 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThermEval: A Structured Benchmark for Evaluation of Vision-Language Models on Thermal Imagery
Feb 16, 2026Vision language models (VLMs) achieve strong performance on RGB imagery, but they do not generalize to thermal images. Thermal sensing plays a critical role in settings where visible light fails, including nighttime surveillance, search and rescue, autonomous driving, and medical screening. Unlike RGB imagery, thermal images encode physical temperature rather than color or texture, requiring perceptual and reasoning capabilities that existing RGB-centric benchmarks do not evaluate. We introduce ThermEval-B, a structured benchmark of approximately 55,000 thermal visual question answering pairs designed to assess the foundational primitives required for thermal vision language understanding. ThermEval-B integrates public datasets with our newly collected ThermEval-D, the first dataset to provide dense per-pixel temperature maps with semantic body-part annotations across diverse indoor and outdoor environments. Evaluating 25 open-source and closed-source VLMs, we find that models consistently fail at temperature-grounded reasoning, degrade under colormap transformations, and default to language priors or fixed responses, with only marginal gains from prompting or supervised fine-tuning. These results demonstrate that thermal understanding requires dedicated evaluation beyond RGB-centric assumptions, positioning ThermEval as a benchmark to drive progress in thermal vision language modeling.
Space to Policy: Scalable Brick Kiln Detection and Automatic Compliance Monitoring with Geospatial Data
Dec 05, 2024



Air pollution kills 7 million people annually. The brick kiln sector significantly contributes to economic development but also accounts for 8-14\% of air pollution in India. Policymakers have implemented compliance measures to regulate brick kilns. Emission inventories are critical for air quality modeling and source apportionment studies. However, the largely unorganized nature of the brick kiln sector necessitates labor-intensive survey efforts for monitoring. Recent efforts by air quality researchers have relied on manual annotation of brick kilns using satellite imagery to build emission inventories, but this approach lacks scalability. Machine-learning-based object detection methods have shown promise for detecting brick kilns; however, previous studies often rely on costly high-resolution imagery and fail to integrate with governmental policies. In this work, we developed a scalable machine-learning pipeline that detected and classified 30638 brick kilns across five states in the Indo-Gangetic Plain using free, moderate-resolution satellite imagery from Planet Labs. Our detections have a high correlation with on-ground surveys. We performed automated compliance analysis based on government policies. In the Delhi airshed, stricter policy enforcement has led to the adoption of efficient brick kiln technologies. This study highlights the need for inclusive policies that balance environmental sustainability with the livelihoods of workers.
Benchmarking Active Learning for NILM
Nov 24, 2024



Non-intrusive load monitoring (NILM) focuses on disaggregating total household power consumption into appliance-specific usage. Many advanced NILM methods are based on neural networks that typically require substantial amounts of labeled appliance data, which can be challenging and costly to collect in real-world settings. We hypothesize that appliance data from all households does not uniformly contribute to NILM model improvements. Thus, we propose an active learning approach to selectively install appliance monitors in a limited number of houses. This work is the first to benchmark the use of active learning for strategically selecting appliance-level data to optimize NILM performance. We first develop uncertainty-aware neural networks for NILM and then install sensors in homes where disaggregation uncertainty is highest. Benchmarking our method on the publicly available Pecan Street Dataport dataset, we demonstrate that our approach significantly outperforms a standard random baseline and achieves performance comparable to models trained on the entire dataset. Using this approach, we achieve comparable NILM accuracy with approximately 30% of the data, and for a fixed number of sensors, we observe up to a 2x reduction in disaggregation errors compared to random sampling.
VayuBuddy: an LLM-Powered Chatbot to Democratize Air Quality Insights
Nov 16, 2024



Nearly 6.7 million lives are lost due to air pollution every year. While policymakers are working on the mitigation strategies, public awareness can help reduce the exposure to air pollution. Air pollution data from government-installed sensors is often publicly available in raw format, but there is a non-trivial barrier for various stakeholders in deriving meaningful insights from that data. In this work, we present VayuBuddy, a Large Language Model (LLM)-powered chatbot system to reduce the barrier between the stakeholders and air quality sensor data. VayuBuddy receives the questions in natural language, analyses the structured sensory data with a LLM-generated Python code and provides answers in natural language. We use the data from Indian government air quality sensors. We benchmark the capabilities of 7 LLMs on 45 diverse question-answer pairs prepared by us. Additionally, VayuBuddy can also generate visual analysis such as line-plots, map plot, bar charts and many others from the sensory data as we demonstrate in this work.
SpiroActive: Active Learning for Efficient Data Acquisition for Spirometry
Oct 30, 2024



