 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetection of Breast Cancer Lumpectomy Margin with SAM-incorporated Forward-Forward Contrastive Learning
Jun 26, 2025Complete removal of cancer tumors with a negative specimen margin during lumpectomy is essential in reducing breast cancer recurrence. However, 2D specimen radiography (SR), the current method used to assess intraoperative specimen margin status, has limited accuracy, resulting in nearly a quarter of patients requiring additional surgery. To address this, we propose a novel deep learning framework combining the Segment Anything Model (SAM) with Forward-Forward Contrastive Learning (FFCL), a pre-training strategy leveraging both local and global contrastive learning for patch-level classification of SR images. After annotating SR images with regions of known maligancy, non-malignant tissue, and pathology-confirmed margins, we pre-train a ResNet-18 backbone with FFCL to classify margin status, then reconstruct coarse binary masks to prompt SAM for refined tumor margin segmentation. Our approach achieved an AUC of 0.8455 for margin classification and segmented margins with a 27.4% improvement in Dice similarity over baseline models, while reducing inference time to 47 milliseconds per image. These results demonstrate that FFCL-SAM significantly enhances both the speed and accuracy of intraoperative margin assessment, with strong potential to reduce re-excision rates and improve surgical outcomes in breast cancer treatment. Our code is available at https://github.com/tbwa233/FFCL-SAM/.
FaceBench: A Multi-View Multi-Level Facial Attribute VQA Dataset for Benchmarking Face Perception MLLMs
Mar 27, 2025



Multimodal large language models (MLLMs) have demonstrated remarkable capabilities in various tasks. However, effectively evaluating these MLLMs on face perception remains largely unexplored. To address this gap, we introduce FaceBench, a dataset featuring hierarchical multi-view and multi-level attributes specifically designed to assess the comprehensive face perception abilities of MLLMs. Initially, we construct a hierarchical facial attribute structure, which encompasses five views with up to three levels of attributes, totaling over 210 attributes and 700 attribute values. Based on the structure, the proposed FaceBench consists of 49,919 visual question-answering (VQA) pairs for evaluation and 23,841 pairs for fine-tuning. Moreover, we further develop a robust face perception MLLM baseline, Face-LLaVA, by training with our proposed face VQA data. Extensive experiments on various mainstream MLLMs and Face-LLaVA are conducted to test their face perception ability, with results also compared against human performance. The results reveal that, the existing MLLMs are far from satisfactory in understanding the fine-grained facial attributes, while our Face-LLaVA significantly outperforms existing open-source models with a small amount of training data and is comparable to commercial ones like GPT-4o and Gemini. The dataset will be released at https://github.com/CVI-SZU/FaceBench.
MentalGLM Series: Explainable Large Language Models for Mental Health Analysis on Chinese Social Media
Oct 14, 2024
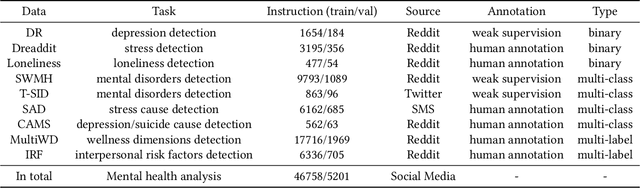
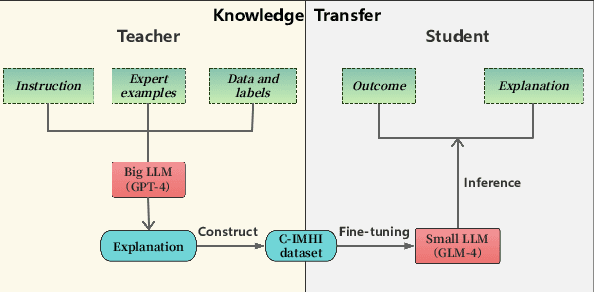

As the prevalence of mental health challenges, social media has emerged as a key platform for individuals to express their emotions.Deep learning tends to be a promising solution for analyzing mental health on social media. However, black box models are often inflexible when switching between tasks, and their results typically lack explanations. With the rise of large language models (LLMs), their flexibility has introduced new approaches to the field. Also due to the generative nature, they can be prompted to explain decision-making processes. However, their performance on complex psychological analysis still lags behind deep learning. In this paper, we introduce the first multi-task Chinese Social Media Interpretable Mental Health Instructions (C-IMHI) dataset, consisting of 9K samples, which has been quality-controlled and manually validated. We also propose MentalGLM series models, the first open-source LLMs designed for explainable mental health analysis targeting Chinese social media, trained on a corpus of 50K instructions. The proposed models were evaluated on three downstream tasks and achieved better or comparable performance compared to deep learning models, generalized LLMs, and task fine-tuned LLMs. We validated a portion of the generated decision explanations with experts, showing promising results. We also evaluated the proposed models on a clinical dataset, where they outperformed other LLMs, indicating their potential applicability in the clinical field. Our models show strong performance, validated across tasks and perspectives. The decision explanations enhance usability and facilitate better understanding and practical application of the models. Both the constructed dataset and the models are publicly available via: https://github.com/zwzzzQAQ/MentalGLM.
