 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometrical Homogeneous Clustering for Image Data Reduction
Paper and Code
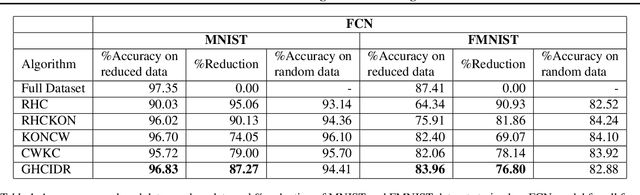
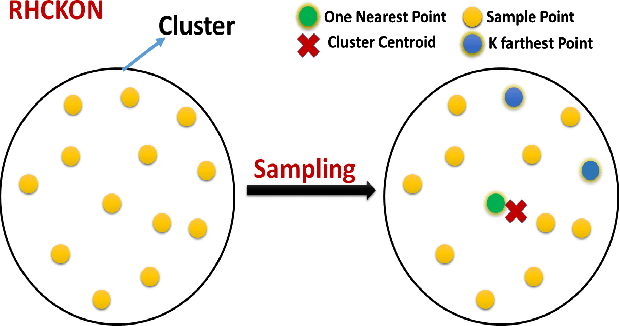
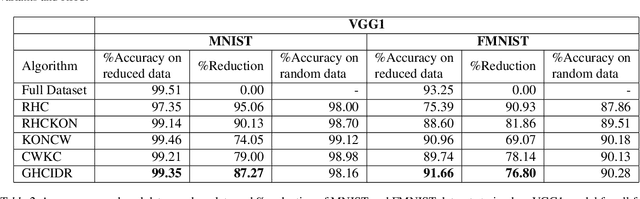
In this paper, we present novel variations of an earlier approach called homogeneous clustering algorithm for reducing dataset size. The intuition behind the approaches proposed in this paper is to partition the dataset into homogeneous clusters and select some images which contribute significantly to the accuracy. Selected images are the proper subset of the training data and thus are human-readable. We propose four variations upon the baseline algorithm-RHC. The intuition behind the first approach, RHCKON, is that the boundary points contribute significantly towards the representation of clusters. It involves selecting k farthest and one nearest neighbour of the centroid of the clusters. In the following two approaches (KONCW and CWKC), we introduce the concept of cluster weights. They are based on the fact that larger clusters contribute more than smaller sized clusters. The final variation is GHCIDR which selects points based on the geometrical aspect of data distribution. We performed the experiments on two deep learning models- Fully Connected Networks (FCN) and VGG1. We experimented with the four variants on three datasets- MNIST, CIFAR10, and Fashion-MNIST. We found that GHCIDR gave the best accuracy of 99.35%, 81.10%, and 91.66% and a training data reduction of 87.27%, 32.34%, and 76.80% on MNIST, CIFAR10, and Fashion-MNIST respectively.