 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Impact of Knowledge-based Linguistic Annotations in the Quality of Scientific Embeddings
Apr 13, 2021
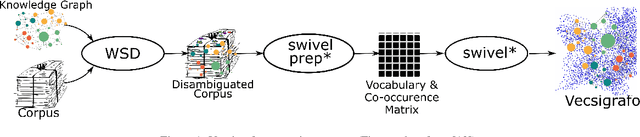
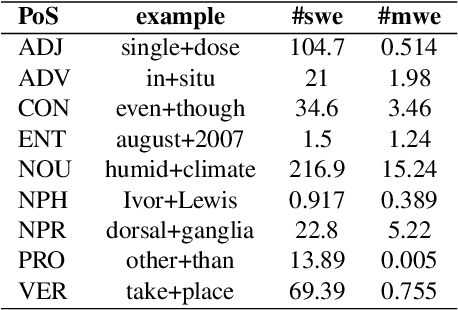
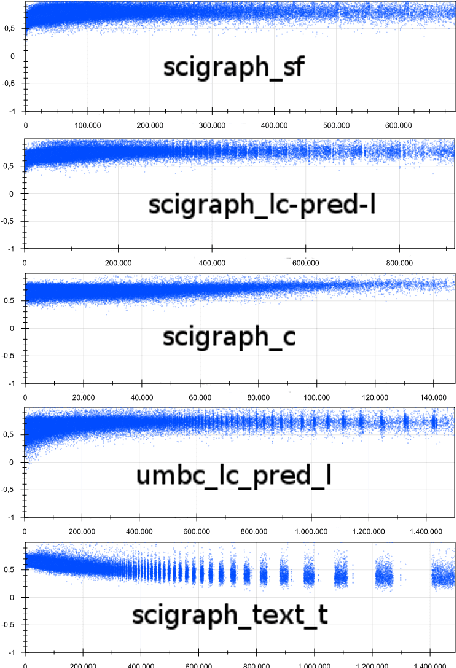
In essence, embedding algorithms work by optimizing the distance between a word and its usual context in order to generate an embedding space that encodes the distributional representation of words. In addition to single words or word pieces, other features which result from the linguistic analysis of text, including lexical, grammatical and semantic information, can be used to improve the quality of embedding spaces. However, until now we did not have a precise understanding of the impact that such individual annotations and their possible combinations may have in the quality of the embeddings. In this paper, we conduct a comprehensive study on the use of explicit linguistic annotations to generate embeddings from a scientific corpus and quantify their impact in the resulting representations. Our results show how the effect of such annotations in the embeddings varies depending on the evaluation task. In general, we observe that learning embeddings using linguistic annotations contributes to achieve better evaluation results.
Linked Credibility Reviews for Explainable Misinformation Detection
Aug 28, 2020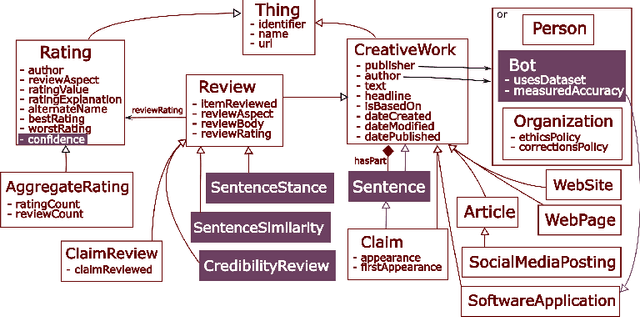