AI-Enhanced Cognitive Behavioral Therapy: Deep Learning and Large Language Models for Extracting Cognitive Pathways from Social Media Texts
Apr 17, 2024



Cognitive Behavioral Therapy (CBT) is an effective technique for addressing the irrational thoughts stemming from mental illnesses, but it necessitates precise identification of cognitive pathways to be successfully implemented in patient care. In current society, individuals frequently express negative emotions on social media on specific topics, often exhibiting cognitive distortions, including suicidal behaviors in extreme cases. Yet, there is a notable absence of methodologies for analyzing cognitive pathways that could aid psychotherapists in conducting effective interventions online. In this study, we gathered data from social media and established the task of extracting cognitive pathways, annotating the data based on a cognitive theoretical framework. We initially categorized the task of extracting cognitive pathways as a hierarchical text classification with four main categories and nineteen subcategories. Following this, we structured a text summarization task to help psychotherapists quickly grasp the essential information. Our experiments evaluate the performance of deep learning and large language models (LLMs) on these tasks. The results demonstrate that our deep learning method achieved a micro-F1 score of 62.34% in the hierarchical text classification task. Meanwhile, in the text summarization task, GPT-4 attained a Rouge-1 score of 54.92 and a Rouge-2 score of 30.86, surpassing the experimental deep learning model's performance. However, it may suffer from an issue of hallucination. We have made all models and codes publicly available to support further research in this field.
Binary Representation via Jointly Personalized Sparse Hashing
Aug 31, 2022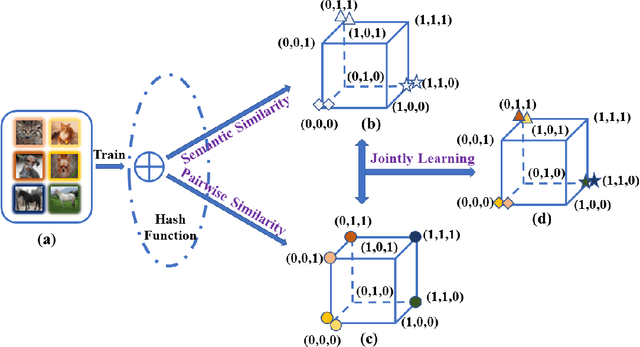
