 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA data-physics hybrid generative model for patient-specific post-stroke motor rehabilitation using wearable sensor data
Dec 16, 2025Dynamic prediction of locomotor capacity after stroke is crucial for tailoring rehabilitation, yet current assessments provide only static impairment scores and do not indicate whether patients can safely perform specific tasks such as slope walking or stair climbing. Here, we develop a data-physics hybrid generative framework that reconstructs an individual stroke survivor's neuromuscular control from a single 20 m level-ground walking trial and predicts task-conditioned locomotion across rehabilitation scenarios. The system combines wearable-sensor kinematics, a proportional-derivative physics controller, a population Healthy Motion Atlas, and goal-conditioned deep reinforcement learning with behaviour cloning and generative adversarial imitation learning to generate physically plausible, patient-specific gait simulations for slopes and stairs. In 11 stroke survivors, the personalized controllers preserved idiosyncratic gait patterns while improving joint-angle and endpoint fidelity by 4.73% and 12.10%, respectively, and reducing training time to 25.56% relative to a physics-only baseline. In a multicentre pilot involving 21 inpatients, clinicians who used our locomotion predictions to guide task selection and difficulty obtained larger gains in Fugl-Meyer lower-extremity scores over 28 days of standard rehabilitation than control clinicians (mean change 6.0 versus 3.7 points). These findings indicate that our generative, task-predictive framework can augment clinical decision-making in post-stroke gait rehabilitation and provide a template for dynamically personalized motor recovery strategies.
FaceBench: A Multi-View Multi-Level Facial Attribute VQA Dataset for Benchmarking Face Perception MLLMs
Mar 27, 2025



Multimodal large language models (MLLMs) have demonstrated remarkable capabilities in various tasks. However, effectively evaluating these MLLMs on face perception remains largely unexplored. To address this gap, we introduce FaceBench, a dataset featuring hierarchical multi-view and multi-level attributes specifically designed to assess the comprehensive face perception abilities of MLLMs. Initially, we construct a hierarchical facial attribute structure, which encompasses five views with up to three levels of attributes, totaling over 210 attributes and 700 attribute values. Based on the structure, the proposed FaceBench consists of 49,919 visual question-answering (VQA) pairs for evaluation and 23,841 pairs for fine-tuning. Moreover, we further develop a robust face perception MLLM baseline, Face-LLaVA, by training with our proposed face VQA data. Extensive experiments on various mainstream MLLMs and Face-LLaVA are conducted to test their face perception ability, with results also compared against human performance. The results reveal that, the existing MLLMs are far from satisfactory in understanding the fine-grained facial attributes, while our Face-LLaVA significantly outperforms existing open-source models with a small amount of training data and is comparable to commercial ones like GPT-4o and Gemini. The dataset will be released at https://github.com/CVI-SZU/FaceBench.
OccProphet: Pushing Efficiency Frontier of Camera-Only 4D Occupancy Forecasting with Observer-Forecaster-Refiner Framework
Feb 21, 2025



Predicting variations in complex traffic environments is crucial for the safety of autonomous driving. Recent advancements in occupancy forecasting have enabled forecasting future 3D occupied status in driving environments by observing historical 2D images. However, high computational demands make occupancy forecasting less efficient during training and inference stages, hindering its feasibility for deployment on edge agents. In this paper, we propose a novel framework, i.e., OccProphet, to efficiently and effectively learn occupancy forecasting with significantly lower computational requirements while improving forecasting accuracy. OccProphet comprises three lightweight components: Observer, Forecaster, and Refiner. The Observer extracts spatio-temporal features from 3D multi-frame voxels using the proposed Efficient 4D Aggregation with Tripling-Attention Fusion, while the Forecaster and Refiner conditionally predict and refine future occupancy inferences. Experimental results on nuScenes, Lyft-Level5, and nuScenes-Occupancy datasets demonstrate that OccProphet is both training- and inference-friendly. OccProphet reduces 58\%$\sim$78\% of the computational cost with a 2.6$\times$ speedup compared with the state-of-the-art Cam4DOcc. Moreover, it achieves 4\%$\sim$18\% relatively higher forecasting accuracy. Code and models are publicly available at https://github.com/JLChen-C/OccProphet.
A Unified Platform for At-Home Post-Stroke Rehabilitation Enabled by Wearable Technologies and Artificial Intelligence
Nov 28, 2024



