 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Collaborative Sensing for Energy Breakdown
Sep 02, 2019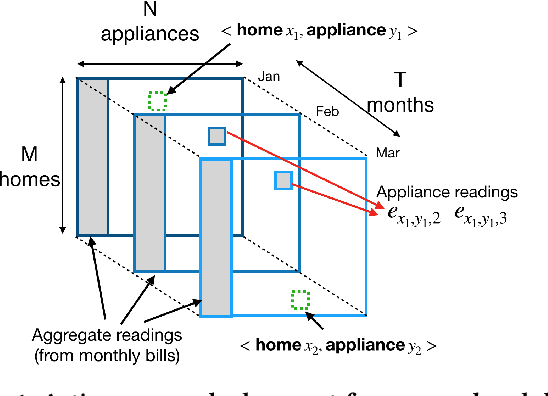
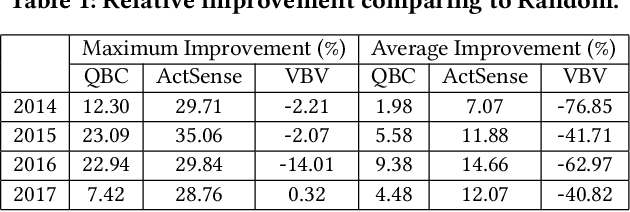
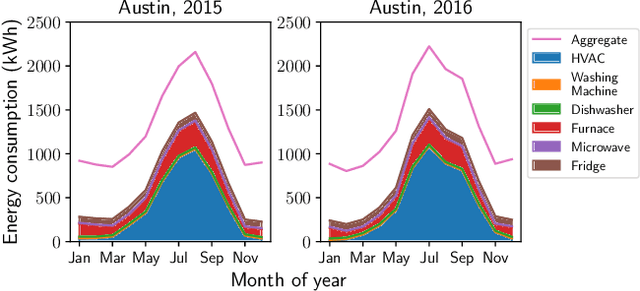
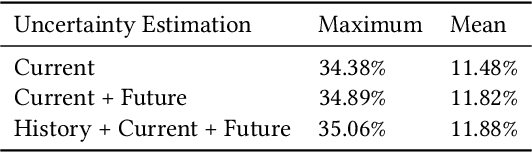
Residential homes constitute roughly one-fourth of the total energy usage worldwide. Providing appliance-level energy breakdown has been shown to induce positive behavioral changes that can reduce energy consumption by 15%. Existing approaches for energy breakdown either require hardware installation in every target home or demand a large set of energy sensor data available for model training. However, very few homes in the world have installed sub-meters (sensors measuring individual appliance energy); and the cost of retrofitting a home with extensive sub-metering eats into the funds available for energy saving retrofits. As a result, strategically deploying sensing hardware to maximize the reconstruction accuracy of sub-metered readings in non-instrumented homes while minimizing deployment costs becomes necessary and promising. In this work, we develop an active learning solution based on low-rank tensor completion for energy breakdown. We propose to actively deploy energy sensors to appliances from selected homes, with a goal to improve the prediction accuracy of the completed tensor with minimum sensor deployment cost. We empirically evaluate our approach on the largest public energy dataset collected in Austin, Texas, USA, from 2013 to 2017. The results show that our approach gives better performance with a fixed number of sensors installed when compared to the state-of-the-art, which is also proven by our theoretical analysis.