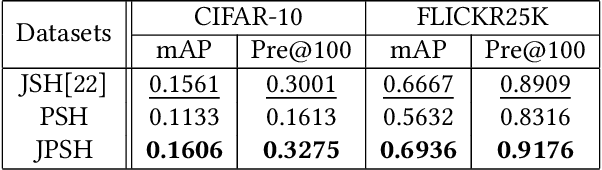
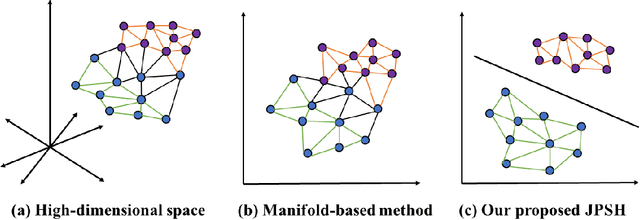
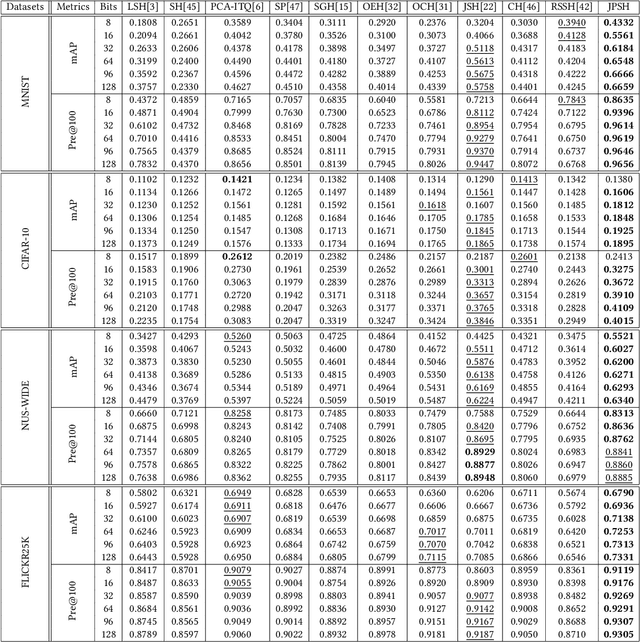
Unsupervised hashing has attracted much attention for binary representation learning due to the requirement of economical storage and efficiency of binary codes. It aims to encode high-dimensional features in the Hamming space with similarity preservation between instances. However, most existing methods learn hash functions in manifold-based approaches. Those methods capture the local geometric structures (i.e., pairwise relationships) of data, and lack satisfactory performance in dealing with real-world scenarios that produce similar features (e.g. color and shape) with different semantic information. To address this challenge, in this work, we propose an effective unsupervised method, namely Jointly Personalized Sparse Hashing (JPSH), for binary representation learning. To be specific, firstly, we propose a novel personalized hashing module, i.e., Personalized Sparse Hashing (PSH). Different personalized subspaces are constructed to reflect category-specific attributes for different clusters, adaptively mapping instances within the same cluster to the same Hamming space. In addition, we deploy sparse constraints for different personalized subspaces to select important features. We also collect the strengths of the other clusters to build the PSH module with avoiding over-fitting. Then, to simultaneously preserve semantic and pairwise similarities in our JPSH, we incorporate the PSH and manifold-based hash learning into the seamless formulation. As such, JPSH not only distinguishes the instances from different clusters, but also preserves local neighborhood structures within the cluster. Finally, an alternating optimization algorithm is adopted to iteratively capture analytical solutions of the JPSH model. Extensive experiments on four benchmark datasets verify that the JPSH outperforms several hashing algorithms on the similarity search task.
