 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCHAM-net: A Contrastive Hierarchical Adaptive Meta-network for Robust Global Methane Flux Prediction
May 29, 2026Methane is a potent greenhouse gas that significantly contributes to global warming. However, accurately estimating global methane emissions and consumption remains challenging due to the complex interactions among environmental drivers that may vary across spatial and temporal scales. Prior data-driven methods often overlook the inherent spatiotemporal heterogeneity of ecosystems, failing to explicitly capture site-specific characteristics and cross-year evolutionary dynamics. To address these issues, we propose the Contrastive Hierarchical Adaptive Meta-network (CHAM-net), a novel framework that explicitly learns from historical context to capture site-specific dynamics. CHAM-net employs a hierarchical encoder-decoder architecture, in which the encoder captures site-specific characteristics from historical data and then dynamically conditions the decoder to generate the final prediction. Experimental results demonstrate that CHAM-net consistently outperforms all baseline methods on both simulation and observational datasets for methane emission and consumption, achieving nRMSE values as low as 0.43 and 0.88 with corresponding R2 scores up to 0.97 and 0.68 for emission prediction.
CocoaBench: Evaluating Unified Digital Agents in the Wild
Apr 14, 2026LLM agents now perform strongly in software engineering, deep research, GUI automation, and various other applications, while recent agent scaffolds and models are increasingly integrating these capabilities into unified systems. Yet, most evaluations still test these capabilities in isolation, which leaves a gap for more diverse use cases that require agents to combine different capabilities. We introduce CocoaBench, a benchmark for unified digital agents built from human-designed, long-horizon tasks that require flexible composition of vision, search, and coding. Tasks are specified only by an instruction and an automatic evaluation function over the final output, enabling reliable and scalable evaluation across diverse agent infrastructures. We also present CocoaAgent, a lightweight shared scaffold for controlled comparison across model backbones. Experiments show that current agents remain far from reliable on CocoaBench, with the best evaluated system achieving only 45.1% success rate. Our analysis further points to substantial room for improvement in reasoning and planning, tool use and execution, and visual grounding.
RAGEN-2: Reasoning Collapse in Agentic RL
Apr 07, 2026RL training of multi-turn LLM agents is inherently unstable, and reasoning quality directly determines task performance. Entropy is widely used to track reasoning stability. However, entropy only measures diversity within the same input, and cannot tell whether reasoning actually responds to different inputs. In RAGEN-2, we find that even with stable entropy, models can rely on fixed templates that look diverse but are input-agnostic. We call this template collapse, a failure mode invisible to entropy and all existing metrics. To diagnose this failure, we decompose reasoning quality into within-input diversity (Entropy) and cross-input distinguishability (Mutual Information, MI), and introduce a family of mutual information proxies for online diagnosis. Across diverse tasks, mutual information correlates with final performance much more strongly than entropy, making it a more reliable proxy for reasoning quality. We further explain template collapse with a signal-to-noise ratio (SNR) mechanism. Low reward variance weakens task gradients, letting regularization terms dominate and erase cross-input reasoning differences. To address this, we propose SNR-Aware Filtering to select high-signal prompts per iteration using reward variance as a lightweight proxy. Across planning, math reasoning, web navigation, and code execution, the method consistently improves both input dependence and task performance.
Role-Aware Conditional Inference for Spatiotemporal Ecosystem Carbon Flux Prediction
Mar 03, 2026Accurate prediction of terrestrial ecosystem carbon fluxes (e.g., CO$_2$, GPP, and CH$_4$) is essential for understanding the global carbon cycle and managing its impacts. However, prediction remains challenging due to strong spatiotemporal heterogeneity: ecosystem flux responses are constrained by slowly varying regime conditions, while short-term fluctuations are driven by high-frequency dynamic forcings. Most existing learning-based approaches treat environmental covariates as a homogeneous input space, implicitly assuming a global response function, which leads to brittle generalization across heterogeneous ecosystems. In this work, we propose Role-Aware Conditional Inference (RACI), a process-informed learning framework that formulates ecosystem flux prediction as a conditional inference problem. RACI employs hierarchical temporal encoding to disentangle slow regime conditioners from fast dynamic drivers, and incorporates role-aware spatial retrieval that supplies functionally similar and geographically local context for each role. By explicitly modeling these distinct functional roles, RACI enables a model to adapt its predictions across diverse environmental regimes without training separate local models or relying on fixed spatial structures. We evaluate RACI across multiple ecosystem types (wetlands and agricultural systems), carbon fluxes (CO$_2$, GPP, CH$_4$), and data sources, including both process-based simulations and observational measurements. Across all settings, RACI consistently outperforms competitive spatiotemporal baselines, demonstrating improved accuracy and spatial generalization under pronounced environmental heterogeneity.
