 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Impact of Knowledge-based Linguistic Annotations in the Quality of Scientific Embeddings
Apr 13, 2021
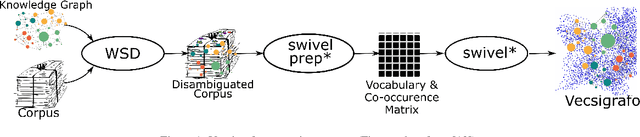
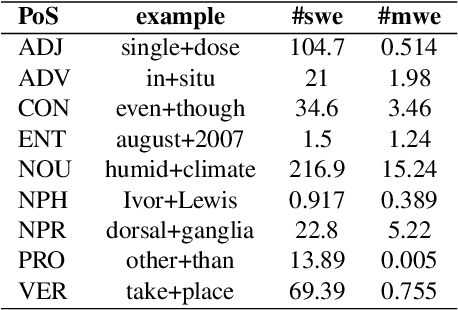
In essence, embedding algorithms work by optimizing the distance between a word and its usual context in order to generate an embedding space that encodes the distributional representation of words. In addition to single words or word pieces, other features which result from the linguistic analysis of text, including lexical, grammatical and semantic information, can be used to improve the quality of embedding spaces. However, until now we did not have a precise understanding of the impact that such individual annotations and their possible combinations may have in the quality of the embeddings. In this paper, we conduct a comprehensive study on the use of explicit linguistic annotations to generate embeddings from a scientific corpus and quantify their impact in the resulting representations. Our results show how the effect of such annotations in the embeddings varies depending on the evaluation task. In general, we observe that learning embeddings using linguistic annotations contributes to achieve better evaluation results.
Understanding Transformers for Bot Detection in Twitter
Apr 13, 2021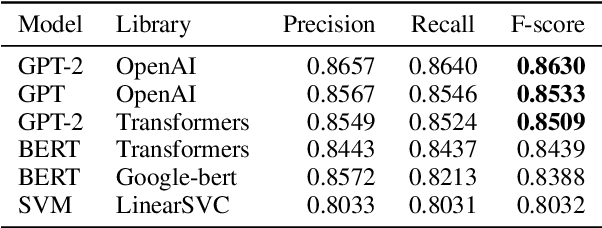

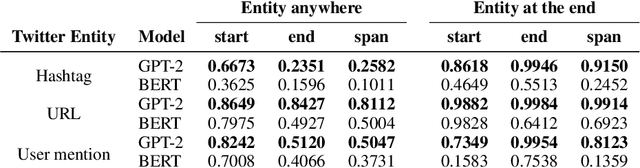
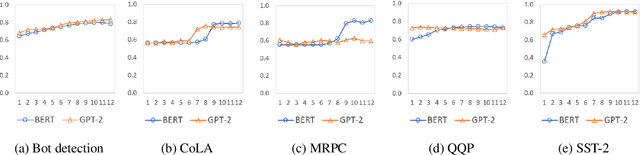
In this paper we shed light on the impact of fine-tuning over social media data in the internal representations of neural language models. We focus on bot detection in Twitter, a key task to mitigate and counteract the automatic spreading of disinformation and bias in social media. We investigate the use of pre-trained language models to tackle the detection of tweets generated by a bot or a human account based exclusively on its content. Unlike the general trend in benchmarks like GLUE, where BERT generally outperforms generative transformers like GPT and GPT-2 for most classification tasks on regular text, we observe that fine-tuning generative transformers on a bot detection task produces higher accuracies. We analyze the architectural components of each transformer and study the effect of fine-tuning on their hidden states and output representations. Among our findings, we show that part of the syntactical information and distributional properties captured by BERT during pre-training is lost upon fine-tuning while the generative pre-training approach manage to preserve these properties.
Classifying Scientific Publications with BERT -- Is Self-Attention a Feature Selection Method?
Jan 20, 2021
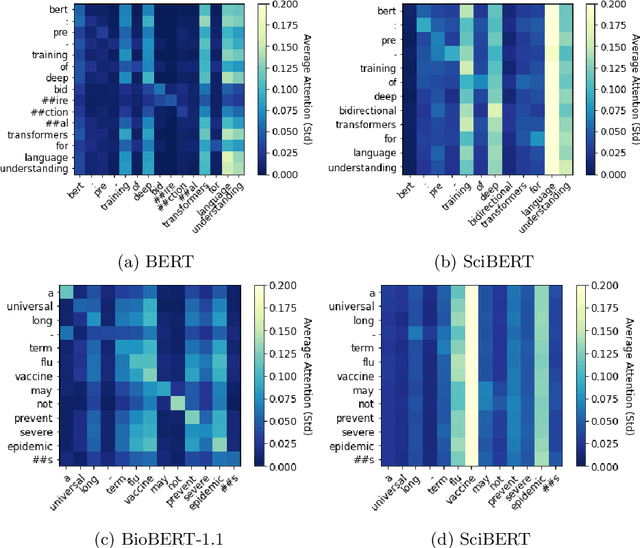
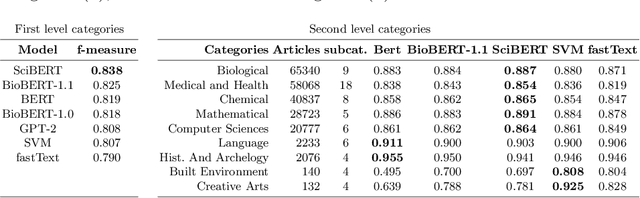
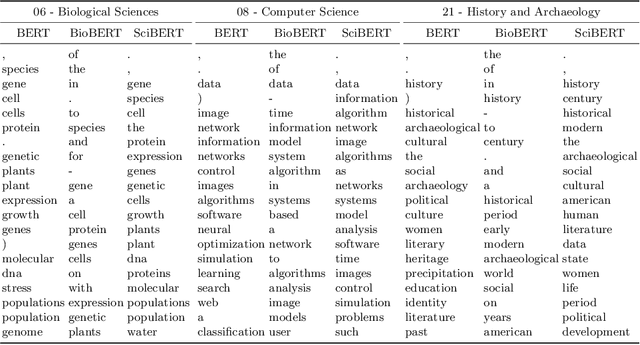
We investigate the self-attention mechanism of BERT in a fine-tuning scenario for the classification of scientific articles over a taxonomy of research disciplines. We observe how self-attention focuses on words that are highly related to the domain of the article. Particularly, a small subset of vocabulary words tends to receive most of the attention. We compare and evaluate the subset of the most attended words with feature selection methods normally used for text classification in order to characterize self-attention as a possible feature selection approach. Using ConceptNet as ground truth, we also find that attended words are more related to the research fields of the articles. However, conventional feature selection methods are still a better option to learn classifiers from scratch. This result suggests that, while self-attention identifies domain-relevant terms, the discriminatory information in BERT is encoded in the contextualized outputs and the classification layer. It also raises the question whether injecting feature selection methods in the self-attention mechanism could further optimize single sequence classification using transformers.
