 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBioBERT-based Deep Learning and Merged ChemProt-DrugProt for Enhanced Biomedical Relation Extraction
May 28, 2024



This paper presents a methodology for enhancing relation extraction from biomedical texts, focusing specifically on chemical-gene interactions. Leveraging the BioBERT model and a multi-layer fully connected network architecture, our approach integrates the ChemProt and DrugProt datasets using a novel merging strategy. Through extensive experimentation, we demonstrate significant performance improvements, particularly in CPR groups shared between the datasets. The findings underscore the importance of dataset merging in augmenting sample counts and improving model accuracy. Moreover, the study highlights the potential of automated information extraction in biomedical research and clinical practice.
Prescribed Fire Modeling using Knowledge-Guided Machine Learning for Land Management
Oct 02, 2023In recent years, the increasing threat of devastating wildfires has underscored the need for effective prescribed fire management. Process-based computer simulations have traditionally been employed to plan prescribed fires for wildfire prevention. However, even simplified process models like QUIC-Fire are too compute-intensive to be used for real-time decision-making, especially when weather conditions change rapidly. Traditional ML methods used for fire modeling offer computational speedup but struggle with physically inconsistent predictions, biased predictions due to class imbalance, biased estimates for fire spread metrics (e.g., burned area, rate of spread), and generalizability in out-of-distribution wind conditions. This paper introduces a novel machine learning (ML) framework that enables rapid emulation of prescribed fires while addressing these concerns. By incorporating domain knowledge, the proposed method helps reduce physical inconsistencies in fuel density estimates in data-scarce scenarios. To overcome the majority class bias in predictions, we leverage pre-existing source domain data to augment training data and learn the spread of fire more effectively. Finally, we overcome the problem of biased estimation of fire spread metrics by incorporating a hierarchical modeling structure to capture the interdependence in fuel density and burned area. Notably, improvement in fire metric (e.g., burned area) estimates offered by our framework makes it useful for fire managers, who often rely on these fire metric estimates to make decisions about prescribed burn management. Furthermore, our framework exhibits better generalization capabilities than the other ML-based fire modeling methods across diverse wind conditions and ignition patterns.
Multimodal Wildland Fire Smoke Detection
Dec 29, 2022


Research has shown that climate change creates warmer temperatures and drier conditions, leading to longer wildfire seasons and increased wildfire risks in the United States. These factors have in turn led to increases in the frequency, extent, and severity of wildfires in recent years. Given the danger posed by wildland fires to people, property, wildlife, and the environment, there is an urgency to provide tools for effective wildfire management. Early detection of wildfires is essential to minimizing potentially catastrophic destruction. In this paper, we present our work on integrating multiple data sources in SmokeyNet, a deep learning model using spatio-temporal information to detect smoke from wildland fires. Camera image data is integrated with weather sensor measurements and processed by SmokeyNet to create a multimodal wildland fire smoke detection system. We present our results comparing performance in terms of both accuracy and time-to-detection for multimodal data vs. a single data source. With a time-to-detection of only a few minutes, SmokeyNet can serve as an automated early notification system, providing a useful tool in the fight against destructive wildfires.
FIgLib & SmokeyNet: Dataset and Deep Learning Model for Real-Time Wildland Fire Smoke Detection
Dec 16, 2021
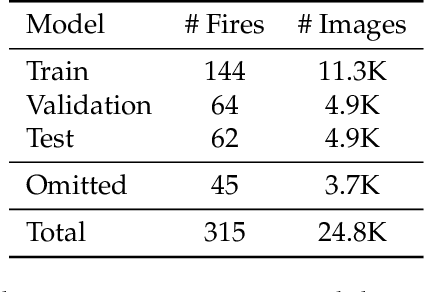
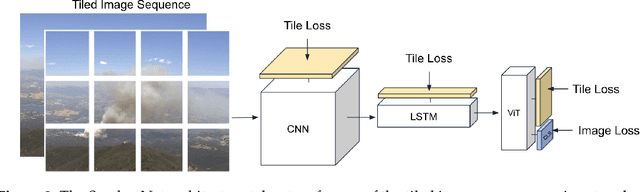
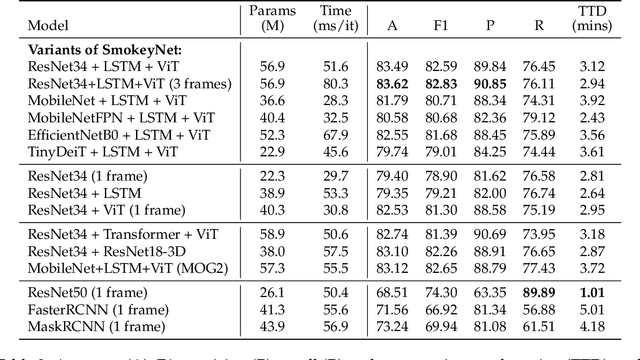
The size and frequency of wildland fires in the western United States have dramatically increased in recent years. On high fire-risk days, a small fire ignition can rapidly grow and get out of control. Early detection of fire ignitions from initial smoke can assist the response to such fires before they become difficult to manage. Past deep learning approaches for wildfire smoke detection have suffered from small or unreliable datasets that make it difficult to extrapolate performance to real-world scenarios. In this work, we present the Fire Ignition Library (FIgLib), a publicly-available dataset of nearly 25,000 labeled wildfire smoke images as seen from fixed-view cameras deployed in Southern California. We also introduce SmokeyNet, a novel deep learning architecture using spatio-temporal information from camera imagery for real-time wildfire smoke detection. When trained on the FIgLib dataset, SmokeyNet outperforms comparable baselines and rivals human performance. We hope that the availability of the FIgLib dataset and the SmokeyNet architecture will inspire further research into deep learning methods for wildfire smoke detection, leading to automated notification systems that reduce the time to wildfire response.
Cardiac MRI Image Segmentation for Left Ventricle and Right Ventricle using Deep Learning
Sep 17, 2019


