 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Wildland Fire Smoke Detection
Dec 29, 2022


Research has shown that climate change creates warmer temperatures and drier conditions, leading to longer wildfire seasons and increased wildfire risks in the United States. These factors have in turn led to increases in the frequency, extent, and severity of wildfires in recent years. Given the danger posed by wildland fires to people, property, wildlife, and the environment, there is an urgency to provide tools for effective wildfire management. Early detection of wildfires is essential to minimizing potentially catastrophic destruction. In this paper, we present our work on integrating multiple data sources in SmokeyNet, a deep learning model using spatio-temporal information to detect smoke from wildland fires. Camera image data is integrated with weather sensor measurements and processed by SmokeyNet to create a multimodal wildland fire smoke detection system. We present our results comparing performance in terms of both accuracy and time-to-detection for multimodal data vs. a single data source. With a time-to-detection of only a few minutes, SmokeyNet can serve as an automated early notification system, providing a useful tool in the fight against destructive wildfires.
Workflow-Driven Distributed Machine Learning in CHASE-CI: A Cognitive Hardware and Software Ecosystem Community Infrastructure
Feb 26, 2019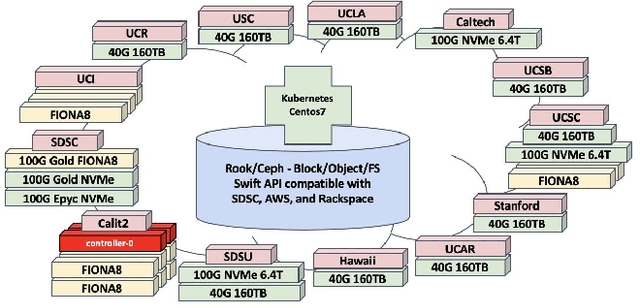
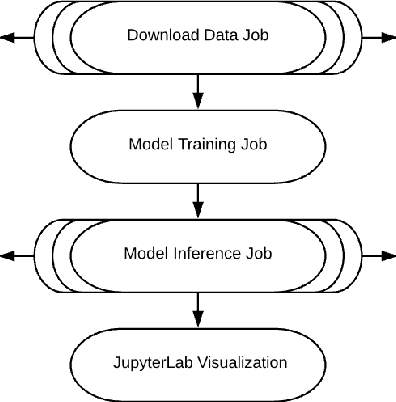
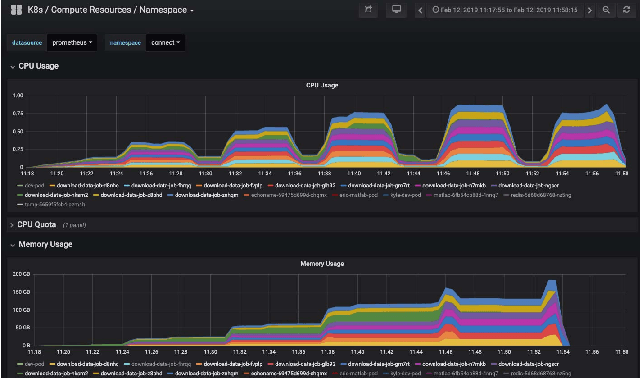
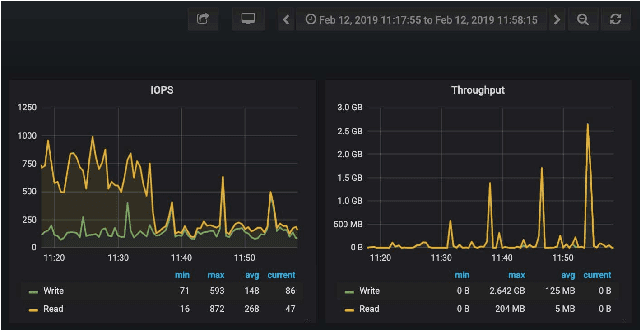
The advances in data, computing and networking over the last two decades led to a shift in many application domains that includes machine learning on big data as a part of the scientific process, requiring new capabilities for integrated and distributed hardware and software infrastructure. This paper contributes a workflow-driven approach for dynamic data-driven application development on top of a new kind of networked Cyberinfrastructure called CHASE-CI. In particular, we present: 1) The architecture for CHASE-CI, a network of distributed fast GPU appliances for machine learning and storage managed through Kubernetes on the high-speed (10-100Gbps) Pacific Research Platform (PRP); 2) A machine learning software containerization approach and libraries required for turning such a network into a distributed computer for big data analysis; 3) An atmospheric science case study that can only be made scalable with an infrastructure like CHASE-CI; 4) Capabilities for virtual cluster management for data communication and analysis in a dynamically scalable fashion, and visualization across the network in specialized visualization facilities in near real-time; and, 5) A step-by-step workflow and performance measurement approach that enables taking advantage of the dynamic architecture of the CHASE-CI network and container management infrastructure.
