 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGHOST: Ground-projected Hypotheses from Observed Structure-from-Motion Trajectories
Mar 21, 2026We present a scalable self-supervised approach for segmenting feasible vehicle trajectories from monocular images for autonomous driving in complex urban environments. Leveraging large-scale dashcam videos, we treat recorded ego-vehicle motion as implicit supervision and recover camera trajectories via monocular structure-from-motion, projecting them onto the ground plane to generate spatial masks of traversed regions without manual annotation. These automatically generated labels are used to train a deep segmentation network that predicts motion-conditioned path proposals from a single RGB image at run time, without explicit modeling of road or lane markings. Trained on diverse, unconstrained internet data, the model implicitly captures scene layout, lane topology, and intersection structure, and generalizes across varying camera configurations. We evaluate our approach on NuScenes, demonstrating reliable trajectory prediction, and further show transfer to an electric scooter platform through light fine-tuning. Our results indicate that large-scale ego-motion distillation yields structured and generalizable path proposals beyond the demonstrated trajectory, enabling trajectory hypothesis estimation via image segmentation.
GAMMS: Graph based Adversarial Multiagent Modeling Simulator
Feb 04, 2026As intelligent systems and multi-agent coordination become increasingly central to real-world applications, there is a growing need for simulation tools that are both scalable and accessible. Existing high-fidelity simulators, while powerful, are often computationally expensive and ill-suited for rapid prototyping or large-scale agent deployments. We present GAMMS (Graph based Adversarial Multiagent Modeling Simulator), a lightweight yet extensible simulation framework designed to support fast development and evaluation of agent behavior in environments that can be represented as graphs. GAMMS emphasizes five core objectives: scalability, ease of use, integration-first architecture, fast visualization feedback, and real-world grounding. It enables efficient simulation of complex domains such as urban road networks and communication systems, supports integration with external tools (e.g., machine learning libraries, planning solvers), and provides built-in visualization with minimal configuration. GAMMS is agnostic to policy type, supporting heuristic, optimization-based, and learning-based agents, including those using large language models. By lowering the barrier to entry for researchers and enabling high-performance simulations on standard hardware, GAMMS facilitates experimentation and innovation in multi-agent systems, autonomous planning, and adversarial modeling. The framework is open-source and available at https://github.com/GAMMSim/GAMMS/
Merging and Disentangling Views in Visual Reinforcement Learning for Robotic Manipulation
May 07, 2025Vision is well-known for its use in manipulation, especially using visual servoing. To make it robust, multiple cameras are needed to expand the field of view. That is computationally challenging. Merging multiple views and using Q-learning allows the design of more effective representations and optimization of sample efficiency. Such a solution might be expensive to deploy. To mitigate this, we introduce a Merge And Disentanglement (MAD) algorithm that efficiently merges views to increase sample efficiency while augmenting with single-view features to allow lightweight deployment and ensure robust policies. We demonstrate the efficiency and robustness of our approach using Meta-World and ManiSkill3. For project website and code, see https://aalmuzairee.github.io/mad
