 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Impact of Knowledge-based Linguistic Annotations in the Quality of Scientific Embeddings
Apr 13, 2021
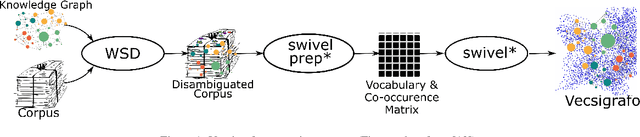
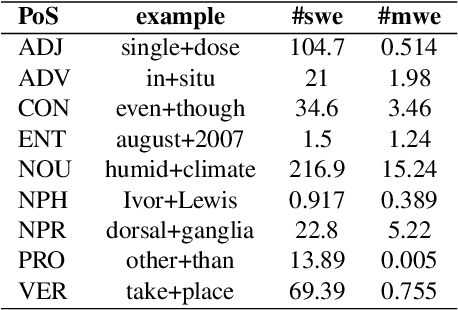
In essence, embedding algorithms work by optimizing the distance between a word and its usual context in order to generate an embedding space that encodes the distributional representation of words. In addition to single words or word pieces, other features which result from the linguistic analysis of text, including lexical, grammatical and semantic information, can be used to improve the quality of embedding spaces. However, until now we did not have a precise understanding of the impact that such individual annotations and their possible combinations may have in the quality of the embeddings. In this paper, we conduct a comprehensive study on the use of explicit linguistic annotations to generate embeddings from a scientific corpus and quantify their impact in the resulting representations. Our results show how the effect of such annotations in the embeddings varies depending on the evaluation task. In general, we observe that learning embeddings using linguistic annotations contributes to achieve better evaluation results.
Understanding Transformers for Bot Detection in Twitter
Apr 13, 2021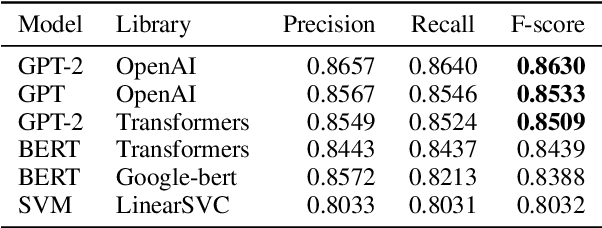

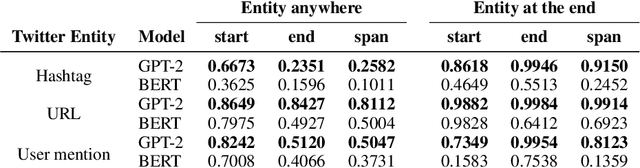
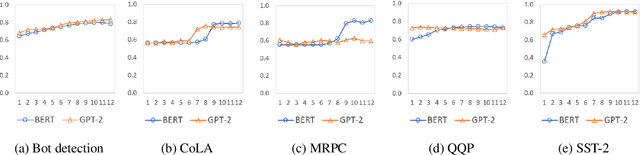
In this paper we shed light on the impact of fine-tuning over social media data in the internal representations of neural language models. We focus on bot detection in Twitter, a key task to mitigate and counteract the automatic spreading of disinformation and bias in social media. We investigate the use of pre-trained language models to tackle the detection of tweets generated by a bot or a human account based exclusively on its content. Unlike the general trend in benchmarks like GLUE, where BERT generally outperforms generative transformers like GPT and GPT-2 for most classification tasks on regular text, we observe that fine-tuning generative transformers on a bot detection task produces higher accuracies. We analyze the architectural components of each transformer and study the effect of fine-tuning on their hidden states and output representations. Among our findings, we show that part of the syntactical information and distributional properties captured by BERT during pre-training is lost upon fine-tuning while the generative pre-training approach manage to preserve these properties.
Classifying Scientific Publications with BERT -- Is Self-Attention a Feature Selection Method?