Enabling FAIR Research in Earth Science through Research Objects
Sep 27, 2018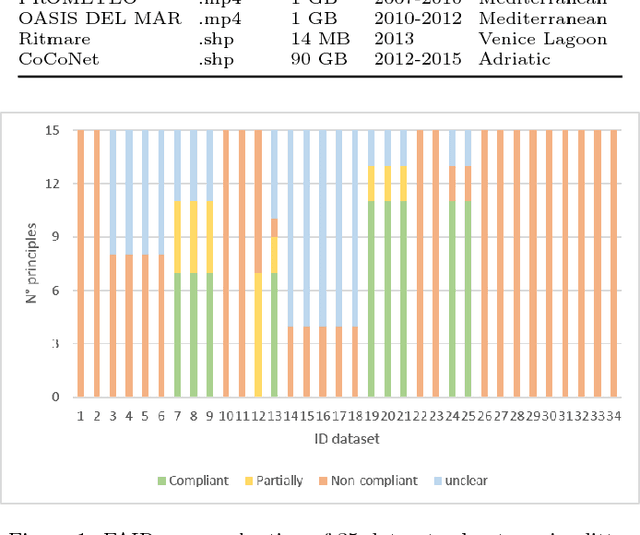
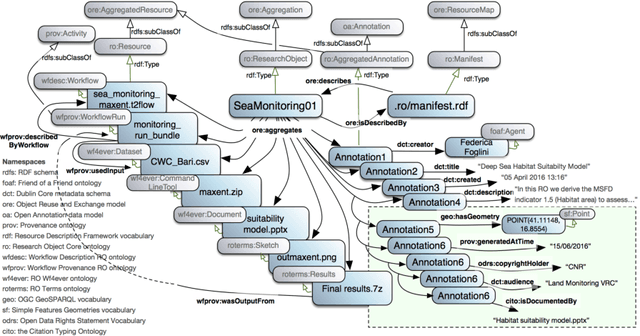
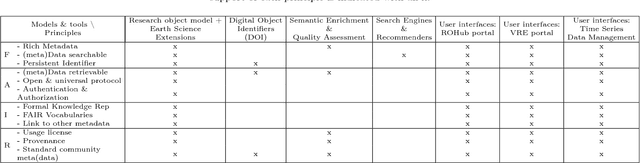
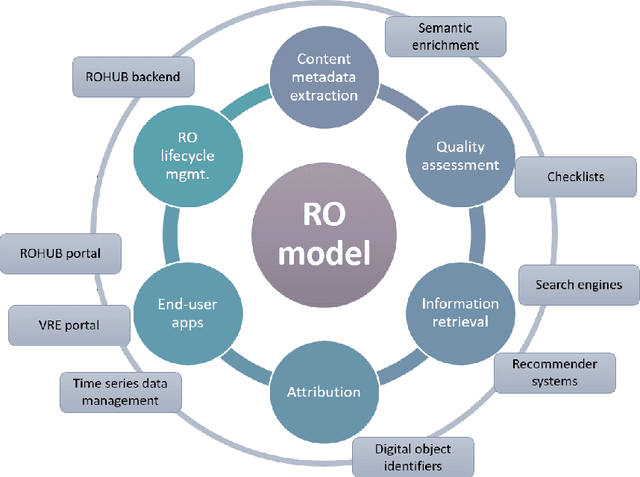
Data-intensive science communities are progressively adopting FAIR practices that enhance the visibility of scientific breakthroughs and enable reuse. At the core of this movement, research objects contain and describe scientific information and resources in a way compliant with the FAIR principles and sustain the development of key infrastructure and tools. This paper provides an account of the challenges, experiences and solutions involved in the adoption of FAIR around research objects over several Earth Science disciplines. During this journey, our work has been comprehensive, with outcomes including: an extended research object model adapted to the needs of earth scientists; the provisioning of digital object identifiers (DOI) to enable persistent identification and to give due credit to authors; the generation of content-based, semantically rich, research object metadata through natural language processing, enhancing visibility and reuse through recommendation systems and third-party search engines; and various types of checklists that provide a compact representation of research object quality as a key enabler of scientific reuse. All these results have been integrated in ROHub, a platform that provides research object management functionality to a wealth of applications and interfaces across different scientific communities. To monitor and quantify the community uptake of research objects, we have defined indicators and obtained measures via ROHub that are also discussed herein.
