 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchically Disentangled Recurrent Network for Factorizing System Dynamics of Multi-scale Systems
Jul 29, 2024We present a knowledge-guided machine learning (KGML) framework for modeling multi-scale processes, and study its performance in the context of streamflow forecasting in hydrology. Specifically, we propose a novel hierarchical recurrent neural architecture that factorizes the system dynamics at multiple temporal scales and captures their interactions. This framework consists of an inverse and a forward model. The inverse model is used to empirically resolve the system's temporal modes from data (physical model simulations, observed data, or a combination of them from the past), and these states are then used in the forward model to predict streamflow. In a hydrological system, these modes can represent different processes, evolving at different temporal scales (e.g., slow: groundwater recharge and baseflow vs. fast: surface runoff due to extreme rainfall). A key advantage of our framework is that once trained, it can incorporate new observations into the model's context (internal state) without expensive optimization approaches (e.g., EnKF) that are traditionally used in physical sciences for data assimilation. Experiments with several river catchments from the NWS NCRFC region show the efficacy of this ML-based data assimilation framework compared to standard baselines, especially for basins that have a long history of observations. Even for basins that have a shorter observation history, we present two orthogonal strategies of training our FHNN framework: (a) using simulation data from imperfect simulations and (b) using observation data from multiple basins to build a global model. We show that both of these strategies (that can be used individually or together) are highly effective in mitigating the lack of training data. The improvement in forecast accuracy is particularly noteworthy for basins where local models perform poorly because of data sparsity.
Prescribed Fire Modeling using Knowledge-Guided Machine Learning for Land Management
Oct 02, 2023In recent years, the increasing threat of devastating wildfires has underscored the need for effective prescribed fire management. Process-based computer simulations have traditionally been employed to plan prescribed fires for wildfire prevention. However, even simplified process models like QUIC-Fire are too compute-intensive to be used for real-time decision-making, especially when weather conditions change rapidly. Traditional ML methods used for fire modeling offer computational speedup but struggle with physically inconsistent predictions, biased predictions due to class imbalance, biased estimates for fire spread metrics (e.g., burned area, rate of spread), and generalizability in out-of-distribution wind conditions. This paper introduces a novel machine learning (ML) framework that enables rapid emulation of prescribed fires while addressing these concerns. By incorporating domain knowledge, the proposed method helps reduce physical