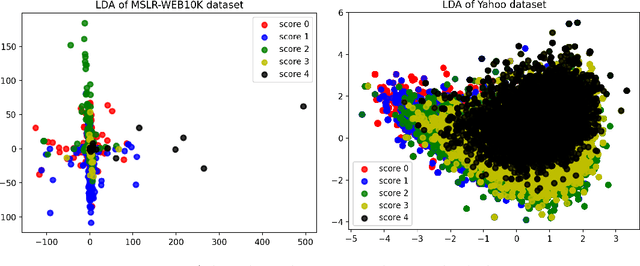
Existing online learning to rank (OL2R) solutions are limited to linear models, which are incompetent to capture possible non-linear relations between queries and documents. In this work, to unleash the power of representation learning in OL2R, we propose to directly learn a neural ranking model from users' implicit feedback (e.g., clicks) collected on the fly. We focus on RankNet and LambdaRank, due to their great empirical success and wide adoption in offline settings, and control the notorious explore-exploit trade-off based on the convergence analysis of neural networks using neural tangent kernel. Specifically, in each round of result serving, exploration is only performed on document pairs where the predicted rank order between the two documents is uncertain; otherwise, the ranker's predicted order will be followed in result ranking. We prove that under standard assumptions our OL2R solution achieves a gap-dependent upper regret bound of $O(\log^2(T))$, in which the regret is defined on the total number of mis-ordered pairs over $T$ rounds. Comparisons against an extensive set of state-of-the-art OL2R baselines on two public learning to rank benchmark datasets demonstrate the effectiveness of the proposed solution.
Calibrating Explore-Exploit Trade-off for Fair Online Learning to Rank
Nov 01, 2021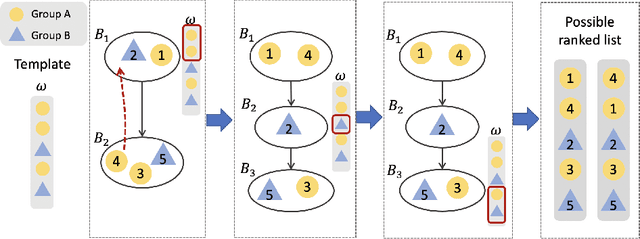


Online learning to rank (OL2R) has attracted great research interests in recent years, thanks to its advantages in avoiding expensive relevance labeling as required in offline supervised ranking model learning. Such a solution explores the unknowns (e.g., intentionally present selected results on top positions) to improve its relevance estimation. This however triggers concerns on its ranking fairness: different groups of items might receive differential treatments during the course of OL2R. But existing fair ranking solutions usually require the knowledge of result relevance or a performing ranker beforehand, which contradicts with the setting of OL2R and thus cannot be directly applied to guarantee fairness. In this work, we propose a general framework to achieve fairness defined by group exposure in OL2R. The key idea is to calibrate exploration and exploitation for fairness control, relevance learning and online ranking quality. In particular, when the model is exploring a set of results for relevance feedback, we confine the exploration within a subset of random permutations, where fairness across groups is maintained while the feedback is still unbiased. Theoretically we prove such a strategy introduces minimum distortion in OL2R's regret to obtain fairness. Extensive empirical analysis is performed on two public learning to rank benchmark datasets to demonstrate the effectiveness of the proposed solution compared to existing fair OL2R solutions.