AgroFlux: A Spatial-Temporal Benchmark for Carbon and Nitrogen Flux Prediction in Agricultural Ecosystems
Feb 02, 2026Agroecosystem, which heavily influenced by human actions and accounts for a quarter of global greenhouse gas emissions (GHGs), plays a crucial role in mitigating global climate change and securing environmental sustainability. However, we can't manage what we can't measure. Accurately quantifying the pools and fluxes in the carbon, nutrient, and water nexus of the agroecosystem is therefore essential for understanding the underlying drivers of GHG and developing effective mitigation strategies. Conventional approaches like soil sampling, process-based models, and black-box machine learning models are facing challenges such as data sparsity, high spatiotemporal heterogeneity, and complex subsurface biogeochemical and physical processes. Developing new trustworthy approaches such as AI-empowered models, will require the AI-ready benchmark dataset and outlined protocols, which unfortunately do not exist. In this work, we introduce a first-of-its-kind spatial-temporal agroecosystem GHG benchmark dataset that integrates physics-based model simulations from Ecosys and DayCent with real-world observations from eddy covariance flux towers and controlled-environment facilities. We evaluate the performance of various sequential deep learning models on carbon and nitrogen flux prediction, including LSTM-based models, temporal CNN-based model, and Transformer-based models. Furthermore, we explored transfer learning to leverage simulated data to improve the generalization of deep learning models on real-world observations. Our benchmark dataset and evaluation framework contribute to the development of more accurate and scalable AI-driven agroecosystem models, advancing our understanding of ecosystem-climate interactions.
Towards Fine-Tuning-Based Site Calibration for Knowledge-Guided Machine Learning: A Summary of Results
Dec 17, 2025Accurate and cost-effective quantification of the agroecosystem carbon cycle at decision-relevant scales is essential for climate mitigation and sustainable agriculture. However, both transfer learning and the exploitation of spatial variability in this field are challenging, as they involve heterogeneous data and complex cross-scale dependencies. Conventional approaches often rely on location-independent parameterizations and independent training, underutilizing transfer learning and spatial heterogeneity in the inputs, and limiting their applicability in regions with substantial variability. We propose FTBSC-KGML (Fine-Tuning-Based Site Calibration-Knowledge-Guided Machine Learning), a pretraining- and fine-tuning-based, spatial-variability-aware, and knowledge-guided machine learning framework that augments KGML-ag with a pretraining-fine-tuning process and site-specific parameters. Using a pretraining-fine-tuning process with remote-sensing GPP, climate, and soil covariates collected across multiple midwestern sites, FTBSC-KGML estimates land emissions while leveraging transfer learning and spatial heterogeneity. A key component is a spatial-heterogeneity-aware transfer-learning scheme, which is a globally pretrained model that is fine-tuned at each state or site to learn place-aware representations, thereby improving local accuracy under limited data without sacrificing interpretability. Empirically, FTBSC-KGML achieves lower validation error and greater consistency in explanatory power than a purely global model, thereby better capturing spatial variability across states. This work extends the prior SDSA-KGML framework.
X-MethaneWet: A Cross-scale Global Wetland Methane Emission Benchmark Dataset for Advancing Science Discovery with AI
May 23, 2025Methane (CH$_4$) is the second most powerful greenhouse gas after carbon dioxide and plays a crucial role in climate change due to its high global warming potential. Accurately modeling CH$_4$ fluxes across the globe and at fine temporal scales is essential for understanding its spatial and temporal variability and developing effective mitigation strategies. In this work, we introduce the first-of-its-kind cross-scale global wetland methane benchmark dataset (X-MethaneWet), which synthesizes physics-based model simulation data from TEM-MDM and the real-world observation data from FLUXNET-CH$_4$. This dataset can offer opportunities for improving global wetland CH$_4$ modeling and science discovery with new AI algorithms. To set up AI model baselines for methane flux prediction, we evaluate the performance of various sequential deep learning models on X-MethaneWet. Furthermore, we explore four different transfer learning techniques to leverage simulated data from TEM-MDM to improve the generalization of deep learning models on real-world FLUXNET-CH$_4$ observations. Our extensive experiments demonstrate the effectiveness of these approaches, highlighting their potential for advancing methane emission modeling and contributing to the development of more accurate and scalable AI-driven climate models.
LLM-based Evaluation Policy Extraction for Ecological Modeling
May 20, 2025Evaluating ecological time series is critical for benchmarking model performance in many important applications, including predicting greenhouse gas fluxes, capturing carbon-nitrogen dynamics, and monitoring hydrological cycles. Traditional numerical metrics (e.g., R-squared, root mean square error) have been widely used to quantify the similarity between modeled and observed ecosystem variables, but they often fail to capture domain-specific temporal patterns critical to ecological processes. As a result, these methods are often accompanied by expert visual inspection, which requires substantial human labor and limits the applicability to large-scale evaluation. To address these challenges, we propose a novel framework that integrates metric learning with large language model (LLM)-based natural language policy extraction to develop interpretable evaluation criteria. The proposed method processes pairwise annotations and implements a policy optimization mechanism to generate and combine different assessment metrics. The results obtained on multiple datasets for evaluating the predictions of crop gross primary production and carbon dioxide flux have confirmed the effectiveness of the proposed method in capturing target assessment preferences, including both synthetically generated and expert-annotated model comparisons. The proposed framework bridges the gap between numerical metrics and expert knowledge while providing interpretable evaluation policies that accommodate the diverse needs of different ecosystem modeling studies.