inconsistencies in fuel density estimates in data-scarce scenarios. To overcome the majority class bias in predictions, we leverage pre-existing source domain data to augment training data and learn the spread of fire more effectively. Finally, we overcome the problem of biased estimation of fire spread metrics by incorporating a hierarchical modeling structure to capture the interdependence in fuel density and burned area. Notably, improvement in fire metric (e.g., burned area) estimates offered by our framework makes it useful for fire managers, who often rely on these fire metric estimates to make decisions about prescribed burn management. Furthermore, our framework exhibits better generalization capabilities than the other ML-based fire modeling methods across diverse wind conditions and ignition patterns.
Realization of Causal Representation Learning to Adjust Confounding Bias in Latent Space
Nov 15, 2022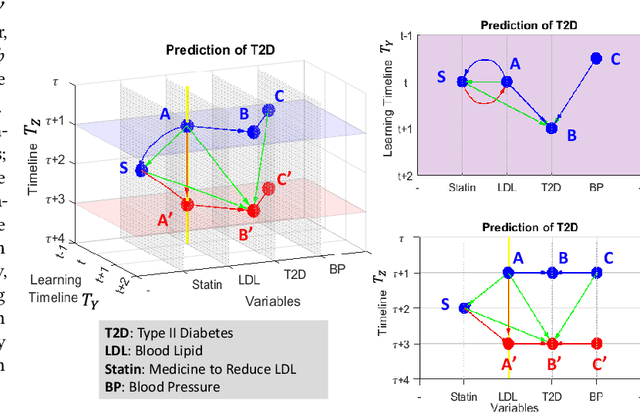
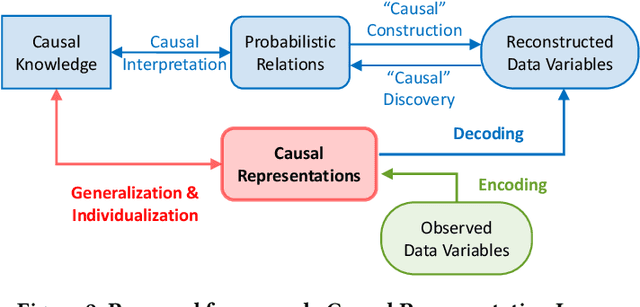
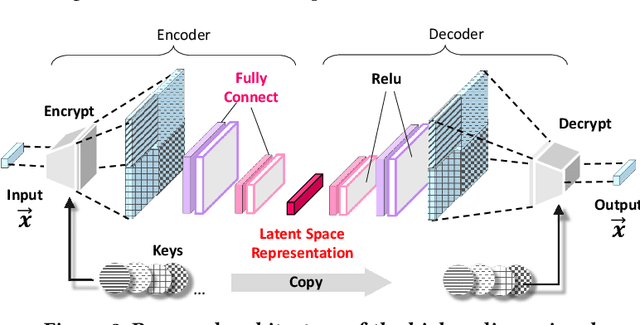
Applying Deep Learning (DL) models to graphical causal learning has brought outstanding effectiveness and efficiency but is still far from widespread use in domain sciences. In research of EHR (Electronic Healthcare Records), we realize that some confounding bias inherently exists in the causally formed data, which DL cannot automatically adjust. Trace to the source is because the Acyclic Causal Graph can be Multi-Dimensional, so the bias and causal learning happen in two subspaces, which makes it unobservable from the learning process. This paper initially raises the concept of Dimensionality for causal graphs. In our case, the 3-Dimensional DAG (Directed Acyclic Graph) space is defined by the axes of causal variables, the Absolute timeline, and Relative timelines; This is also the essential difference between Causality and Correlation problems. We propose a novel new framework Causal Representation Learning (CRL), to realize Graphical Causal Learning in latent space, which aims to provide general solutions for 1) the inherent bias adjustment and 2) the DL causal models generalization problem. We will also demonstrate the realization of CRL with originally designed architecture and experimentally confirm its feasibility.
Mini-Batch Learning Strategies for modeling long term temporal dependencies: A study in environmental applications
Oct 15, 2022
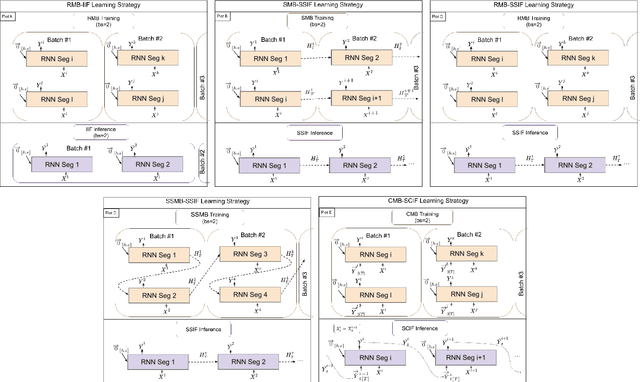
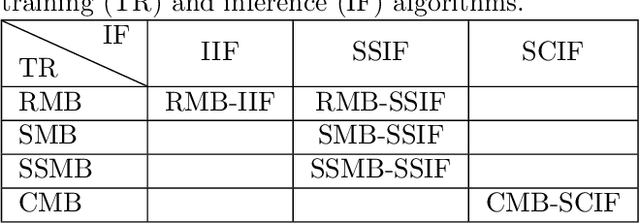
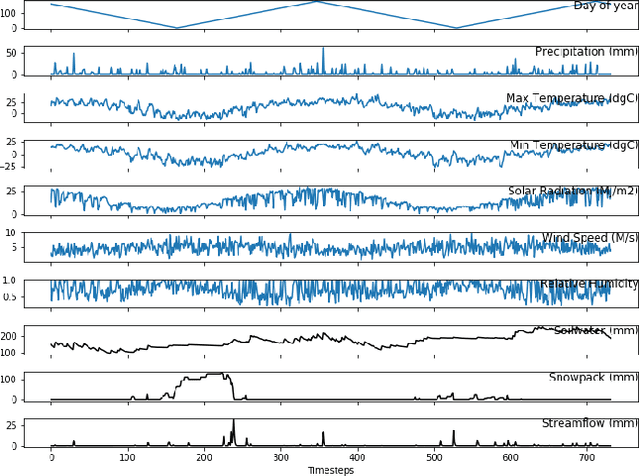
In many environmental applications, recurrent neural networks (RNNs) are often used to model physical variables with long temporal dependencies. However, due to mini-batch training, temporal relationships between training segments within the batch (intra-batch) as well as between batches (inter-batch) are not considered, which can lead to limited performance. Stateful RNNs aim to address this issue by passing hidden states between batches. Since Stateful RNNs ignore intra-batch temporal dependency, there exists a trade-off between training stability and capturing