 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Impact of Knowledge-based Linguistic Annotations in the Quality of Scientific Embeddings
Paper and Code
Apr 13, 2021
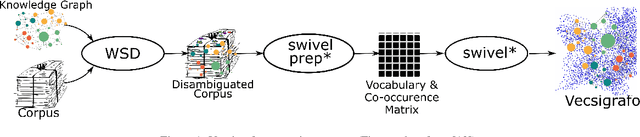
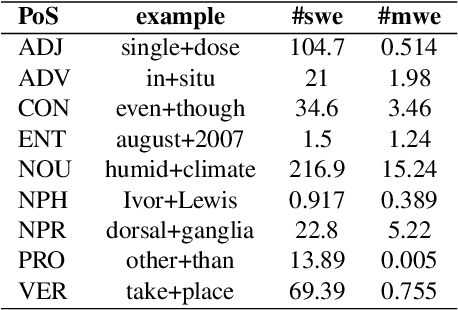
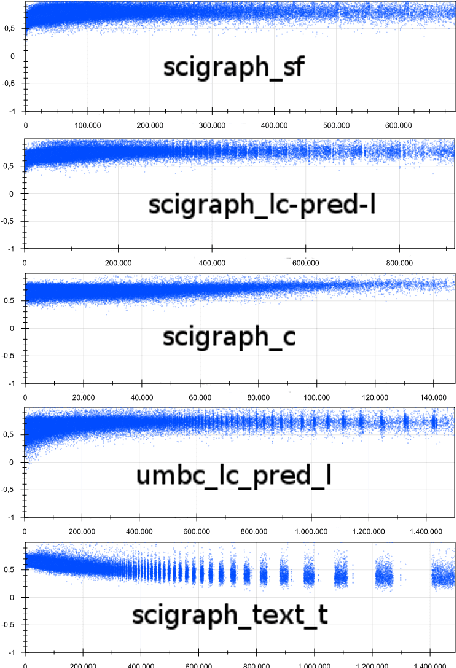
In essence, embedding algorithms work by optimizing the distance between a word and its usual context in order to generate an embedding space that encodes the distributional representation of words. In addition to single words or word pieces, other features which result from the linguistic analysis of text, including lexical, grammatical and semantic information, can be used to improve the quality of embedding spaces. However, until now we did not have a precise understanding of the impact that such individual annotations and their possible combinations may have in the quality of the embeddings. In this paper, we conduct a comprehensive study on the use of explicit linguistic annotations to generate embeddings from a scientific corpus and quantify their impact in the resulting representations. Our results show how the effect of such annotations in the embeddings varies depending on the evaluation task. In general, we observe that learning embeddings using linguistic annotations contributes to achieve better evaluation results.