At-home rehabilitation for post-stroke patients presents significant challenges, as continuous, personalized care is often limited outside clinical settings. Additionally, the absence of comprehensive solutions addressing diverse rehabilitation needs in home environments complicates recovery efforts. Here, we introduce a smart home platform that integrates wearable sensors, ambient monitoring, and large language model (LLM)-powered assistance to provide seamless health monitoring and intelligent support. The system leverages machine learning enabled plantar pressure arrays for motor recovery assessment (94% classification accuracy), a wearable eye-tracking module for cognitive evaluation, and ambient sensors for precise smart home control (100% operational success, <1 s latency). Additionally, the LLM-powered agent, Auto-Care, offers real-time interventions, such as health reminders and environmental adjustments, enhancing user satisfaction by 29%. This work establishes a fully integrated platform for long-term, personalized rehabilitation, offering new possibilities for managing chronic conditions and supporting aging populations.
A Survey on Occupancy Perception for Autonomous Driving: The Information Fusion Perspective
May 08, 2024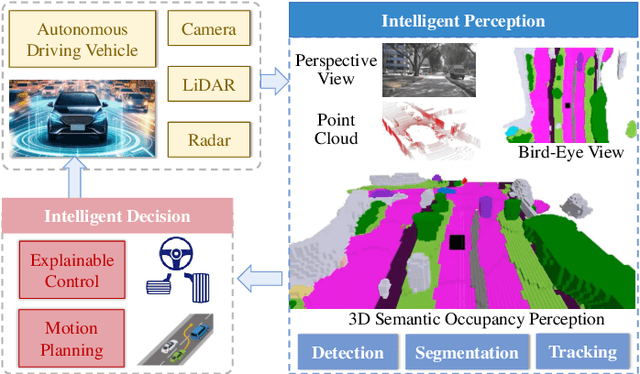



3D occupancy perception technology aims to observe and understand dense 3D environments for autonomous vehicles. Owing to its comprehensive perception capability, this technology is emerging as a trend in autonomous driving perception systems, and is attracting significant attention from both industry and academia. Similar to traditional bird's-eye view (BEV) perception, 3D occupancy perception has the nature of multi-source input and the necessity for information fusion. However, the difference is that it captures vertical structures that are ignored by 2D BEV. In this survey, we review the most recent works on 3D occupancy perception, and provide in-depth analyses of methodologies with various input modalities. Specifically, we summarize general network pipelines, highlight information fusion techniques, and discuss effective network training. We evaluate and analyze the occupancy perception performance of the state-of-the-art on the most popular datasets. Furthermore, challenges and future research directions are discussed. We hope this report will inspire the community and encourage more research work on 3D occupancy perception. A comprehensive list of studies in this survey is available in an active repository that continuously collects the latest work: https://github.com/HuaiyuanXu/3D-Occupancy-Perception.
SemFormer: Semantic Guided Activation Transformer for Weakly Supervised Semantic Segmentation
Oct 26, 2022