temporal dependency. In this paper, we provide a quantitative comparison of different Stateful RNN modeling strategies, and propose two strategies to enforce both intra- and inter-batch temporal dependency. First, we extend Stateful RNNs by defining a batch as a temporally ordered set of training segments, which enables intra-batch sharing of temporal information. While this approach significantly improves the performance, it leads to much larger training times due to highly sequential training. To address this issue, we further propose a new strategy which augments a training segment with an initial value of the target variable from the timestep right before the starting of the training segment. In other words, we provide an initial value of the target variable as additional input so that the network can focus on learning changes relative to that initial value. By using this strategy, samples can be passed in any order (mini-batch training) which significantly reduces the training time while maintaining the performance. In demonstrating our approach in hydrological modeling, we observe that the most significant gains in predictive accuracy occur when these methods are applied to state variables whose values change more slowly, such as soil water and snowpack, rather than continuously moving flux variables such as streamflow.
Teaching deep learning causal effects improves predictive performance
Nov 11, 2020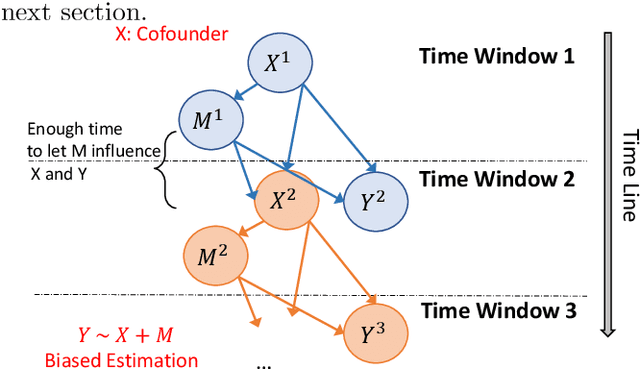
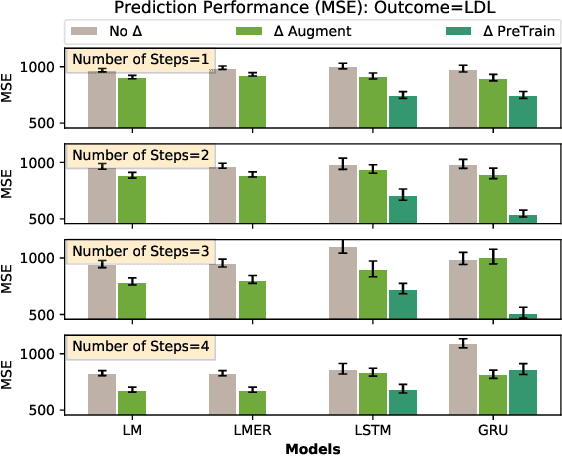
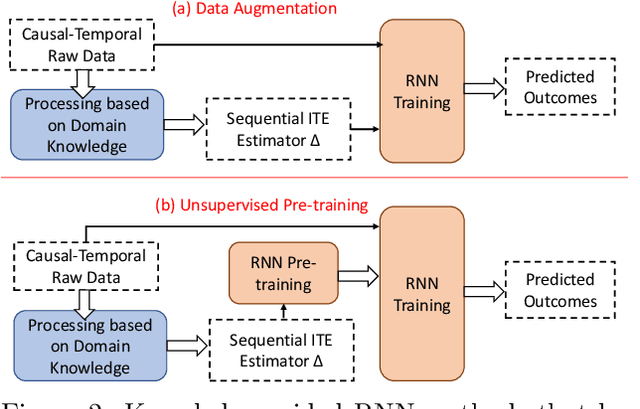
Causal inference is a powerful statistical methodology for explanatory analysis and individualized treatment effect (ITE) estimation, a prominent causal inference task that has become a fundamental research problem. ITE estimation, when performed naively, tends to produce biased estimates. To obtain unbiased estimates, counterfactual information is needed, which is not directly observable from data. Based on mature domain knowledge, reliable traditional methods to estimate ITE exist. In recent years, neural networks have been widely used in clinical studies. Specifically, recurrent neural networks (RNN) have been applied to temporal Electronic Health Records (EHR) data analysis. However, RNNs are not guaranteed to automatically discover causal knowledge, correctly estimate counterfactual information, and thus correctly estimate the ITE. This lack of correct ITE estimates can hinder the performance of the model. In this work we study whether RNNs can be guided to correctly incorporate ITE-related knowledge and whether this improves predictive performance. Specifically, we first describe a Causal-Temporal Structure for temporal EHR data; then based on this structure, we estimate sequential ITE along the timeline, using sequential Propensity Score Matching (PSM); and finally, we propose a knowledge-guided neural network methodology to incorporate estimated ITE. We demonstrate on real-world and synthetic data (where the actual ITEs are known) that the proposed methodology can significantly improve the prediction performance of RNN.