How good is good enough? Re-evaluating the bar for energy disaggregation
Oct 26, 2015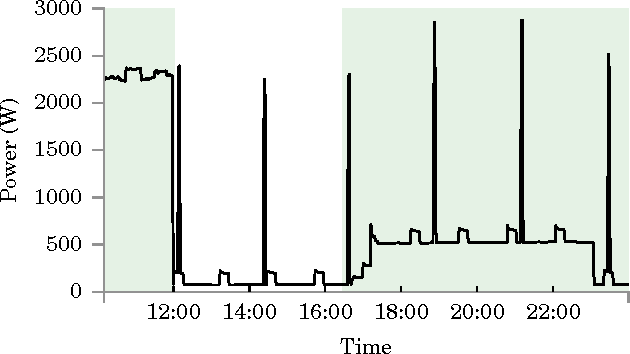
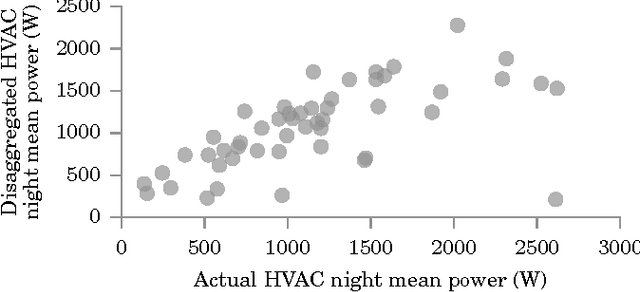
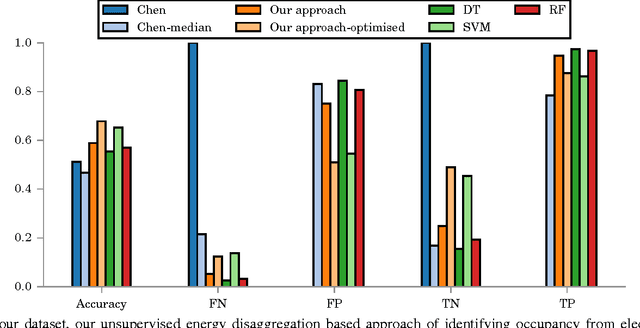
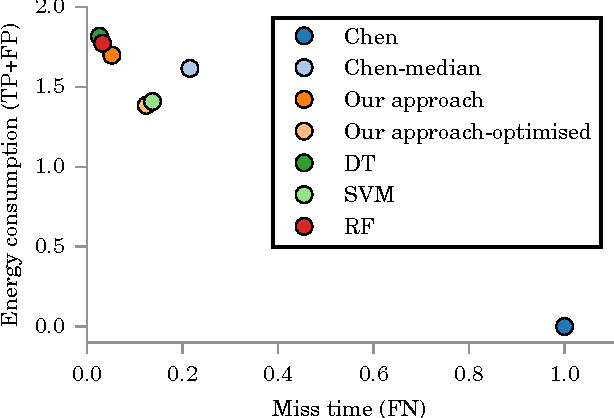
Since the early 1980s, the research community has developed ever more sophisticated algorithms for the problem of energy disaggregation, but despite decades of research, there is still a dearth of applications with demonstrated value. In this work, we explore a question that is highly pertinent to this research community: how good does energy disaggregation need to be in order to infer characteristics of a household? We present novel techniques that use unsupervised energy disaggregation to predict both household occupancy and static properties of the household such as size of the home and number of occupants. Results show that basic disaggregation approaches performs up to 30% better at occupancy estimation than using aggregate power data alone, and are up to 10% better at estimating static household characteristics. These results show that even rudimentary energy disaggregation techniques are sufficient for improved inference of household characteristics. To conclude, we re-evaluate the bar set by the community for energy disaggregation accuracy and try to answer the question "how good is good enough?"
Neighbourhood NILM: A Big-data Approach to Household Energy Disaggregation
Oct 26, 2015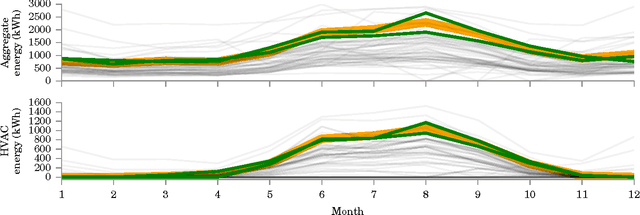
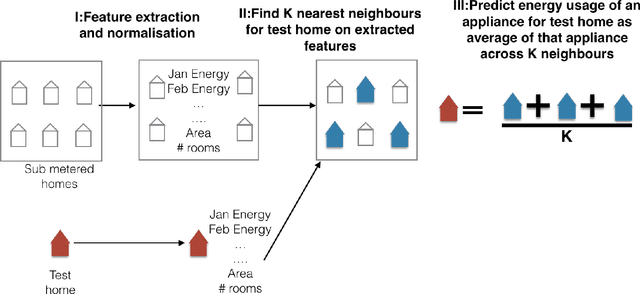
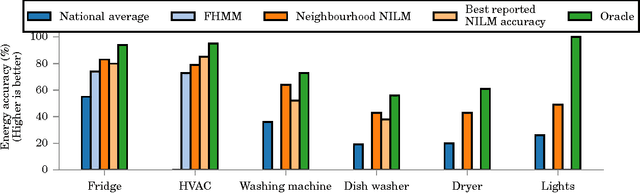

In this paper, we investigate whether "big-data" is more valuable than "precise" data for the problem of energy disaggregation: the process of breaking down aggregate energy usage on a per-appliance basis. Existing techniques for disaggregation rely on energy metering at a resolution of 1 minute or higher, but most power meters today only provide a reading once per month, and at most once every 15 minutes. In this paper, we propose a new technique called Neighbourhood NILM that leverages data from 'neighbouring' homes to disaggregate energy given only a single energy reading per month. The key intuition behind our approach is that 'similar' homes have 'similar' energy consumption on a per-appliance basis. Neighbourhood NILM matches every home with a set of 'neighbours' that have direct submetering infrastructure, i.e. power meters on individual circuits or loads. Many such homes already exist. Then, it estimates the appliance-level energy consumption of