 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeISAAQ -- Mastering Textbook Questions with Pre-trained Transformers and Bottom-Up and Top-Down Attention
Oct 01, 2020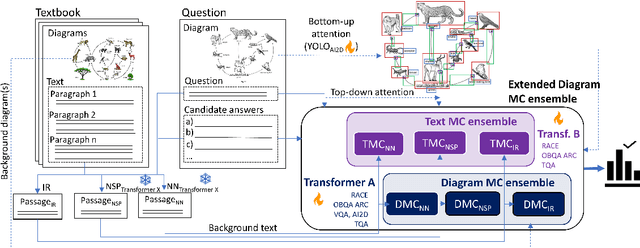
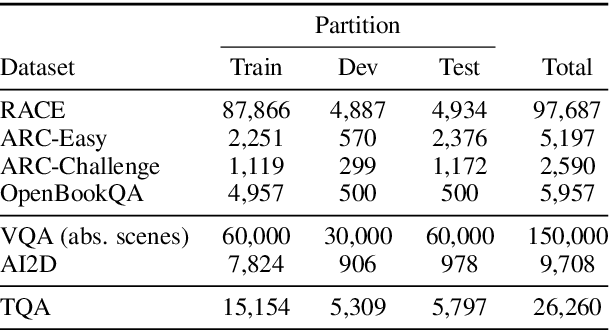
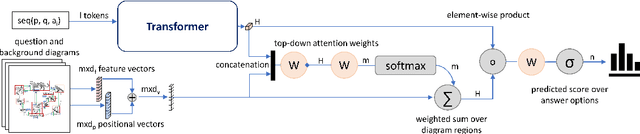
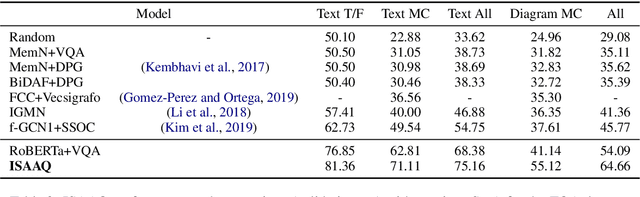
Textbook Question Answering is a complex task in the intersection of Machine Comprehension and Visual Question Answering that requires reasoning with multimodal information from text and diagrams. For the first time, this paper taps on the potential of transformer language models and bottom-up and top-down attention to tackle the language and visual understanding challenges this task entails. Rather than training a language-visual transformer from scratch we rely on pre-trained transformers, fine-tuning and ensembling. We add bottom-up and top-down attention to identify regions of interest corresponding to diagram constituents and their relationships, improving the selection of relevant visual information for each question and answer options. Our system ISAAQ reports unprecedented success in all TQA question types, with accuracies of 81.36%, 71.11% and 55.12% on true/false, text-only and diagram multiple choice questions. ISAAQ also demonstrates its broad applicability, obtaining state-of-the-art results in other demanding datasets.
Look, Read and Enrich. Learning from Scientific Figures and their Captions
Sep 19, 2019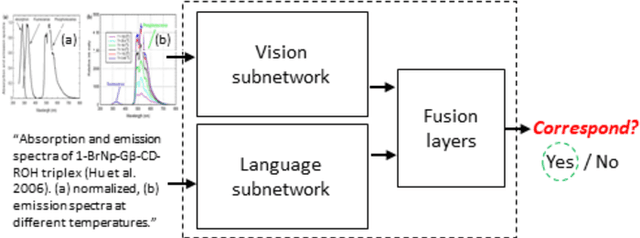
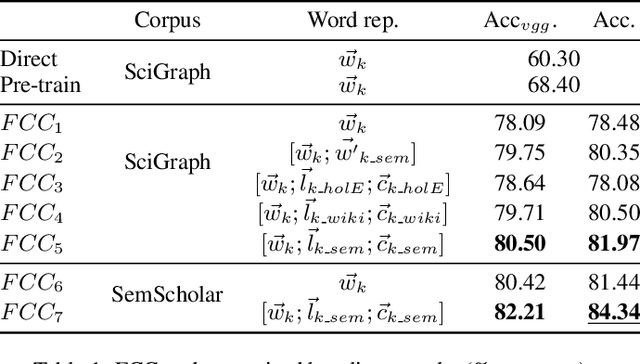

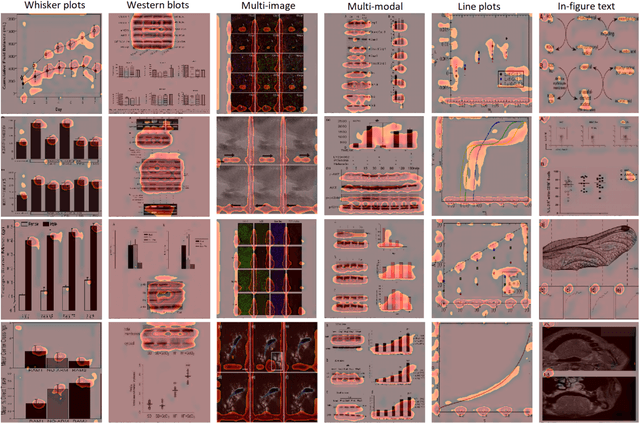
Compared to natural images, understanding scientific figures is particularly hard for machines. However, there is a valuable source of information in scientific literature that until now has remained untapped: the correspondence between a figure and its caption. In this paper we investigate what can be learnt by looking at a large number of figures and reading their captions, and introduce a figure-caption correspondence learning task that makes use of our observations. Training visual and language networks without supervision other than pairs of unconstrained figures and captions is shown to successfully solve this task. We also show that transferring lexical and semantic knowledge from a knowledge graph significantly enriches the resulting features. Finally, we demonstrate the positive impact of such features in other tasks involving scientific text and figures, like multi-modal classification and machine comprehension for question answering, outperforming supervised baselines and ad-hoc approaches.