Physics-Guided Recurrent Graph Networks for Predicting Flow and Temperature in River Networks
Sep 26, 2020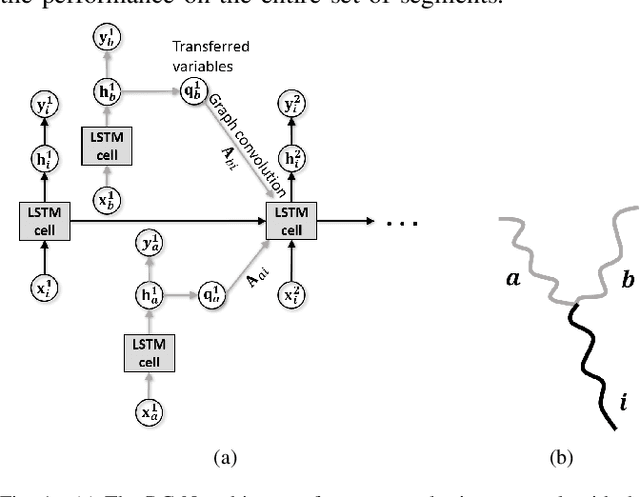
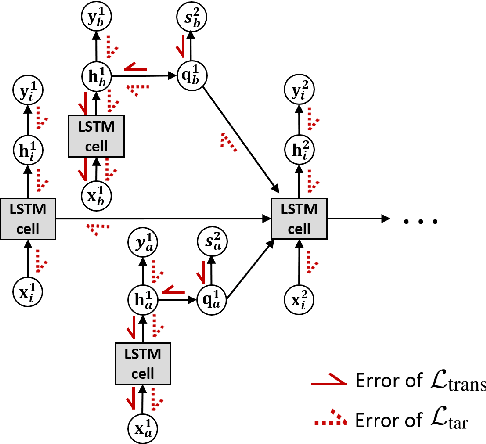
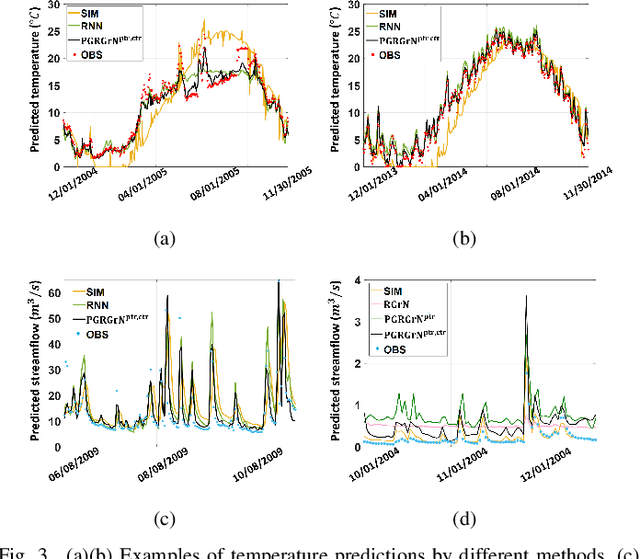
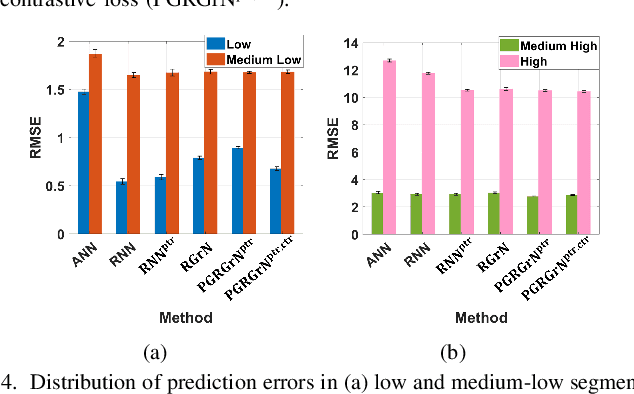
This paper proposes a physics-guided machine learning approach that combines advanced machine learning models and physics-based models to improve the prediction of water flow and temperature in river networks. We first build a recurrent graph network model to capture the interactions among multiple segments in the river network. Then we present a pre-training technique which transfers knowledge from physics-based models to initialize the machine learning model and learn the physics of streamflow and thermodynamics. We also propose a new loss function that balances the performance over different river segments. We demonstrate the effectiveness of the proposed method in predicting temperature and streamflow in a subset of the Delaware River Basin. In particular, we show that the proposed method brings a 33\%/14\% improvement over the state-of-the-art physics-based model