SonoSAMTrack -- Segment and Track Anything on Ultrasound Images
Nov 07, 2023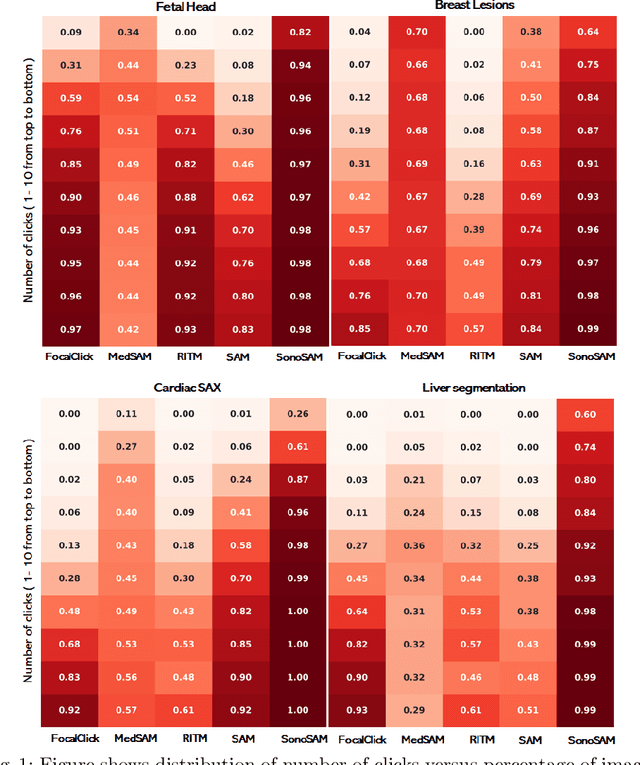
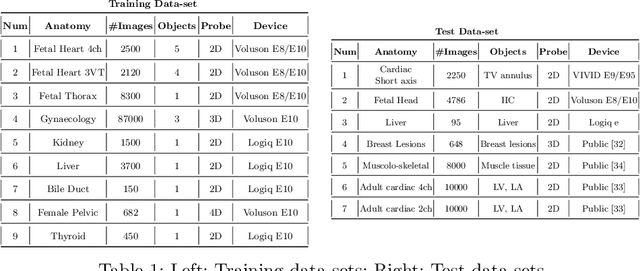
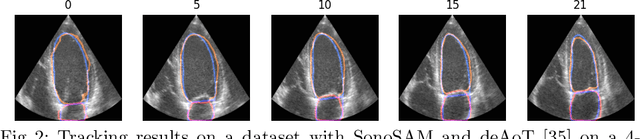
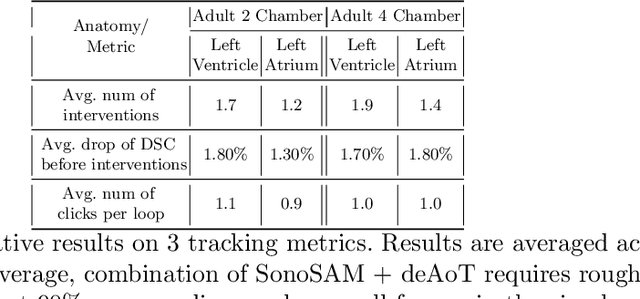
In this paper, we present SonoSAM - a promptable foundational model for segmenting objects of interest on ultrasound images, followed by state of the art tracking model to perform segmentations on 2D+t and 3D ultrasound datasets. Fine-tuned exclusively on a rich, diverse set of objects from $\approx200$k ultrasound image-mask pairs, SonoSAM demonstrates state-of-the-art performance on $8$ unseen ultrasound data-sets, outperforming competing methods by a significant margin on all metrics of interest. SonoSAM achieves average dice similarity score of $>90\%$ on almost all test data-sets within 2-6 clicks on an average, making it a valuable tool for annotating ultrasound images. We also extend SonoSAM to 3-D (2-D +t) applications and demonstrate superior performance making it a valuable tool for generating dense annotations from ultrasound cine-loops. Further, to increase practical utility of SonoSAM, we propose a two-step process of fine-tuning followed by knowledge distillation to a smaller footprint model without comprising the performance. We present detailed qualitative and quantitative comparisons of SonoSAM with state-of-the-art methods showcasing efficacy of SonoSAM as one of the first reliable, generic foundational model for ultrasound.
Prescribed Fire Modeling using Knowledge-Guided Machine Learning for Land Management
Oct 02, 2023In recent years, the increasing threat of devastating wildfires has underscored the need for effective prescribed fire management. Process-based computer simulations have traditionally been employed to plan prescribed fires for wildfire prevention. However, even simplified process models like QUIC-Fire are too compute-intensive to be used for real-time decision-making, especially when weather conditions change rapidly. Traditional ML methods used for fire modeling offer computational speedup but struggle with physically inconsistent predictions, biased predictions due to class imbalance, biased estimates for fire spread metrics (e.g., burned area, rate of spread), and generalizability in out-of-distribution wind conditions. This paper introduces a novel machine learning (ML) framework that enables rapid emulation of prescribed fires while addressing these concerns. By incorporating domain knowledge, the proposed method helps reduce physical inconsistencies in fuel density estimates in data-scarce scenarios. To overcome the majority class bias in predictions, we leverage pre-existing source domain data to augment training data and learn the spread of fire more effectively. Finally, we overcome the problem of biased estimation of fire spread metrics by incorporating a hierarchical modeling structure to capture the interdependence in fuel density and burned area. Notably, improvement in fire metric (e.g., burned area) estimates offered by our framework makes it useful for fire managers, who often rely on these fire metric estimates to make decisions about prescribed burn management. Furthermore, our framework exhibits better generalization capabilities than the other ML-based fire modeling methods across diverse wind conditions and ignition patterns.