Knowledge Guided Encoder-Decoder Framework: Integrating Multiple Physical Models for Agricultural Ecosystem Modeling
May 13, 2025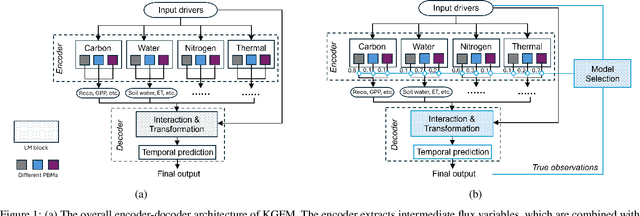
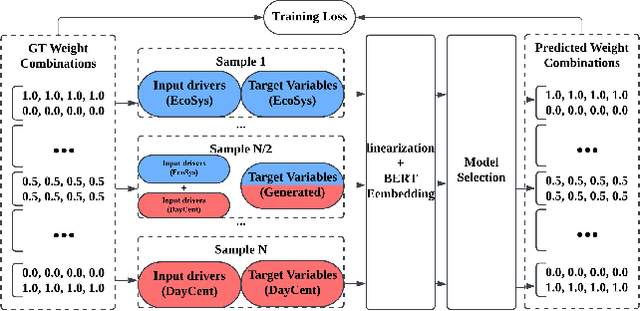
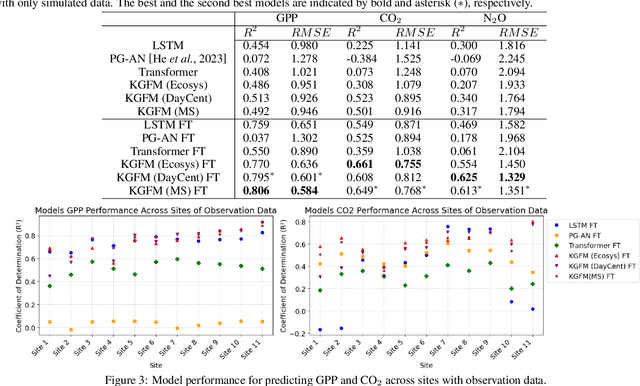
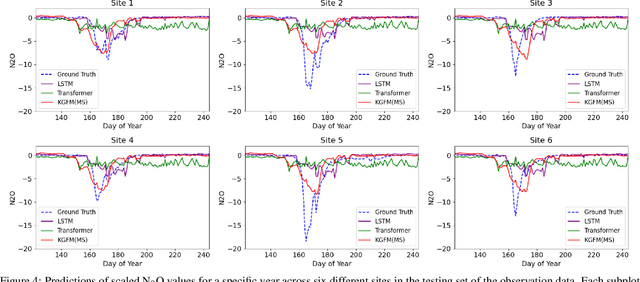
Agricultural monitoring is critical for ensuring food security, maintaining sustainable farming practices, informing policies on mitigating food shortage, and managing greenhouse gas emissions. Traditional process-based physical models are often designed and implemented for specific situations, and their parameters could also be highly uncertain. In contrast, data-driven models often use black-box structures and does not explicitly model the inter-dependence between different ecological variables. As a result, they require extensive training data and lack generalizability to different tasks with data distribution shifts and inconsistent observed variables. To address the need for more universal models, we propose a knowledge-guided encoder-decoder model, which can predict key crop variables by leveraging knowledge of underlying processes from multiple physical models. The proposed method also integrates a language model to process complex and inconsistent inputs and also utilizes it to implement a model selection mechanism for selectively combining the knowledge from different physical models. Our evaluations on predicting carbon and nitrogen fluxes for multiple sites demonstrate the effectiveness and robustness of the proposed model under various scenarios.
RAGEN: Understanding Self-Evolution in LLM Agents via Multi-Turn Reinforcement Learning
Apr 24, 2025Training large language models (LLMs) as interactive agents presents unique challenges including long-horizon decision making and interacting with stochastic environment feedback. While reinforcement learning (RL) has enabled progress in static tasks, multi-turn agent RL training remains underexplored. We propose StarPO (State-Thinking-Actions-Reward Policy Optimization), a general framework for trajectory-level agent RL, and introduce RAGEN, a modular system for training and evaluating LLM agents. Our study on three stylized environments reveals three core findings. First, our agent RL training shows a recurring mode of Echo Trap where reward variance cliffs and gradient spikes; we address this with StarPO-S, a stabilized variant with trajectory filtering, critic incorporation, and decoupled clipping. Second, we find the shaping of RL rollouts would benefit from diverse initial states, medium interaction granularity and more frequent sampling. Third, we show that without fine-grained, reasoning-aware reward signals, agent reasoning hardly emerge through multi-turn RL and they may show shallow strategies or hallucinated thoughts. Code and environments are available at https://github.com/RAGEN-AI/RAGEN.