the target home to be the average of its K neighbours. We evaluate this approach using 25 homes and results show that our approach gives comparable or better disaggregation in comparison to state-of-the-art accuracy reported in the literature that depend on manual model training, high frequency power metering, or both. Results show that Neighbourhood NILM can achieve 83% and 79% accuracy disaggregating fridge and heating/cooling loads, compared to 74% and 73% for a technique called FHMM. Furthermore, it achieves up to 64% accuracy on washing machine, dryer, dishwasher, and lighting loads, which is higher than previously reported results. Many existing techniques are not able to disaggregate these loads at all. These results indicate a potentially substantial advantage to installing submetering infrastructure in a select few homes rather than installing new high-frequency smart metering infrastructure in all homes.
Sensor-Type Classification in Buildings
Sep 01, 2015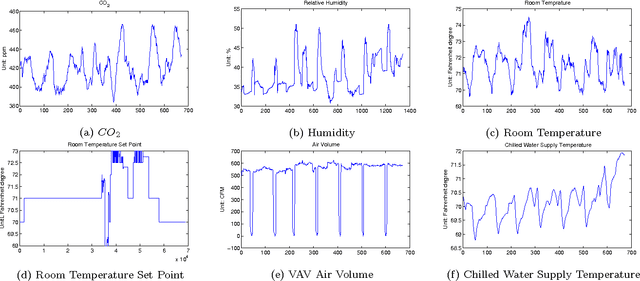

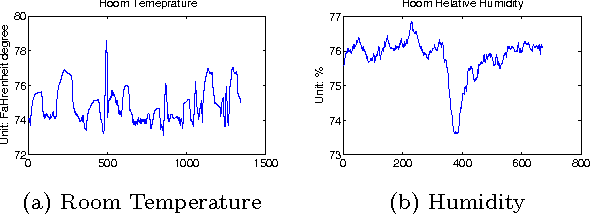
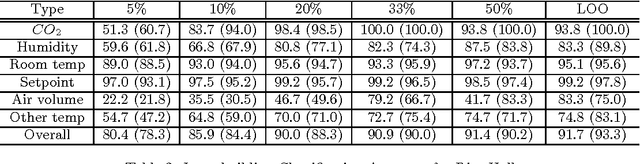
Many sensors/meters are deployed in commercial buildings to monitor and optimize their performance. However, because sensor metadata is inconsistent across buildings, software-based solutions are tightly coupled to the sensor metadata conventions (i.e. schemas and naming) for each building. Running the same software across buildings requires significant integration effort. Metadata normalization is critical for scaling the deployment process and allows us to decouple building-specific conventions from the code written for building applications. It also allows us to deal with missing metadata. One important aspect of normalization is to differentiate sensors by the typeof phenomena being observed. In this paper, we propose a general, simple, yet effective classification scheme to differentiate sensors in buildings by type. We perform ensemble learning on data collected from over 2000 sensor streams in two buildings. Our approach is able to achieve more than 92% accuracy for classification within buildings and more than 82% accuracy for across buildings. We also introduce a method for identifying potential misclassified streams. This is important because it allows us to identify opportunities to attain more input from experts -- input that could help improve classification accuracy when ground truth is unavailable. We show that by adjusting a threshold value we are able to identify at least 30% of the misclassified instances.