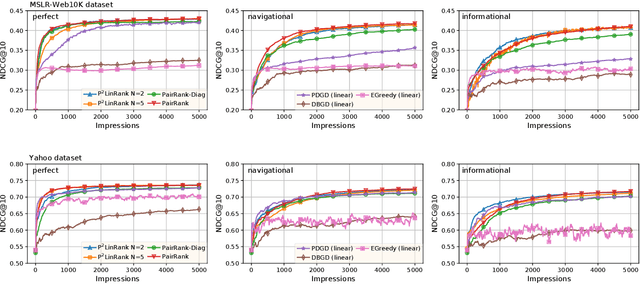
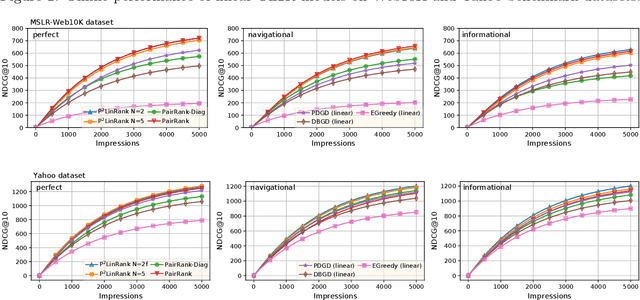
PairRank: Online Pairwise Learning to Rank by Divide-and-Conquer
Mar 03, 2021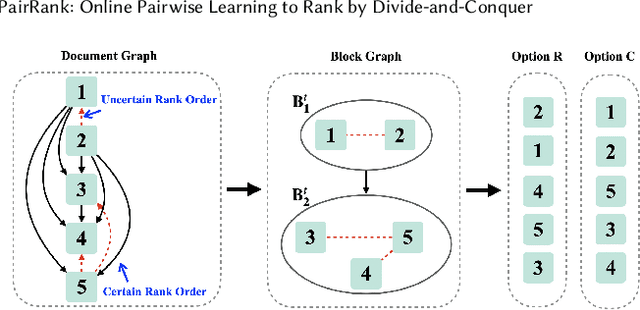

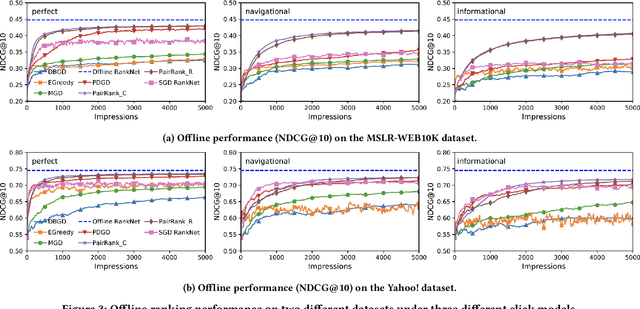
Online Learning to Rank (OL2R) eliminates the need of explicit relevance annotation by directly optimizing the rankers from their interactions with users. However, the required exploration drives it away from successful practices in offline learning to rank, which limits OL2R's empirical performance and practical applicability. In this work, we propose to estimate a pairwise learning to rank model online. In each round, candidate documents are partitioned and ranked according to the model's confidence on the estimated pairwise rank order, and exploration is only performed on the uncertain pairs of documents, i.e., \emph{divide-and-conquer}. Regret directly defined on the number of mis-ordered pairs is proven, which connects the online solution's theoretical convergence with its expected ranking performance. Comparisons against an extensive list of OL2R baselines on two public learning to rank benchmark datasets demonstrate the effectiveness of the proposed solution.