Respiratory illnesses are a significant global health burden. Respiratory illnesses, primarily Chronic obstructive pulmonary disease (COPD), is the seventh leading cause of poor health worldwide and the third leading cause of death worldwide, causing 3.23 million deaths in 2019, necessitating early identification and diagnosis for effective mitigation. Among the diagnostic tools employed, spirometry plays a crucial role in detecting respiratory abnormalities. However, conventional clinical spirometry methods often entail considerable costs and practical limitations like the need for specialized equipment, trained personnel, and a dedicated clinical setting, making them less accessible. To address these challenges, wearable spirometry technologies have emerged as promising alternatives, offering accurate, cost-effective, and convenient solutions. The development of machine learning models for wearable spirometry heavily relies on the availability of high-quality ground truth spirometry data, which is a laborious and expensive endeavor. In this research, we propose using active learning, a sub-field of machine learning, to mitigate the challenges associated with data collection and labeling. By strategically selecting samples from the ground truth spirometer, we can mitigate the need for resource-intensive data collection. We present evidence that models trained on small subsets obtained through active learning achieve comparable/better results than models trained on the complete dataset.
Eye in the Sky: Detection and Compliance Monitoring of Brick Kilns using Satellite Imagery
Jun 15, 2024



Air pollution kills 7 million people annually. The brick manufacturing industry accounts for 8%-14% of air pollution in the densely populated Indo-Gangetic plain. Due to the unorganized nature of brick kilns, policy violation detection, such as proximity to human habitats, remains challenging. While previous studies have utilized computer vision-based machine learning methods for brick kiln detection from satellite imagery, they utilize proprietary satellite data and rarely focus on compliance with government policies. In this research, we introduce a scalable framework for brick kiln detection and automatic compliance monitoring. We use Google Maps Static API to download the satellite imagery followed by the YOLOv8x model for detection. We identified and hand-verified 19579 new brick kilns across 9 states within the Indo-Gangetic plain. Furthermore, we automate and test the compliance to the policies affecting human habitats, rivers and hospitals. Our results show that a substantial number of brick kilns do not meet the compliance requirements. Our framework offers a valuable tool for governments worldwide to automate and enforce policy regulations for brick kilns, addressing critical environmental and public health concerns.
Scalable Methods for Brick Kiln Detection and Compliance Monitoring from Satellite Imagery: A Deployment Case Study in India
Feb 21, 2024



Air pollution kills 7 million people annually. Brick manufacturing industry is the second largest consumer of coal contributing to 8%-14% of air pollution in Indo-Gangetic plain (highly populated tract of land in the Indian subcontinent). As brick kilns are an unorganized sector and present in large numbers, detecting policy violations such as distance from habitat is non-trivial. Air quality and other domain experts rely on manual human annotation to maintain brick kiln inventory. Previous work used computer vision based machine learning methods to detect brick kilns from satellite imagery but they are limited to certain geographies and labeling the data is laborious. In this paper, we propose a framework to deploy a scalable brick kiln detection system for large countries such as India and identify 7477 new brick kilns from 28 districts in 5 states in the Indo-Gangetic plain. We then showcase efficient ways to check policy violations such as high spatial density of kilns and abnormal increase over time in a region. We show that 90% of brick kilns in Delhi-NCR violate a density-based policy. Our framework can be directly adopted by the governments across the world to automate the policy regulations around brick kilns.
Challenges in Gaussian Processes for Non Intrusive Load Monitoring
Nov 18, 2022



