 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Transformers for Bot Detection in Twitter
Apr 13, 2021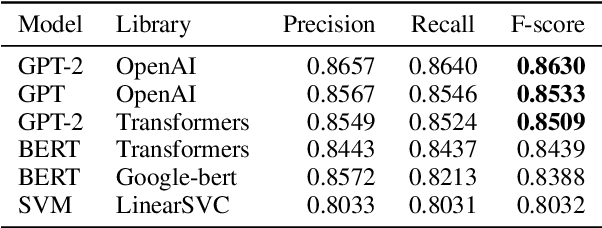

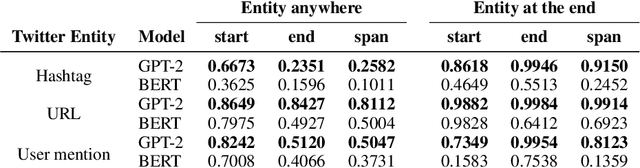
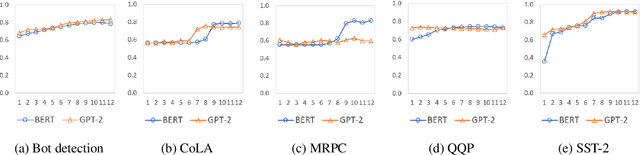
In this paper we shed light on the impact of fine-tuning over social media data in the internal representations of neural language models. We focus on bot detection in Twitter, a key task to mitigate and counteract the automatic spreading of disinformation and bias in social media. We investigate the use of pre-trained language models to tackle the detection of tweets generated by a bot or a human account based exclusively on its content. Unlike the general trend in benchmarks like GLUE, where BERT generally outperforms generative transformers like GPT and GPT-2 for most classification tasks on regular text, we observe that fine-tuning generative transformers on a bot detection task produces higher accuracies. We analyze the architectural components of each transformer and study the effect of fine-tuning on their hidden states and output representations. Among our findings, we show that part of the syntactical information and distributional properties captured by BERT during pre-training is lost upon fine-tuning while the generative pre-training approach manage to preserve these properties.