Jan 20, 2021
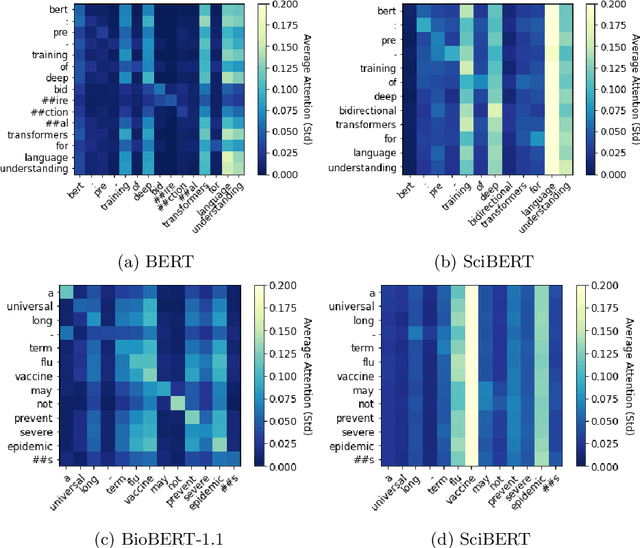
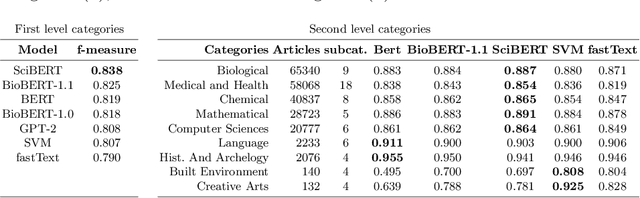
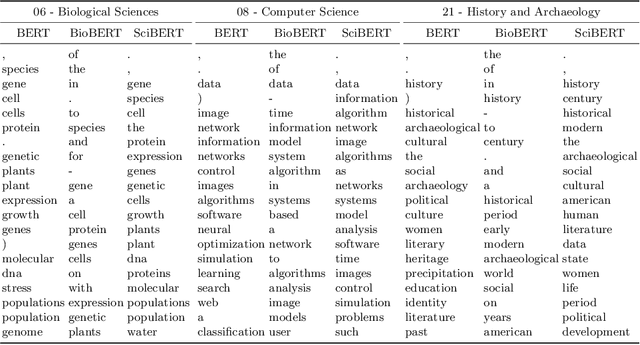
We investigate the self-attention mechanism of BERT in a fine-tuning scenario for the classification of scientific articles over a taxonomy of research disciplines. We observe how self-attention focuses on words that are highly related to the domain of the article. Particularly, a small subset of vocabulary words tends to receive most of the attention. We compare and evaluate the subset of the most attended words with feature selection methods normally used for text classification in order to characterize self-attention as a possible feature selection approach. Using ConceptNet as ground truth, we also find that attended words are more related to the research fields of the articles. However, conventional feature selection methods are still a better option to learn classifiers from scratch. This result suggests that, while self-attention identifies domain-relevant terms, the discriminatory information in BERT is encoded in the contextualized outputs and the classification layer. It also raises the question whether injecting feature selection methods in the self-attention mechanism could further optimize single sequence classification using transformers.