Non-intrusive load monitoring (NILM) or energy disaggregation aims to break down total household energy consumption into constituent appliances. Prior work has shown that providing an energy breakdown can help people save up to 15\% of energy. In recent years, deep neural networks (deep NNs) have made remarkable progress in the domain of NILM. In this paper, we demonstrate the performance of Gaussian Processes (GPs) for NILM. We choose GPs due to three main reasons: i) GPs inherently model uncertainty; ii) equivalence between infinite NNs and GPs; iii) by appropriately designing the kernel we can incorporate domain expertise. We explore and present the challenges of applying our GP approaches to NILM.
Deep Gaussian Processes for Air Quality Inference
Nov 18, 2022
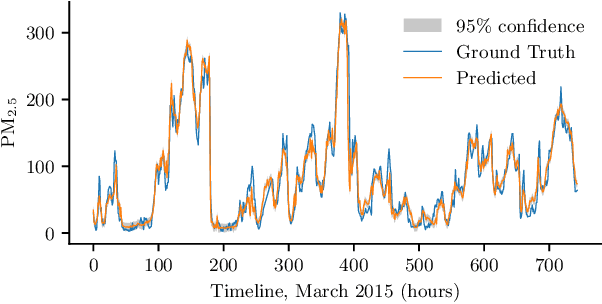
Air pollution kills around 7 million people annually, and approximately 2.4 billion people are exposed to hazardous air pollution. Accurate, fine-grained air quality (AQ) monitoring is essential to control and reduce pollution. However, AQ station deployment is sparse, and thus air quality inference for unmonitored locations is crucial. Conventional interpolation methods fail to learn the complex AQ phenomena. This work demonstrates that Deep Gaussian Process models (DGPs) are a promising model for the task of AQ inference. We implement Doubly Stochastic Variational Inference, a DGP algorithm, and show that it performs comparably to the state-of-the-art models.
Merged-GHCIDR: Geometrical Approach to Reduce Image Data
Sep 06, 2022
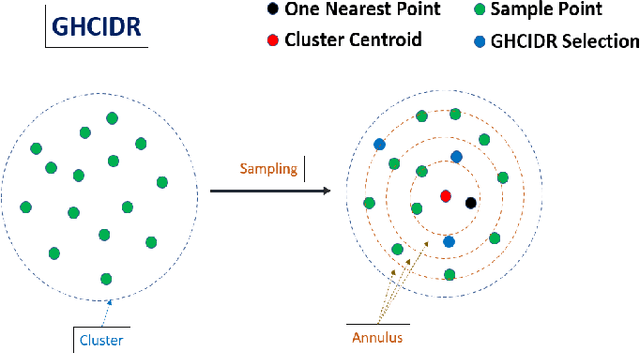
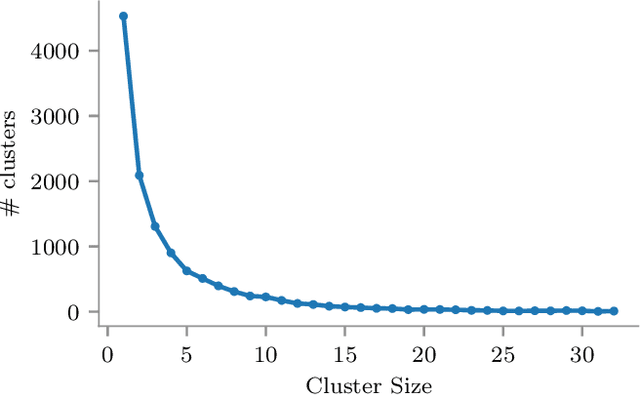
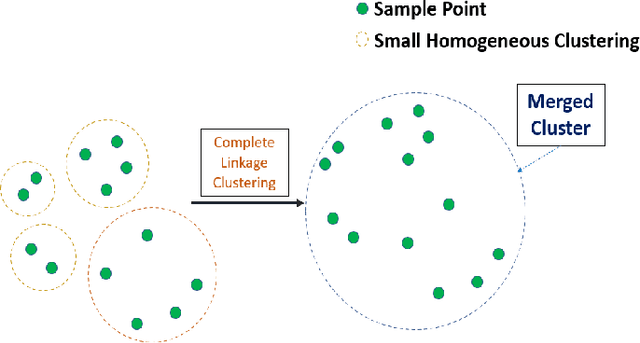
The computational resources required to train a model have been increasing since the inception of deep networks. Training neural networks on massive datasets have become a challenging and time-consuming task. So, there arises a need to reduce the dataset without compromising the accuracy. In this paper, we present novel variations of an earlier approach called reduction through homogeneous clustering for reducing dataset size. The proposed methods are based on the idea of partitioning the dataset into homogeneous clusters and selecting images that contribute significantly to the accuracy. We propose two variations: Geometrical Homogeneous Clustering for Image Data Reduction (GHCIDR) and Merged-GHCIDR upon the baseline algorithm - Reduction through Homogeneous Clustering (RHC) to achieve better accuracy and training time. The intuition behind GHCIDR involves selecting data points by cluster weights and geometrical distribution of the training set. Merged-GHCIDR involves merging clusters having the same labels using complete linkage clustering. We used three deep learning models- Fully Connected Networks (FCN), VGG1, and VGG16. We experimented with the two variants on four datasets- MNIST, CIFAR10, Fashion-MNIST, and Tiny-Imagenet. Merged-GHCIDR with the same percentage reduction as RHC showed an increase of 2.8%, 8.9%, 7.6% and 3.5% accuracy on MNIST, Fashion-MNIST, CIFAR10, and Tiny-Imagenet, respectively.