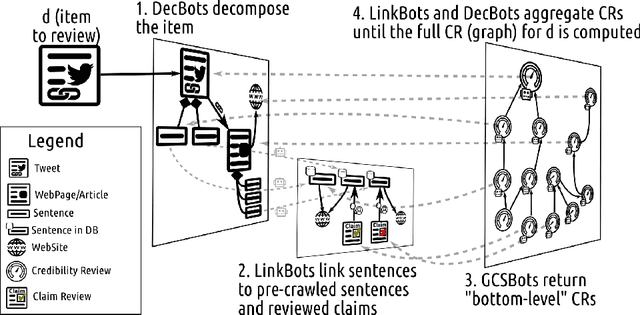

In recent years, misinformation on the Web has become increasingly rampant. The research community has responded by proposing systems and challenges, which are beginning to be useful for (various subtasks of) detecting misinformation. However, most proposed systems are based on deep learning techniques which are fine-tuned to specific domains, are difficult to interpret and produce results which are not machine readable. This limits their applicability and adoption as they can only be used by a select expert audience in very specific settings. In this paper we propose an architecture based on a core concept of Credibility Reviews (CRs) that can be used to build networks of distributed bots that collaborate for misinformation detection. The CRs serve as building blocks to compose graphs of (i) web content, (ii) existing credibility signals --fact-checked claims and reputation reviews of websites--, and (iii) automatically computed reviews. We implement this architecture on top of lightweight extensions to Schema.org and services providing generic NLP tasks for semantic similarity and stance detection. Evaluations on existing datasets of social-media posts, fake news and political speeches demonstrates several advantages over existing systems: extensibility, domain-independence, composability, explainability and transparency via provenance. Furthermore, we obtain competitive results without requiring finetuning and establish a new state of the art on the Clef'18 CheckThat! Factuality task.
Assessing the Lexico-Semantic Relational Knowledge Captured by Word and Concept Embeddings
Sep 24, 2019

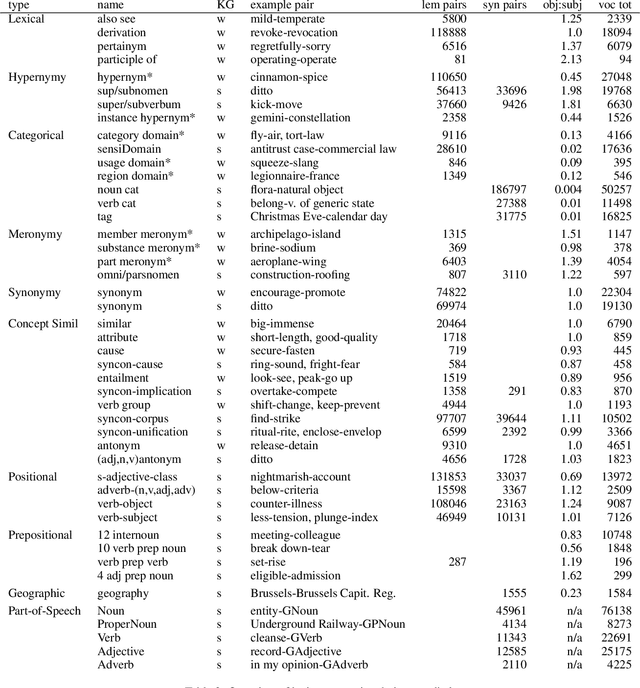
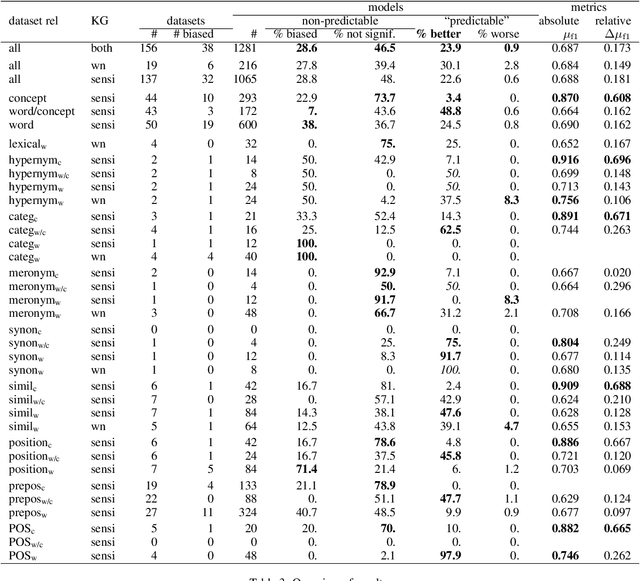
Deep learning currently dominates the benchmarks for various NLP tasks and, at the basis of such systems, words are frequently represented as embeddings --vectors in a low dimensional space-- learned from large text corpora and various algorithms have been proposed to learn both word and concept embeddings. One of the claimed benefits of such embeddings is that they capture knowledge about semantic relations. Such embeddings are most often evaluated through tasks such as predicting human-rated similarity and analogy which only test a few, often ill-defined, relations. In this paper, we propose a method for (i) reliably generating word and concept pair datasets for a wide number of relations by using a knowledge graph and (ii) evaluating to what extent pre-trained embeddings capture those relations. We evaluate the approach against a proprietary and a public knowledge graph and analyze the results, showing which lexico-semantic relational knowledge is captured by current embedding learning approaches.