Effectiveness of the Recent Advances in Capsule Networks
Oct 11, 2022


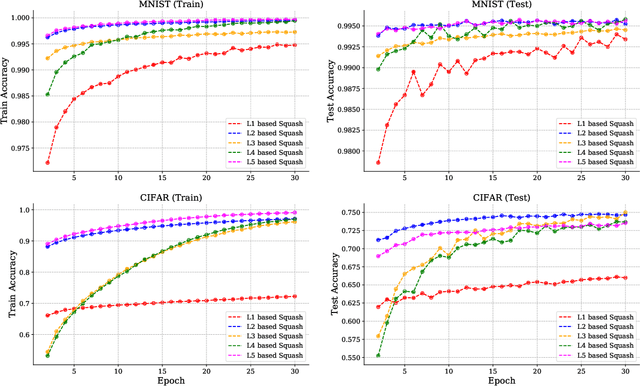
Convolutional neural networks (CNNs) have revolutionized the field of deep neural networks. However, recent research has shown that CNNs fail to generalize under various conditions and hence the idea of capsules was introduced in 2011, though the real surge of research started from 2017. In this paper, we present an overview of the recent advances in capsule architecture and routing mechanisms. In addition, we find that the relative focus in recent literature is on modifying routing procedure or architecture as a whole but the study of other finer components, specifically, squash function is wanting. Thus, we also present some new insights regarding the effect of squash functions in performance of the capsule networks. Finally, we conclude by discussing and proposing possible opportunities in the field of capsule networks.
Merged-GHCIDR: Geometrical Approach to Reduce Image Data
Sep 06, 2022
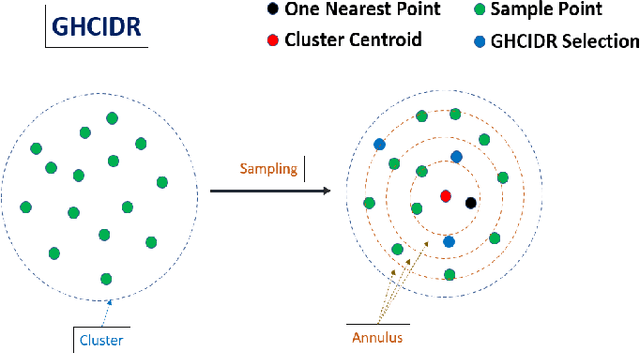
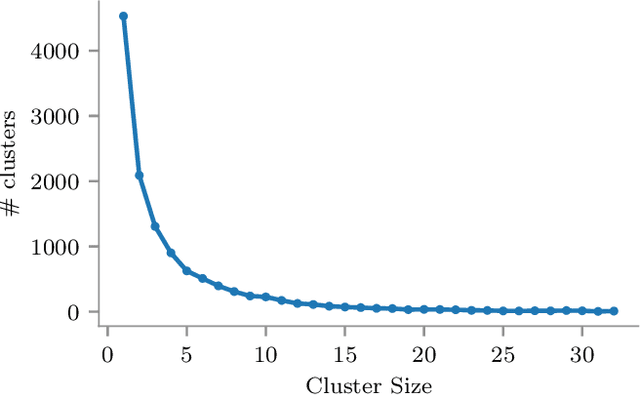
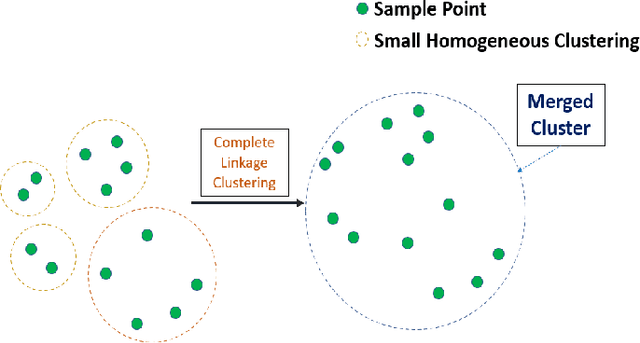
The computational resources required to train a model have been increasing since the inception of deep networks. Training neural networks on massive datasets have become a challenging and time-consuming task. So, there arises a need to reduce the dataset without compromising the accuracy. In this paper, we present novel variations of an earlier approach called reduction through homogeneous clustering for reducing dataset size. The proposed methods are based on the idea of partitioning the dataset into homogeneous clusters and selecting images that contribute significantly to the accuracy. We propose two variations: Geometrical Homogeneous Clustering for Image Data Reduction (GHCIDR) and Merged-GHCIDR upon the baseline algorithm - Reduction through Homogeneous Clustering (RHC) to achieve better accuracy and training time. The intuition behind GHCIDR involves selecting data points by cluster weights and geometrical