and 24\%/14\% over traditional machine learning models (e.g., Long-Short Term Memory Neural Network) in temperature/streamflow prediction using very sparse (0.1\%) observation data for training. The proposed method has also been shown to produce better performance when generalized to different seasons or river segments with different streamflow ranges.
Integrating Physics-Based Modeling with Machine Learning: A Survey
Apr 01, 2020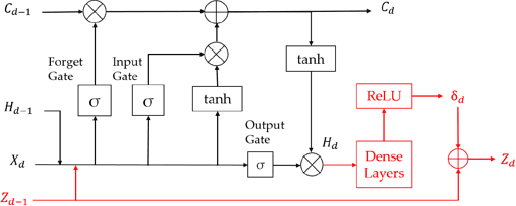
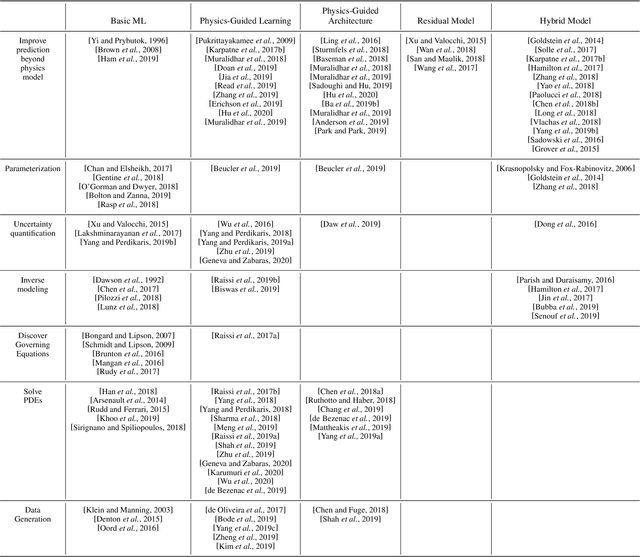
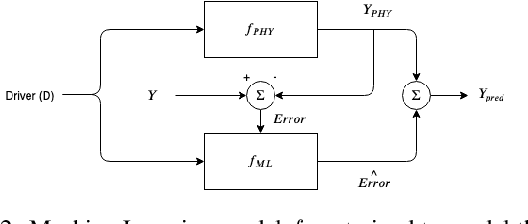
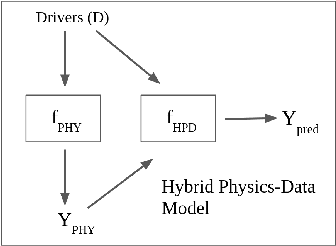
In this manuscript, we provide a structured and comprehensive overview of techniques to integrate machine learning with physics-based modeling. First, we provide a summary of application areas for which these approaches have been applied. Then, we describe classes of methodologies used to construct physics-guided machine learning models and hybrid physics-machine learning frameworks from a machine learning standpoint. With this foundation, we then provide a systematic organization of these existing techniques and discuss ideas for future research.