CE-based white-box adversarial attacks will not work using super-fitting
May 15, 2022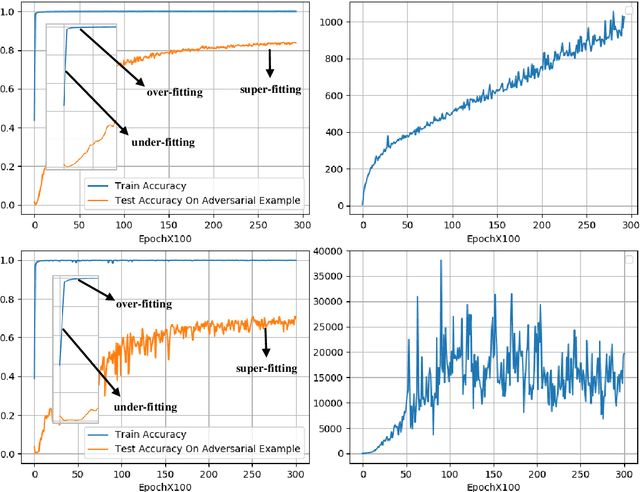
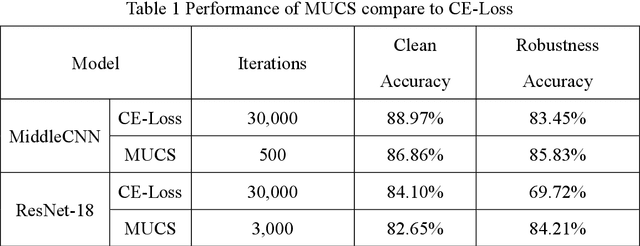
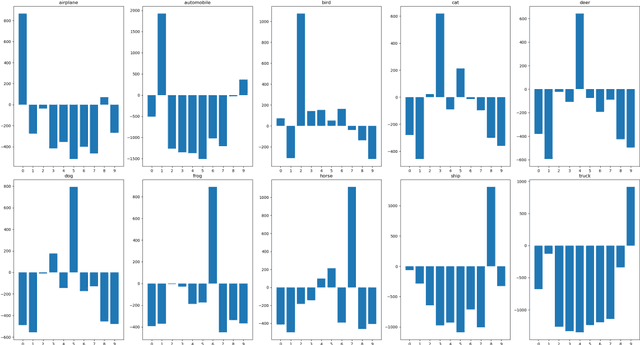
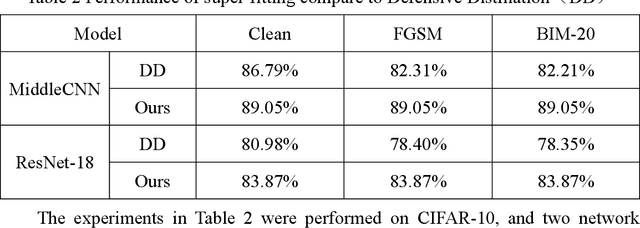
Deep neural networks are widely used in various fields because of their powerful performance. However, recent studies have shown that deep learning models are vulnerable to adversarial attacks, i.e., adding a slight perturbation to the input will make the model obtain wrong results. This is especially dangerous for some systems with high-security requirements, so this paper proposes a new defense method by using the model super-fitting state to improve the model's adversarial robustness (i.e., the accuracy under adversarial attacks). This paper mathematically proves the effectiveness of super-fitting and enables the model to reach this state quickly by minimizing unrelated category scores (MUCS). Theoretically, super-fitting can resist any existing (even future) CE-based white-box adversarial attacks. In addition, this paper uses a variety of powerful attack algorithms to evaluate the adversarial robustness of super-fitting, and the proposed method is compared with nearly 50 defense models from recent conferences. The experimental results show that the super-fitting method in this paper can make the trained model obtain the highest adversarial robustness.
Rethinking Classifier and Adversarial Attack
May 14, 2022
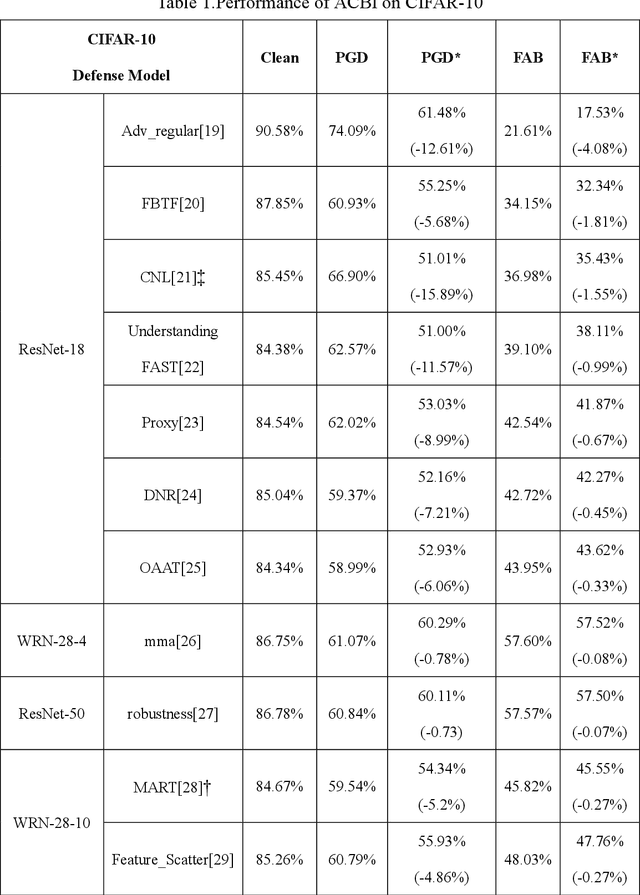
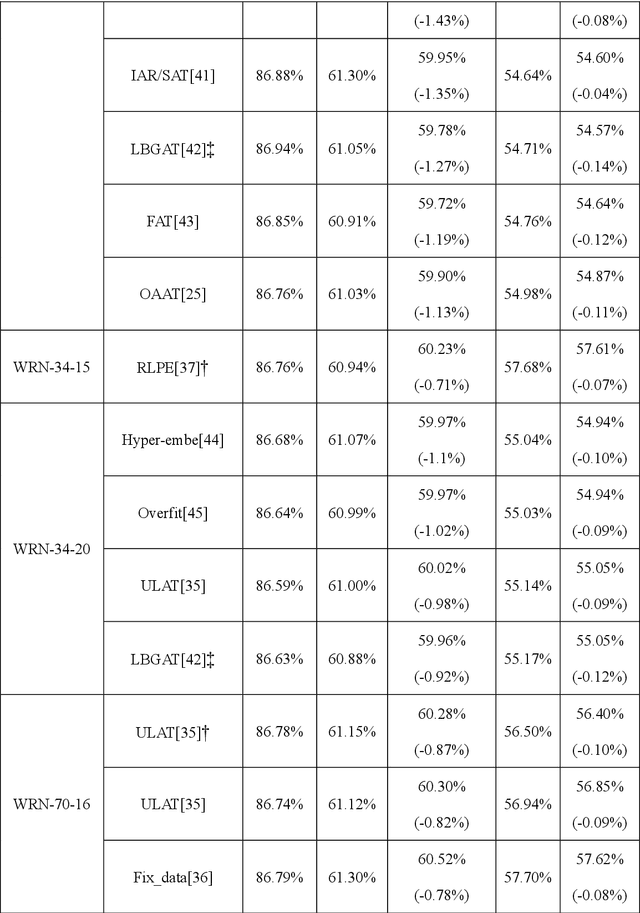
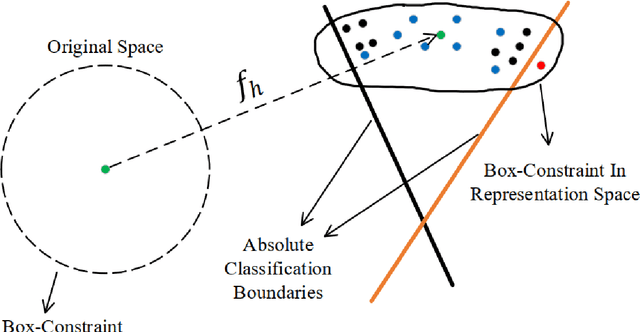
