 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeighbourhood NILM: A Big-data Approach to Household Energy Disaggregation
Paper and Code
Oct 26, 2015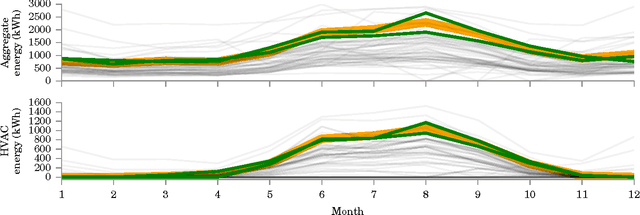
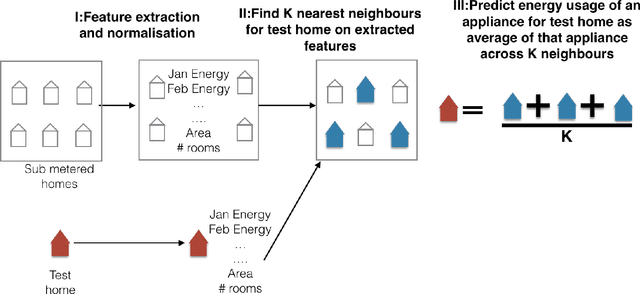
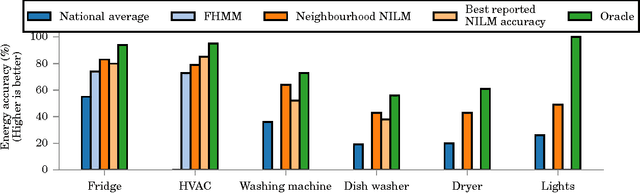

In this paper, we investigate whether "big-data" is more valuable than "precise" data for the problem of energy disaggregation: the process of breaking down aggregate energy usage on a per-appliance basis. Existing techniques for disaggregation rely on energy metering at a resolution of 1 minute or higher, but most power meters today only provide a reading once per month, and at most once every 15 minutes. In this paper, we propose a new technique called Neighbourhood NILM that leverages data from 'neighbouring' homes to disaggregate energy given only a single energy reading per month. The key intuition behind our approach is that 'similar' homes have 'similar' energy consumption on a per-appliance basis. Neighbourhood NILM matches every home with a set of 'neighbours' that have direct submetering infrastructure, i.e. power meters on individual circuits or loads. Many such homes already exist. Then, it estimates the appliance-level energy consumption of the target home to be the average of its K neighbours. We evaluate this approach using 25 homes and results show that our approach gives comparable or better disaggregation in comparison to state-of-the-art accuracy reported in the literature that depend on manual model training, high frequency power metering, or both. Results show that Neighbourhood NILM can achieve 83% and 79% accuracy disaggregating fridge and heating/cooling loads, compared to 74% and 73% for a technique called FHMM. Furthermore, it achieves up to 64% accuracy on washing machine, dryer, dishwasher, and lighting loads, which is higher than previously reported results. Many existing techniques are not able to disaggregate these loads at all. These results indicate a potentially substantial advantage to installing submetering infrastructure in a select few homes rather than installing new high-frequency smart metering infrastructure in all homes.