Physics-Guided Machine Learning for Scientific Discovery: An Application in Simulating Lake Temperature Profiles
Jan 28, 2020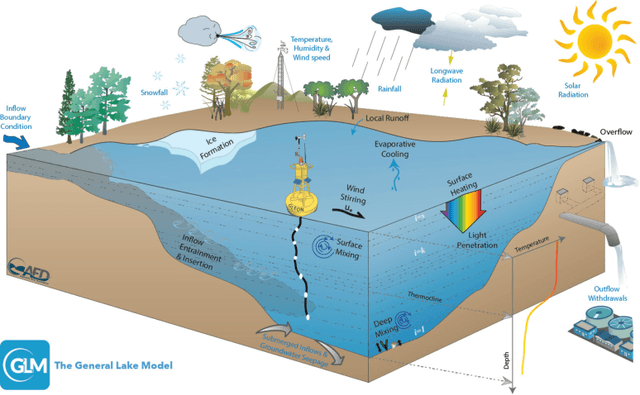

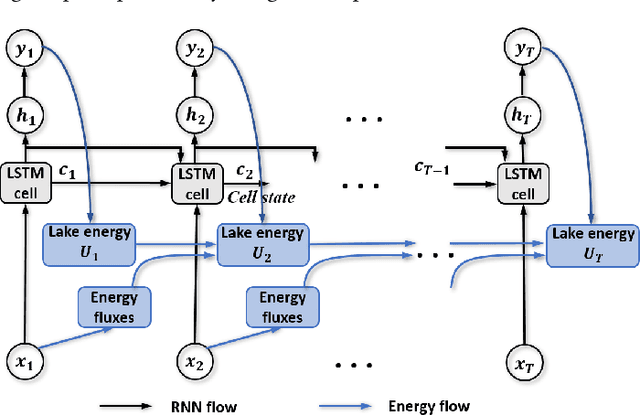

Physics-based models of dynamical systems are often used to study engineering and environmental systems. Despite their extensive use, these models have several well-known limitations due to simplified representations of the physical processes being modeled or challenges in selecting appropriate parameters. While-state-of-the-art machine learning models can sometimes outperform physics-based models given ample amount of training data, they can produce results that are physically inconsistent. This paper proposes a physics-guided recurrent neural network model (PGRNN) that combines RNNs and physics-based models to leverage their complementary strengths and improves the modeling of physical processes. Specifically, we show that a PGRNN can improve prediction accuracy over that of physics-based models, while generating outputs consistent with physical laws. An important aspect of our PGRNN approach lies in its ability to incorporate the knowledge encoded in physics-based models. This allows training the PGRNN model using very few true observed data while also ensuring high prediction accuracy. Although we present and evaluate this methodology in the context of modeling the dynamics of temperature in lakes, it is applicable more widely to a range of scientific and engineering disciplines where physics-based (also known as mechanistic) models are used, e.g., climate science, materials science, computational chemistry, and biomedicine.
Physics Guided RNNs for Modeling Dynamical Systems: A Case Study in Simulating Lake Temperature Profiles
Oct 31, 2018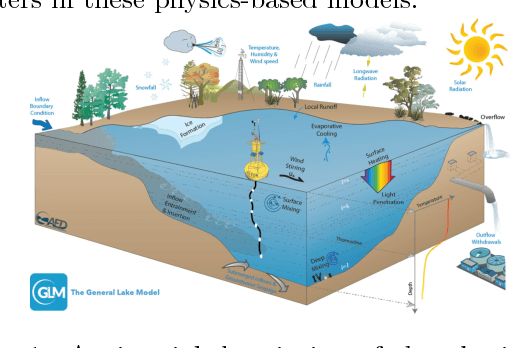
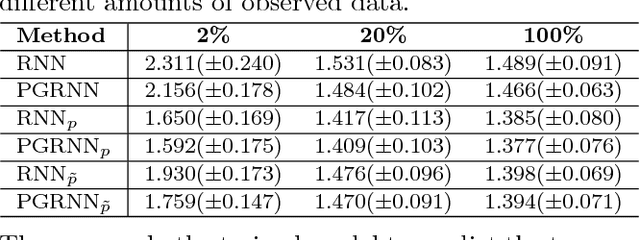
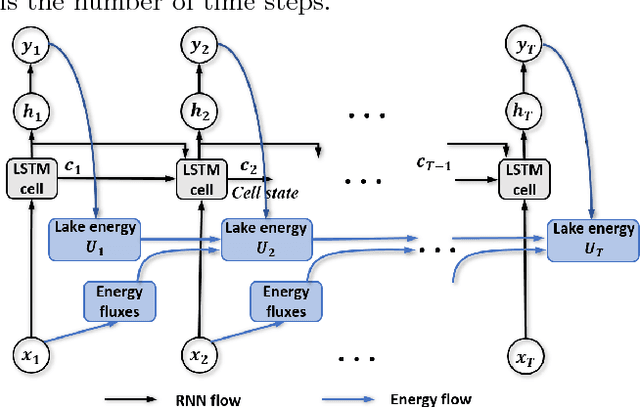
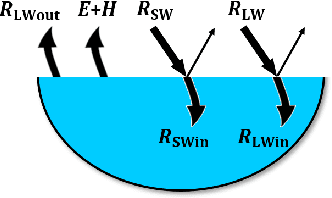
This paper proposes a physics-guided recurrent neural network model (PGRNN) that combines RNNs and physics-based models to leverage their complementary strengths and improve the modeling of physical processes. Specifically, we show that a PGRNN can improve prediction accuracy over that of physical models, while generating outputs consistent with physical laws, and achieving good