Various defense models have been proposed to resist adversarial attack algorithms, but existing adversarial robustness evaluation methods always overestimate the adversarial robustness of these models (i.e., not approaching the lower bound of robustness). To solve this problem, this paper uses the proposed decouple space method to divide the classifier into two parts: non-linear and linear. Then, this paper defines the representation vector of the original example (and its space, i.e., the representation space) and uses the iterative optimization of Absolute Classification Boundaries Initialization (ACBI) to obtain a better attack starting point. Particularly, this paper applies ACBI to nearly 50 widely-used defense models (including 8 architectures). Experimental results show that ACBI achieves lower robust accuracy in all cases.
Weakly-Supervised Feature Learning via Text and Image Matching
Oct 06, 2020

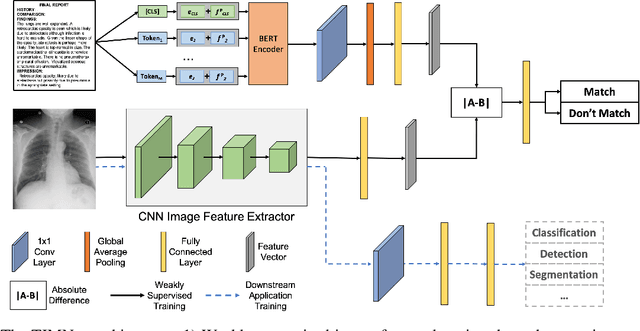
When training deep neural networks for medical image classification, obtaining a sufficient number of manually annotated images is often a significant challenge. We propose to use textual findings, which are routinely written by clinicians during manual image analysis, to help overcome this problem. The key idea is to use a contrastive loss to train image and text feature extractors to recognize if a given image-finding pair is a true match. The learned image feature extractor is then fine-tuned, in a transfer learning setting, for a supervised classification task. This approach makes it possible to train using large datasets because pairs of images and textual findings are widely available in medical records. We evaluate our method on three datasets and find consistent performance improvements. The biggest gains are realized when fewer manually labeled examples are available. In some cases, our method achieves the same performance as the baseline even when using 70\%--98\% fewer labeled examples.