ISAAQ -- Mastering Textbook Questions with Pre-trained Transformers and Bottom-Up and Top-Down Attention
Oct 01, 2020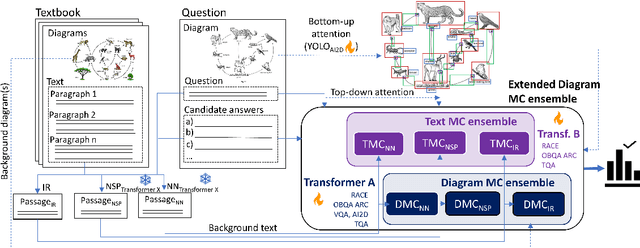
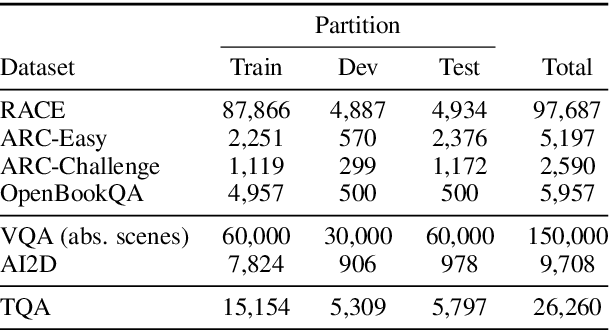
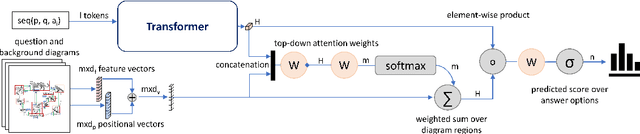
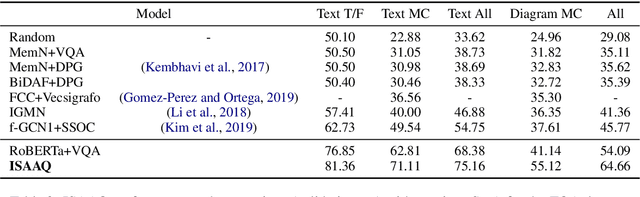
Textbook Question Answering is a complex task in the intersection of Machine Comprehension and Visual Question Answering that requires reasoning with multimodal information from text and diagrams. For the first time, this paper taps on the potential of transformer language models and bottom-up and top-down attention to tackle the language and visual understanding challenges this task entails. Rather than training a language-visual transformer from scratch we rely on pre-trained transformers, fine-tuning and ensembling. We add bottom-up and top-down attention to identify regions of interest corresponding to diagram constituents and their relationships, improving the selection of relevant visual information for each question and answer options. Our system ISAAQ reports unprecedented success in all TQA question types, with accuracies of 81.36%, 71.11% and 55.12% on true/false, text-only and diagram multiple choice questions. ISAAQ also demonstrates its broad applicability, obtaining state-of-the-art results in other demanding datasets.
Linked Credibility Reviews for Explainable Misinformation Detection
Aug 28, 2020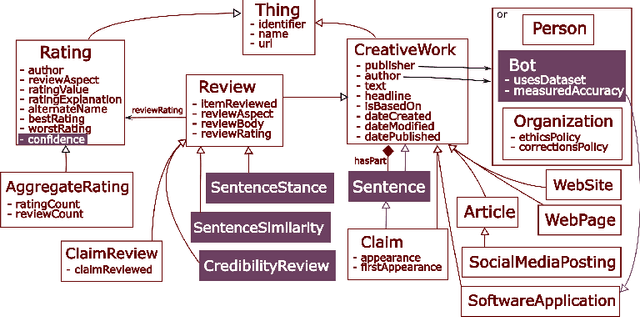

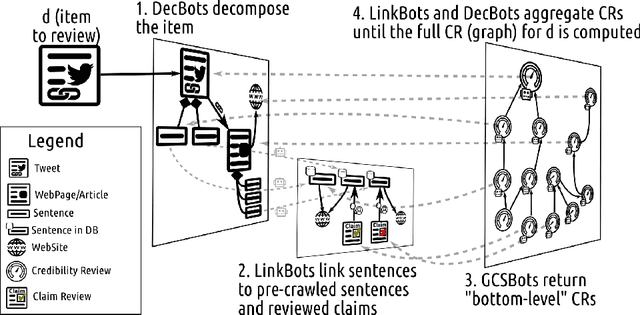

In recent years, misinformation on the Web has become increasingly rampant. The research community has responded by proposing systems and challenges, which are beginning to be useful for (various subtasks of) detecting misinformation. However, most proposed systems are based on deep learning techniques which are fine-tuned to specific domains, are difficult to interpret and produce results which are not machine readable. This limits their applicability and adoption as they can only be used by a select expert audience in very specific settings. In this paper we propose an architecture based on a core concept of Credibility Reviews (CRs) that can be used to build networks of distributed bots that collaborate for misinformation detection. The CRs serve as building blocks to compose graphs of (i) web content, (ii) existing credibility signals --fact-checked claims and reputation reviews of websites--, and (iii) automatically computed reviews. We implement this architecture on top of lightweight extensions to Schema.org and services providing generic NLP tasks for semantic similarity and stance detection. Evaluations on existing datasets of social-media posts, fake news and political speeches demonstrates several advantages over existing systems: extensibility, domain-independence, composability, explainability and transparency via provenance. Furthermore, we obtain competitive results without requiring finetuning and establish a new state of the art on the Clef'18 CheckThat! Factuality task.