Active Collaborative Sensing for Energy Breakdown
Sep 02, 2019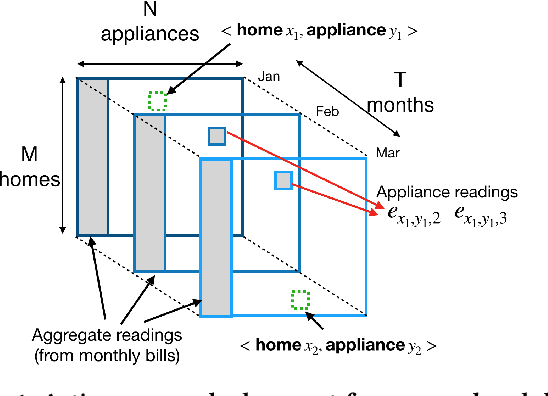
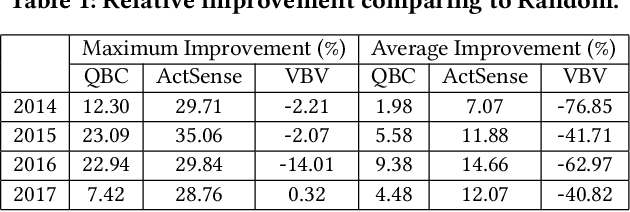
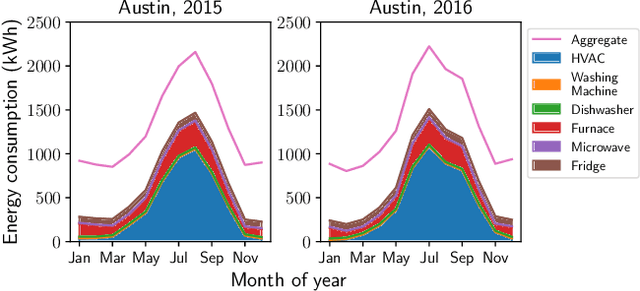
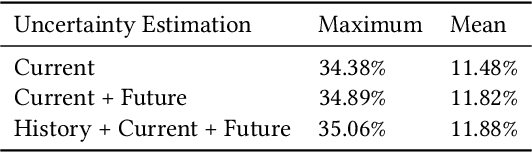
Residential homes constitute roughly one-fourth of the total energy usage worldwide. Providing appliance-level energy breakdown has been shown to induce positive behavioral changes that can reduce energy consumption by 15%. Existing approaches for energy breakdown either require hardware installation in every target home or demand a large set of energy sensor data available for model training. However, very few homes in the world have installed sub-meters (sensors measuring individual appliance energy); and the cost of retrofitting a home with extensive sub-metering eats into the funds available for energy saving retrofits. As a result, strategically deploying sensing hardware to maximize the reconstruction accuracy of sub-metered readings in non-instrumented homes while minimizing deployment costs becomes necessary and promising. In this work, we develop an active learning solution based on low-rank tensor completion for energy breakdown. We propose to actively deploy energy sensors to appliances from selected homes, with a goal to improve the prediction accuracy of the completed tensor with minimum sensor deployment cost. We empirically evaluate our approach on the largest public energy dataset collected in Austin, Texas, USA, from 2013 to 2017. The results show that our approach gives better performance with a fixed number of sensors installed when compared to the state-of-the-art, which is also proven by our theoretical analysis.
The FacT: Taming Latent Factor Models for Explainability with Factorization Trees
Jun 03, 2019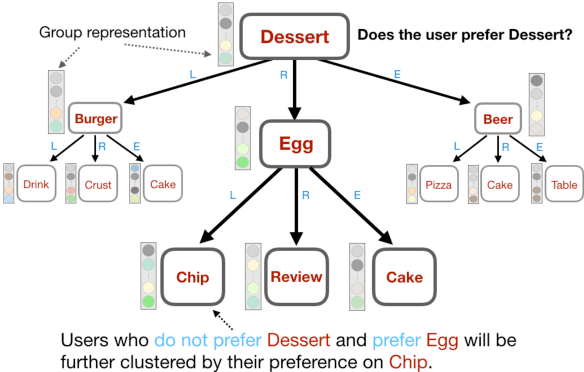

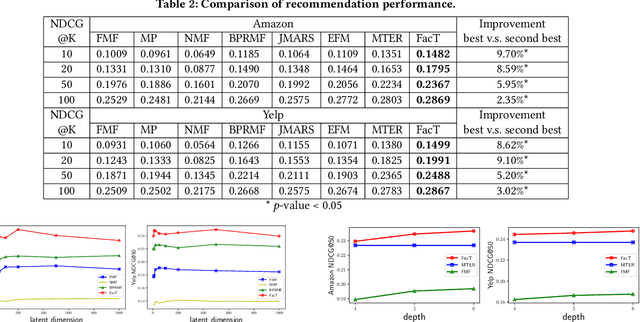
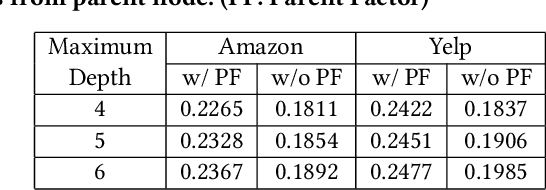
Latent factor models have achieved great success in personalized recommendations, but they are also notoriously difficult to explain. In this work, we integrate regression trees to guide the learning of latent factor models for recommendation, and use the learnt tree structure to explain the resulting latent factors. Specifically, we build regression trees on users and items respectively with user-generated reviews, and associate a latent profile to each node on the trees to represent users and items. With the growth of regression tree, the latent factors are gradually refined under the regularization imposed by the tree structure. As a result, we are able to track the creation of latent profiles by looking into the path of each factor on regression trees, which thus serves as an explanation for the resulting recommendations. Extensive experiments on two large collections of Amazon and Yelp reviews demonstrate the advantage of our model over several competitive baseline algorithms. Besides, our extensive user study also confirms the practical value of explainable recommendations generated by our model.
