 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing the Lexico-Semantic Relational Knowledge Captured by Word and Concept Embeddings
Paper and Code


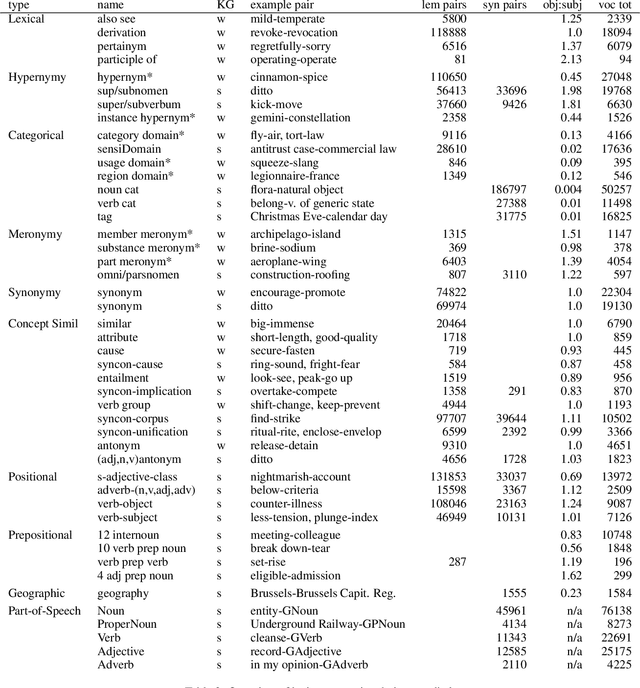
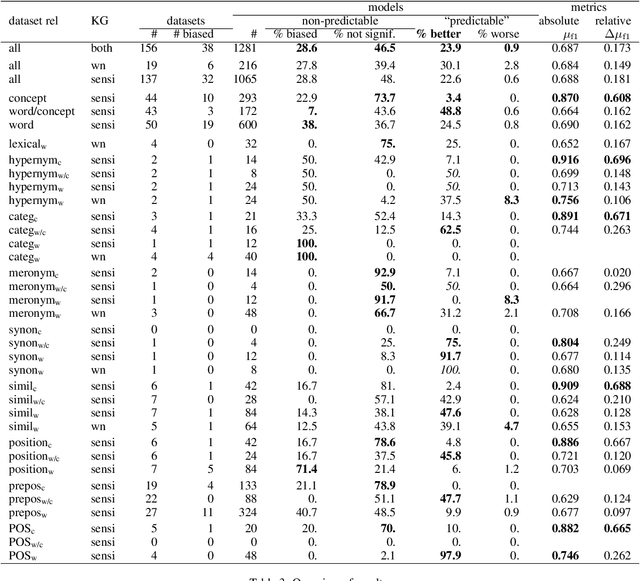
Deep learning currently dominates the benchmarks for various NLP tasks and, at the basis of such systems, words are frequently represented as embeddings --vectors in a low dimensional space-- learned from large text corpora and various algorithms have been proposed to learn both word and concept embeddings. One of the claimed benefits of such embeddings is that they capture knowledge about semantic relations. Such embeddings are most often evaluated through tasks such as predicting human-rated similarity and analogy which only test a few, often ill-defined, relations. In this paper, we propose a method for (i) reliably generating word and concept pair datasets for a wide number of relations by using a knowledge graph and (ii) evaluating to what extent pre-trained embeddings capture those relations. We evaluate the approach against a proprietary and a public knowledge graph and analyze the results, showing which lexico-semantic relational knowledge is captured by current embedding learning approaches.