The goal of this project is to use magnetic resonance imaging (MRI) data to provide an end-to-end analytics pipeline for left and right ventricle (LV and RV) segmentation. Another aim of the project is to find a model that would be generalizable across medical imaging datasets. We utilized a variety of models, datasets, and tests to determine which one is well suited to this purpose. Specifically, we implemented three models (2-D U-Net, 3-D U-Net, and DenseNet), and evaluated them on four datasets (Automated Cardiac Diagnosis Challenge, MICCAI 2009 LV, Sunnybrook Cardiac Data, MICCAI 2012 RV). While maintaining a consistent preprocessing strategy, we tested the performance of each model when trained on data from the same dataset as the test data, and when trained on data from a different dataset than the test dataset. Data augmentation was also used to increase the adaptability of the models. The results were compared to determine performance and generalizability.
Left Ventricle Segmentation and Volume Estimation on Cardiac MRI using Deep Learning
Sep 14, 2018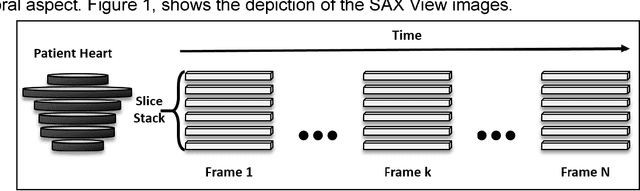
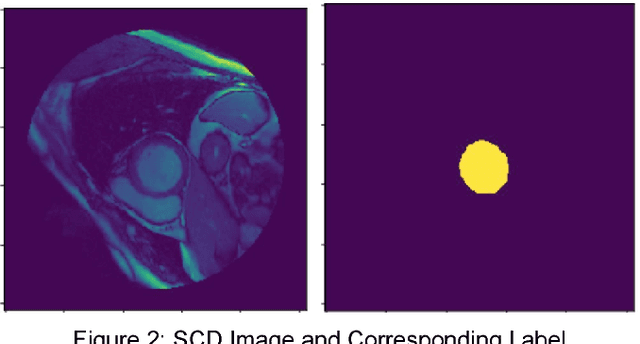
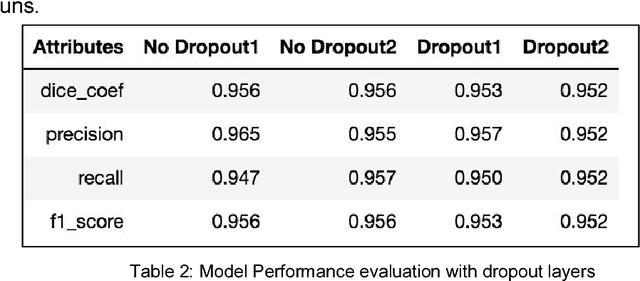
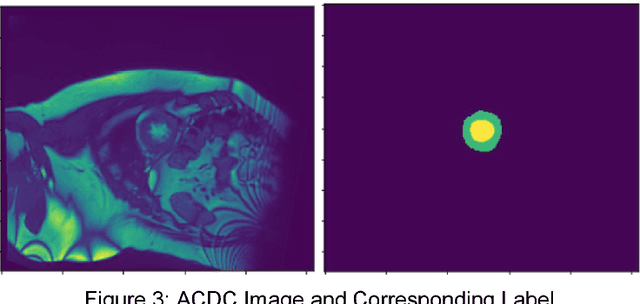
In the United States, heart disease is the leading cause of death for males and females, accounting for 610,000 deaths each year [1]. Physicians use Magnetic Resonance Imaging (MRI) scans to take images of the heart in order to non-invasively estimate its structural and functional parameters for cardiovascular diagnosis and disease management. The end-systolic volume (ESV) and end-diastolic volume (EDV) of the left ventricle (LV), and the ejection fraction (EF) are indicators of heart disease. These measures can be derived from the segmented contours of the LV; thus, consistent and accurate segmentation of the LV from MRI images are critical to the accuracy of the ESV, EDV, and EF, and to non-invasive cardiac disease detection. In this work, various image preprocessing techniques, model configurations using the U-Net deep learning architecture, postprocessing methods, and approaches for volume estimation are investigated. An end-to-end analytics pipeline with multiple stages is provided for automated LV segmentation and volume estimation. First, image data are reformatted and processed from DICOM and NIfTI formats to raw images in array format. Secondly, raw images are processed with multiple image preprocessing methods and cropped to include only the Region of Interest (ROI). Thirdly, preprocessed images are segmented using U-Net models. Lastly, post processing of segmented images to remove extra contours along with intelligent slice and frame selection are applied, followed by calculation of the ESV, EDV, and EF. This analytics pipeline is implemented and runs on a distributed computing environment with a GPU cluster at the San Diego Supercomputer Center at UCSD.