Improved Trainable Calibration Method for Neural Networks on Medical Imaging Classification
Sep 09, 2020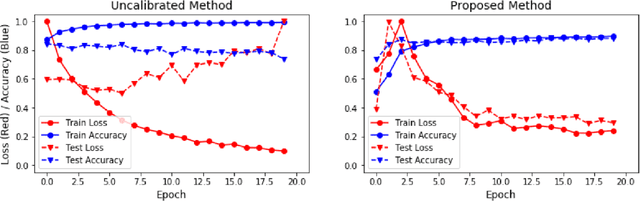
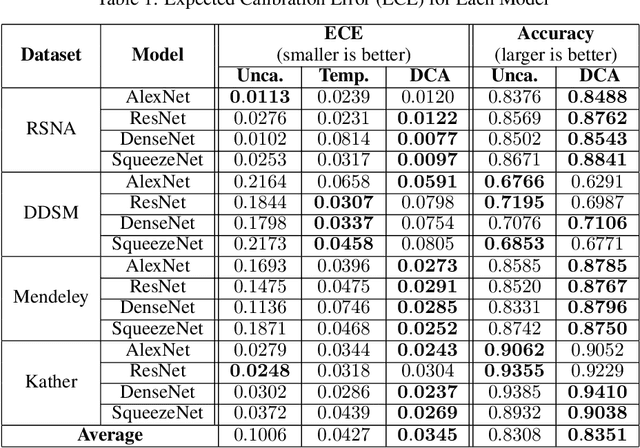
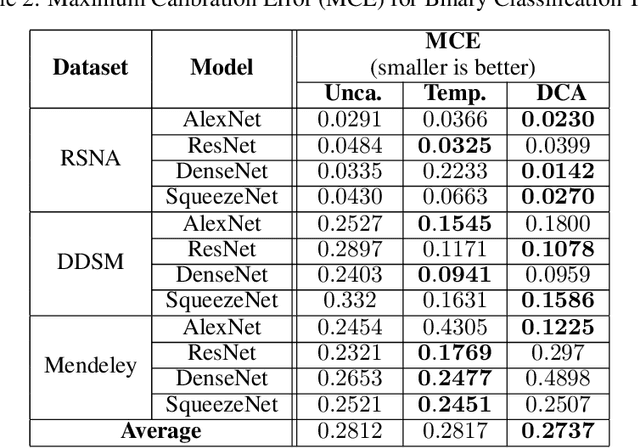
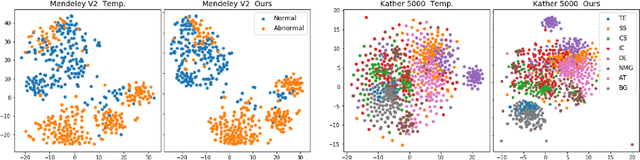
Recent works have shown that deep neural networks can achieve super-human performance in a wide range of image classification tasks in the medical imaging domain. However, these works have primarily focused on classification accuracy, ignoring the important role of uncertainty quantification. Empirically, neural networks are often miscalibrated and overconfident in their predictions. This miscalibration could be problematic in any automatic decision-making system, but we focus on the medical field in which neural network miscalibration has the potential to lead to significant treatment errors. We propose a novel calibration approach that maintains the overall classification accuracy while significantly improving model calibration. The proposed approach is based on expected calibration error, which is a common metric for quantifying miscalibration. Our approach can be easily integrated into any classification task as an auxiliary loss term, thus not requiring an explicit training round for calibration. We show that our approach reduces calibration error significantly across various architectures and datasets.
Unsupervised Domain Adaptation for Mammogram Image Classification: A Promising Tool for Model Generalization
Mar 02, 2020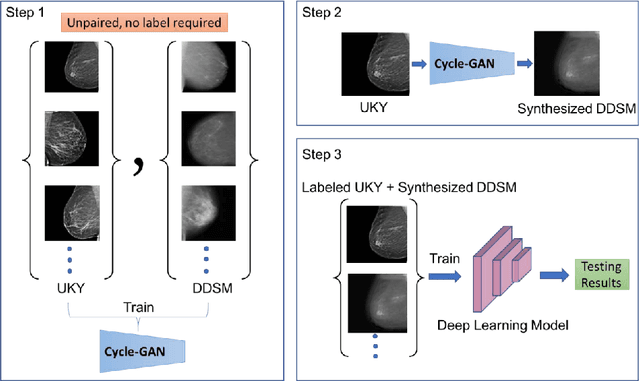
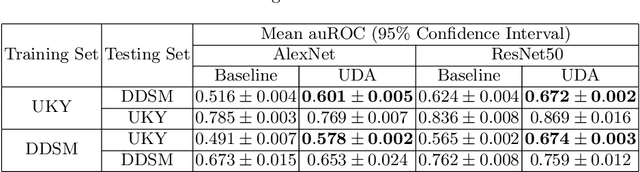
Generalization is one of the key challenges in the clinical validation and application of deep learning models to medical images. Studies have shown that such models trained on publicly available datasets often do not work well on real-world clinical data due to the differences in patient population and image device configurations. Also, manually annotating clinical images is expensive. In this work, we propose an unsupervised domain adaptation (UDA) method using Cycle-GAN to improve the generalization ability of the model without using any additional manual annotations.