Enabling FAIR Research in Earth Science through Research Objects
Sep 27, 2018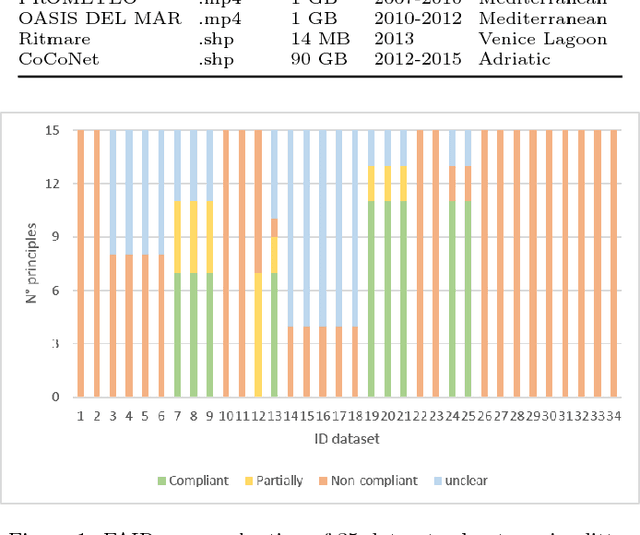
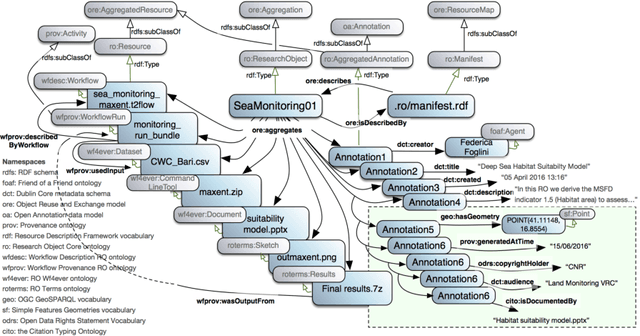
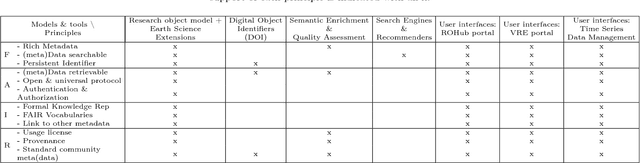
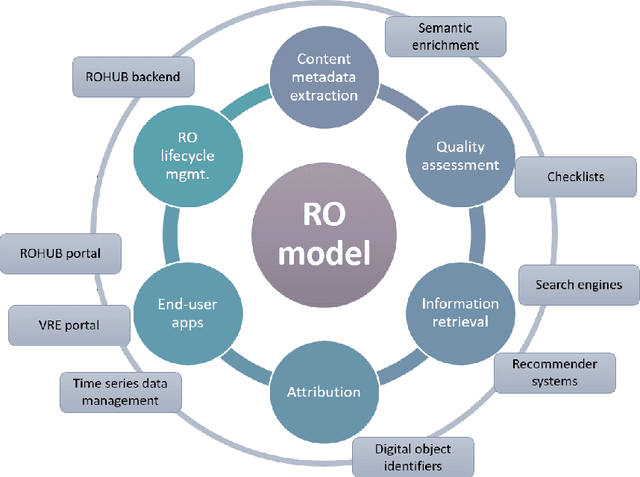
Data-intensive science communities are progressively adopting FAIR practices that enhance the visibility of scientific breakthroughs and enable reuse. At the core of this movement, research objects contain and describe scientific information and resources in a way compliant with the FAIR principles and sustain the development of key infrastructure and tools. This paper provides an account of the challenges, experiences and solutions involved in the adoption of FAIR around research objects over several Earth Science disciplines. During this journey, our work has been comprehensive, with outcomes including: an extended research object model adapted to the needs of earth scientists; the provisioning of digital object identifiers (DOI) to enable persistent identification and to give due credit to authors; the generation of content-based, semantically rich, research object metadata through natural language processing, enhancing visibility and reuse through recommendation systems and third-party search engines; and various types of checklists that provide a compact representation of research object quality as a key enabler of scientific reuse. All these results have been integrated in ROHub, a platform that provides research object management functionality to a wealth of applications and interfaces across different scientific communities. To monitor and quantify the community uptake of research objects, we have defined indicators and obtained measures via ROHub that are also discussed herein.