Assessing the Lexico-Semantic Relational Knowledge Captured by Word and Concept Embeddings
Sep 24, 2019

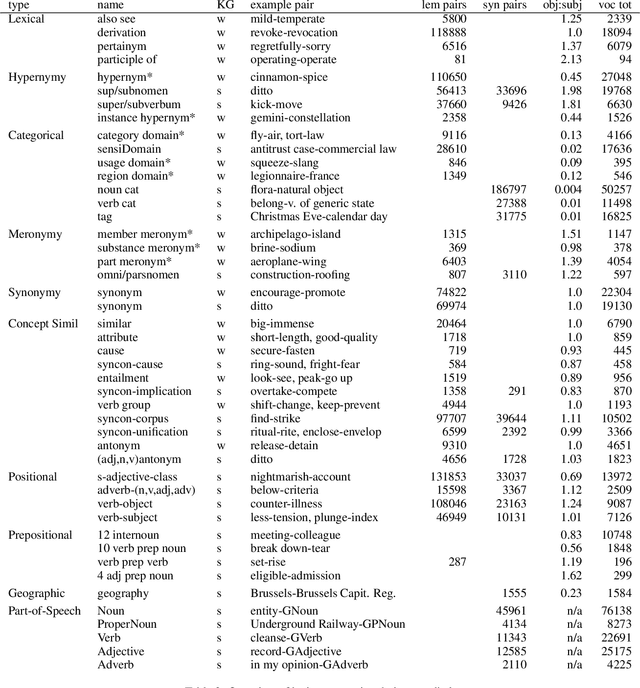
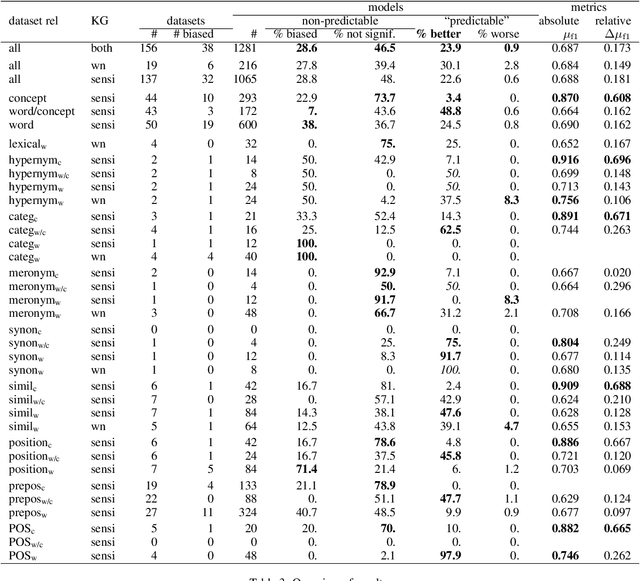
Deep learning currently dominates the benchmarks for various NLP tasks and, at the basis of such systems, words are frequently represented as embeddings --vectors in a low dimensional space-- learned from large text corpora and various algorithms have been proposed to learn both word and concept embeddings. One of the claimed benefits of such embeddings is that they capture knowledge about semantic relations. Such embeddings are most often evaluated through tasks such as predicting human-rated similarity and analogy which only test a few, often ill-defined, relations. In this paper, we propose a method for (i) reliably generating word and concept pair datasets for a wide number of relations by using a knowledge graph and (ii) evaluating to what extent pre-trained embeddings capture those relations. We evaluate the approach against a proprietary and a public knowledge graph and analyze the results, showing which lexico-semantic relational knowledge is captured by current embedding learning approaches.