generalizability. Standard RNNs, even when producing superior prediction accuracy, often produce physically inconsistent results and lack generalizability. We further enhance this approach by using a pre-training method that leverages the simulated data from a physics-based model to address the scarcity of observed data. The PGRNN has the flexibility to incorporate additional physical constraints and we incorporate a density-depth relationship. Both enhancements further improve PGRNN performance. Although we present and evaluate this methodology in the context of modeling the dynamics of temperature in lakes, it is applicable more widely to a range of scientific and engineering disciplines where mechanistic (also known as process-based) models are used, e.g., power engineering, climate science, materials science, computational chemistry, and biomedicine.
Theory-guided Data Science: A New Paradigm for Scientific Discovery from Data
Nov 13, 2017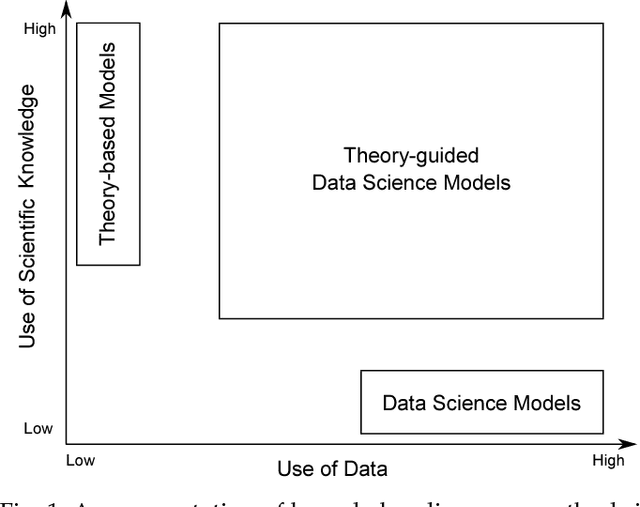

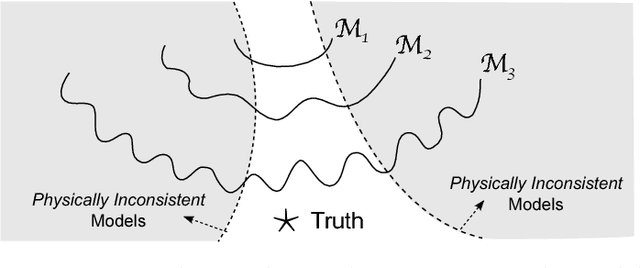
Data science models, although successful in a number of commercial domains, have had limited applicability in scientific problems involving complex physical phenomena. Theory-guided data science (TGDS) is an emerging paradigm that aims to leverage the wealth of scientific knowledge for improving the effectiveness of data science models in enabling scientific discovery. The overarching vision of TGDS is to introduce scientific consistency as an essential component for learning generalizable models. Further, by producing scientifically interpretable models, TGDS aims to advance our scientific understanding by discovering novel domain insights. Indeed, the paradigm of TGDS has started to gain prominence in a number of scientific disciplines such as turbulence modeling, material discovery, quantum chemistry, bio-medical science, bio-marker discovery, climate science, and hydrology. In this paper, we formally conceptualize the paradigm of TGDS and present a taxonomy of research themes in TGDS. We describe several approaches for integrating domain knowledge in different research themes using illustrative examples from different disciplines. We also highlight some of the promising avenues of novel research for realizing the full potential of theory-guided data science.