 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBCE3S: Binary Cross-Entropy Based Tripartite Synergistic Learning for Long-tailed Recognition
Nov 18, 2025
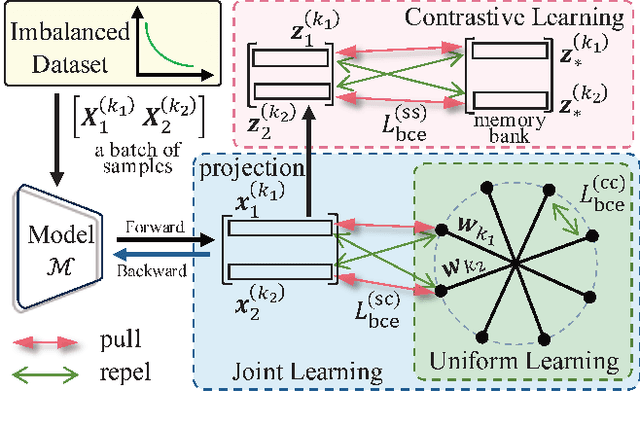


For long-tailed recognition (LTR) tasks, high intra-class compactness and inter-class separability in both head and tail classes, as well as balanced separability among all the classifier vectors, are preferred. The existing LTR methods based on cross-entropy (CE) loss not only struggle to learn features with desirable properties but also couple imbalanced classifier vectors in the denominator of its Softmax, amplifying the imbalance effects in LTR. In this paper, for the LTR, we propose a binary cross-entropy (BCE)-based tripartite synergistic learning, termed BCE3S, which consists of three components: (1) BCE-based joint learning optimizes both the classifier and sample features, which achieves better compactness and separability among features than the CE-based joint learning, by decoupling the metrics between feature and the imbalanced classifier vectors in multiple Sigmoid; (2) BCE-based contrastive learning further improves the intra-class compactness of features; (3) BCE-based uniform learning balances the separability among classifier vectors and interactively enhances the feature properties by combining with the joint learning. The extensive experiments show that the LTR model trained by BCE3S not only achieves higher compactness and separability among sample features, but also balances the classifier's separability, achieving SOTA performance on various long-tailed datasets such as CIFAR10-LT, CIFAR100-LT, ImageNet-LT, and iNaturalist2018.
FaceBench: A Multi-View Multi-Level Facial Attribute VQA Dataset for Benchmarking Face Perception MLLMs
Mar 27, 2025



Multimodal large language models (MLLMs) have demonstrated remarkable capabilities in various tasks. However, effectively evaluating these MLLMs on face perception remains largely unexplored. To address this gap, we introduce FaceBench, a dataset featuring hierarchical multi-view and multi-level attributes specifically designed to assess the comprehensive face perception abilities of MLLMs. Initially, we construct a hierarchical facial attribute structure, which encompasses five views with up to three levels of attributes, totaling over 210 attributes and 700 attribute values. Based on the structure, the proposed FaceBench consists of 49,919 visual question-answering (VQA) pairs for evaluation and 23,841 pairs for fine-tuning. Moreover, we further develop a robust face perception MLLM baseline, Face-LLaVA, by training with our proposed face VQA data. Extensive experiments on various mainstream MLLMs and Face-LLaVA are conducted to test their face perception ability, with results also compared against human performance. The results reveal that, the existing MLLMs are far from satisfactory in understanding the fine-grained facial attributes, while our Face-LLaVA significantly outperforms existing open-source models with a small amount of training data and is comparable to commercial ones like GPT-4o and Gemini. The dataset will be released at https://github.com/CVI-SZU/FaceBench.