Look, Read and Enrich. Learning from Scientific Figures and their Captions
Sep 19, 2019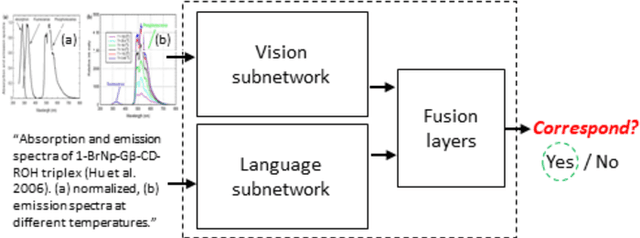

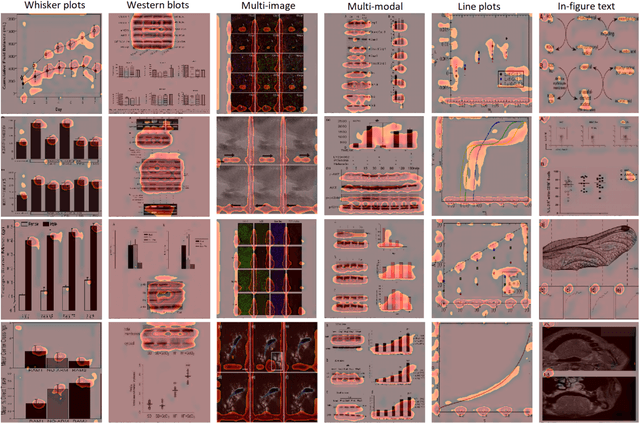
Compared to natural images, understanding scientific figures is particularly hard for machines. However, there is a valuable source of information in scientific literature that until now has remained untapped: the correspondence between a figure and its caption. In this paper we investigate what can be learnt by looking at a large number of figures and reading their captions, and introduce a figure-caption correspondence learning task that makes use of our observations. Training visual and language networks without supervision other than pairs of unconstrained figures and captions is shown to successfully solve this task. We also show that transferring lexical and semantic knowledge from a knowledge graph significantly enriches the resulting features. Finally, we demonstrate the positive impact of such features in other tasks involving scientific text and figures, like multi-modal classification and machine comprehension for question answering, outperforming supervised baselines and ad-hoc approaches.
Enabling FAIR Research in Earth Science through Research Objects
Sep 27, 2018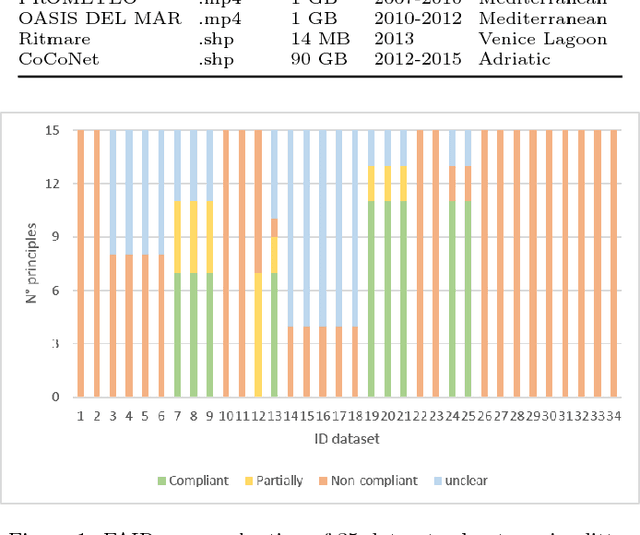
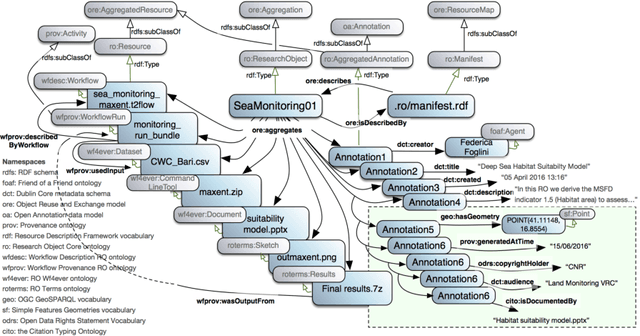
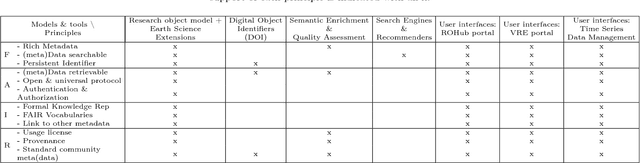
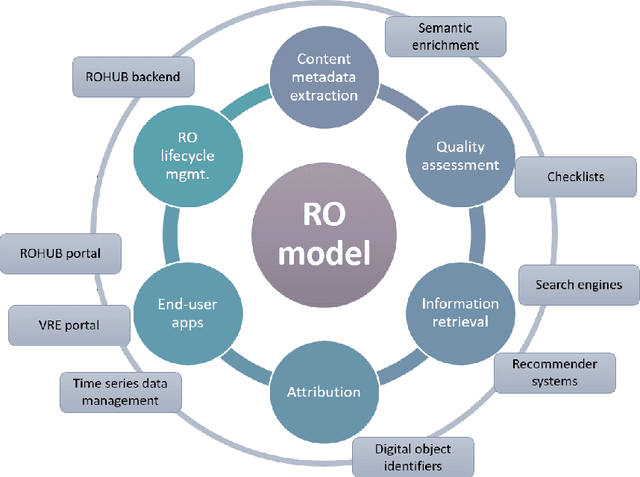
Data-intensive science communities are progressively adopting FAIR practices that enhance the visibility of scientific breakthroughs and enable reuse. At the core of this movement, research objects contain and describe scientific information and resources in a way compliant with the FAIR principles and sustain the development of key infrastructure and tools. This paper provides an account of the challenges, experiences and solutions involved in the adoption of FAIR around research objects over several Earth Science disciplines. During this journey, our work has been comprehensive, with outcomes including: an extended research object model adapted to the needs of earth scientists; the provisioning of digital object identifiers (DOI) to enable persistent identification and to give due credit to authors; the generation of content-based, semantically rich, research object metadata through natural language processing, enhancing visibility and reuse through recommendation systems and third-party search engines; and various types of checklists that provide a compact representation of research object quality as a key enabler of scientific reuse. All these results have been integrated in ROHub, a platform that provides research object management functionality to a wealth of applications and interfaces across different scientific communities. To monitor and quantify the community uptake of research objects, we have defined indicators and obtained measures via ROHub that are also discussed herein.