distribution of the training set. Merged-GHCIDR involves merging clusters having the same labels using complete linkage clustering. We used three deep learning models- Fully Connected Networks (FCN), VGG1, and VGG16. We experimented with the two variants on four datasets- MNIST, CIFAR10, Fashion-MNIST, and Tiny-Imagenet. Merged-GHCIDR with the same percentage reduction as RHC showed an increase of 2.8%, 8.9%, 7.6% and 3.5% accuracy on MNIST, Fashion-MNIST, CIFAR10, and Tiny-Imagenet, respectively.
Geometrical Homogeneous Clustering for Image Data Reduction
Aug 27, 2022
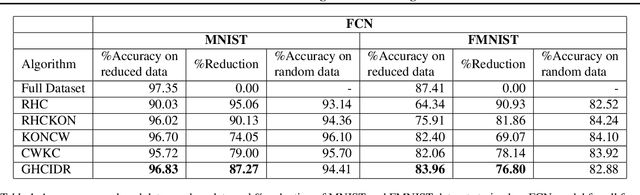
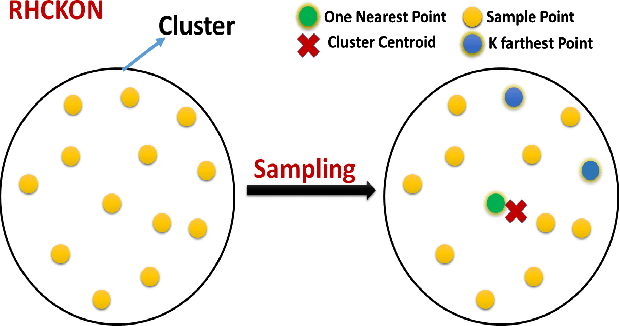
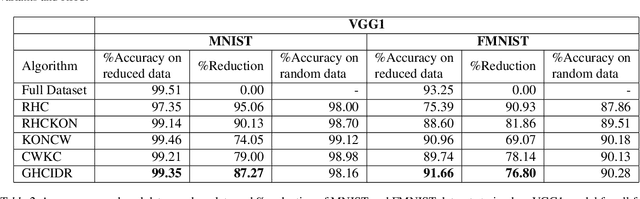
In this paper, we present novel variations of an earlier approach called homogeneous clustering algorithm for reducing dataset size. The intuition behind the approaches proposed in this paper is to partition the dataset into homogeneous clusters and select some images which contribute significantly to the accuracy. Selected images are the proper subset of the training data and thus are human-readable. We propose four variations upon the baseline algorithm-RHC. The intuition behind the first approach, RHCKON, is that the boundary points contribute significantly towards the representation of clusters. It involves selecting k farthest and one nearest neighbour of the centroid of the clusters. In the following two approaches (KONCW and CWKC), we introduce the concept of cluster weights. They are based on the fact that larger clusters contribute more than smaller sized clusters. The final variation is GHCIDR which selects points based on the geometrical aspect of data distribution. We performed the experiments on two deep learning models- Fully Connected Networks (FCN) and VGG1. We experimented with the four variants on three datasets- MNIST, CIFAR10, and Fashion-MNIST. We found that GHCIDR gave the best accuracy of 99.35%, 81.10%, and 91.66% and a training data reduction of 87.27%, 32.34%, and 76.80% on MNIST, CIFAR10, and Fashion-MNIST respectively.