Modular Resource Centric Learning for Workflow Performance Prediction
Apr 17, 2018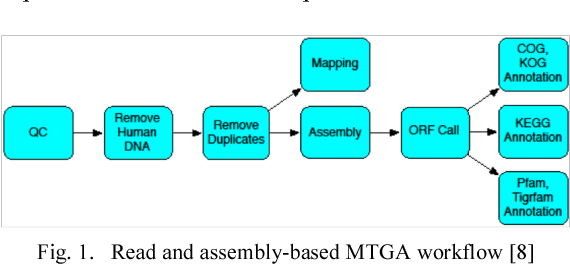
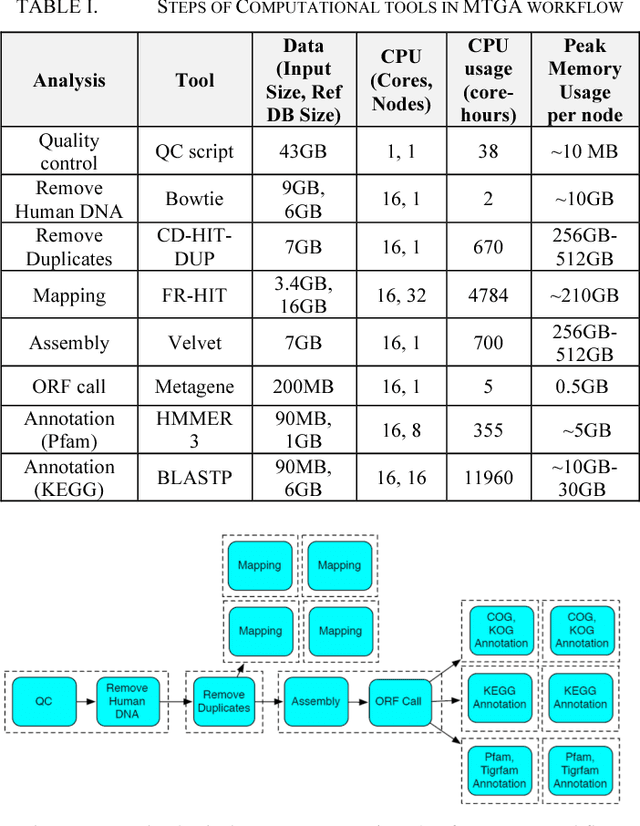
Workflows provide an expressive programming model for fine-grained control of large-scale applications in distributed computing environments. Accurate estimates of complex workflow execution metrics on large-scale machines have several key advantages. The performance of scheduling algorithms that rely on estimates of execution metrics degrades when the accuracy of predicted execution metrics decreases. This in-progress paper presents a technique being developed to improve the accuracy of predicted performance metrics of large-scale workflows on distributed platforms. The central idea of this work is to train resource-centric machine learning agents to capture complex relationships between a set of program instructions and their performance metrics when executed on a specific resource. This resource-centric view of a workflow exploits the fact that predicting execution times of sub-modules of a workflow requires monitoring and modeling of a few dynamic and static features. We transform the input workflow that is essentially a directed acyclic graph of actions into a Physical Resource Execution Plan (PREP). This transformation enables us to model an arbitrarily complex workflow as a set of simpler programs running on physical nodes. We delegate a machine learning model to capture performance metrics for each resource type when it executes different program instructions under varying degrees of resource contention. Our algorithm takes the prediction metrics from each resource agent and composes the overall workflow performance metrics by utilizing the structure of the corresponding Physical Resource Execution Plan.