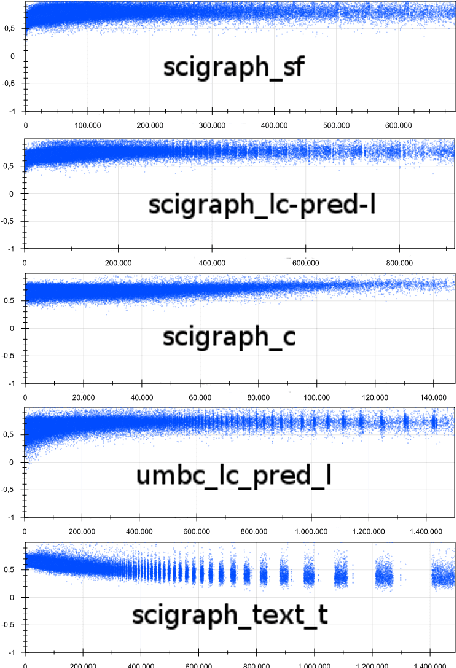
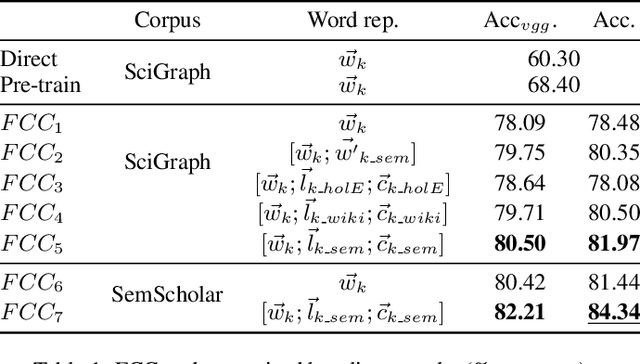
Not just about size - A Study on the Role of Distributed Word Representations in the Analysis of Scientific Publications
Apr 05, 2018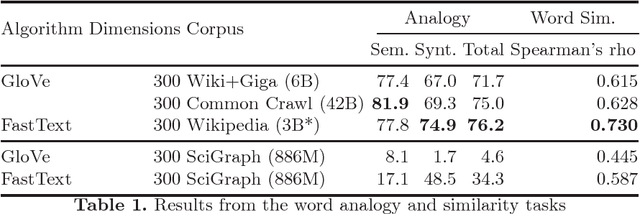
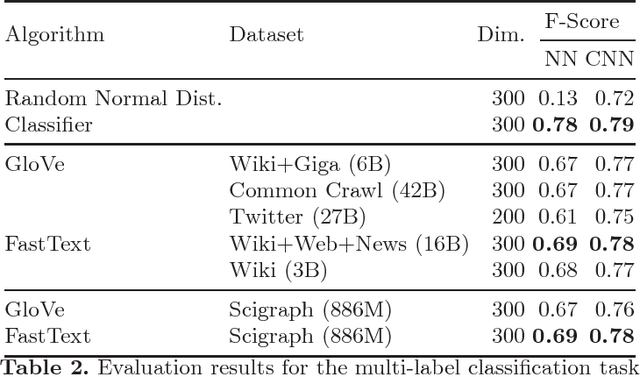
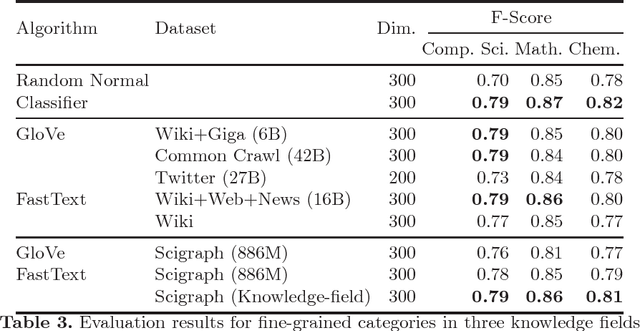
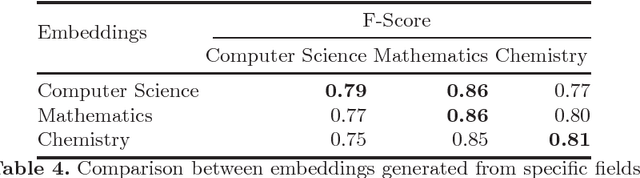
The emergence of knowledge graphs in the scholarly communication domain and recent advances in artificial intelligence and natural language processing bring us closer to a scenario where intelligent systems can assist scientists over a range of knowledge-intensive tasks. In this paper we present experimental results about the generation of word embeddings from scholarly publications for the intelligent processing of scientific texts extracted from SciGraph. We compare the performance of domain-specific embeddings with existing pre-trained vectors generated from very large and general purpose corpora. Our results suggest that there is a trade-off between corpus specificity and volume. Embeddings from domain-specific scientific corpora effectively capture the semantics of the domain. On the other hand, obtaining comparable results through general corpora can also be achieved, but only in the presence of very large corpora of well formed text. Furthermore, We also show that the degree of overlapping between knowledge areas is directly related to the performance of embeddings in domain evaluation tasks.