Explainable Recommendation via Multi-Task Learning in Opinionated Text Data
Jun 10, 2018
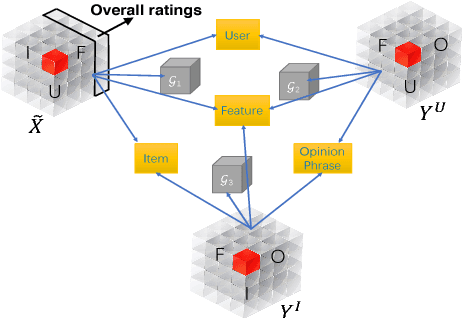
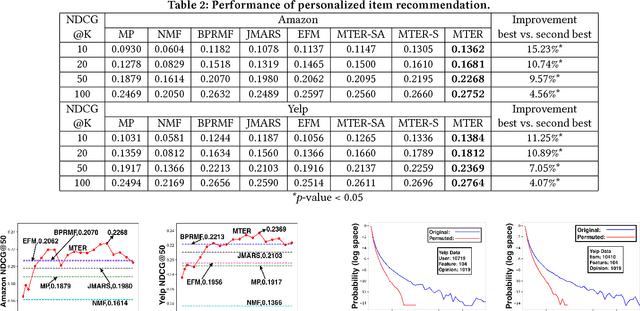
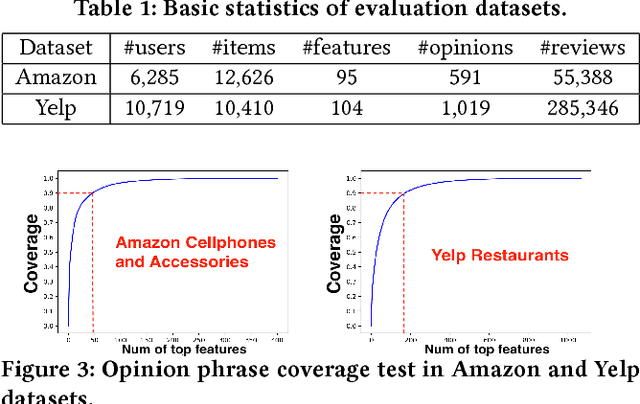
Explaining automatically generated recommendations allows users to make more informed and accurate decisions about which results to utilize, and therefore improves their satisfaction. In this work, we develop a multi-task learning solution for explainable recommendation. Two companion learning tasks of user preference modeling for recommendation} and \textit{opinionated content modeling for explanation are integrated via a joint tensor factorization. As a result, the algorithm predicts not only a user's preference over a list of items, i.e., recommendation, but also how the user would appreciate a particular item at the feature level, i.e., opinionated textual explanation. Extensive experiments on two large collections of Amazon and Yelp reviews confirmed the effectiveness of our solution in both recommendation and explanation tasks, compared with several existing recommendation algorithms. And our extensive user study clearly demonstrates the practical value of the explainable recommendations generated by our algorithm.