Recent mainstream weakly supervised semantic segmentation (WSSS) approaches are mainly based on Class Activation Map (CAM) generated by a CNN (Convolutional Neural Network) based image classifier. In this paper, we propose a novel transformer-based framework, named Semantic Guided Activation Transformer (SemFormer), for WSSS. We design a transformer-based Class-Aware AutoEncoder (CAAE) to extract the class embeddings for the input image and learn class semantics for all classes of the dataset. The class embeddings and learned class semantics are then used to guide the generation of activation maps with four losses, i.e., class-foreground, class-background, activation suppression, and activation complementation loss. Experimental results show that our SemFormer achieves \textbf{74.3}\% mIoU and surpasses many recent mainstream WSSS approaches by a large margin on PASCAL VOC 2012 dataset. Code will be available at \url{https://github.com/JLChen-C/SemFormer}.
Sample hardness based gradient loss for long-tailed cervical cell detection
Aug 07, 2022
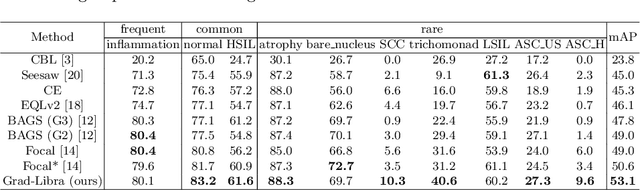
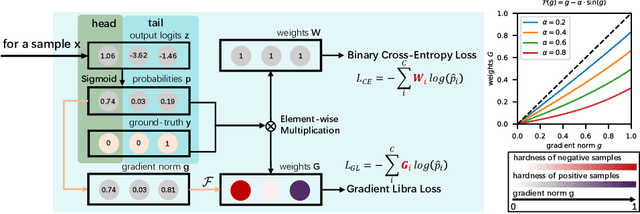
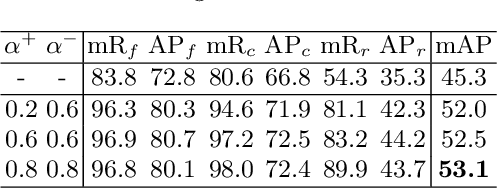
Due to the difficulty of cancer samples collection and annotation, cervical cancer datasets usually exhibit a long-tailed data distribution. When training a detector to detect the cancer cells in a WSI (Whole Slice Image) image captured from the TCT (Thinprep Cytology Test) specimen, head categories (e.g. normal cells and inflammatory cells) typically have a much larger number of samples than tail categories (e.g. cancer cells). Most existing state-of-the-art long-tailed learning methods in object detection focus on category distribution statistics to solve the problem in the long-tailed scenario without considering the "hardness" of each sample. To address this problem, in this work we propose a Grad-Libra Loss that leverages the gradients to dynamically calibrate the degree of hardness of each sample for different categories, and re-balance the gradients of positive and negative samples. Our loss can thus help the detector to put more emphasis on those hard samples in both head and tail categories. Extensive experiments on a long-tailed TCT WSI image dataset show that the mainstream detectors, e.g. RepPoints, FCOS, ATSS, YOLOF, etc. trained using our proposed Gradient-Libra Loss, achieved much higher (7.8%) mAP than that trained using cross-entropy classification loss.
Delving into the Scale Variance Problem in Object Detection
Jun 16, 2022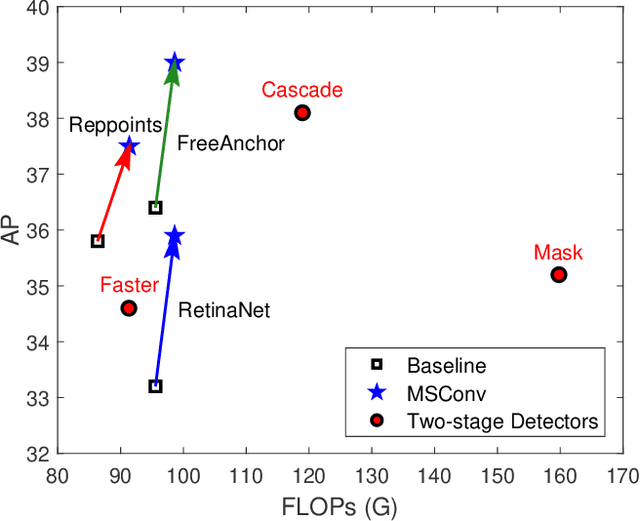
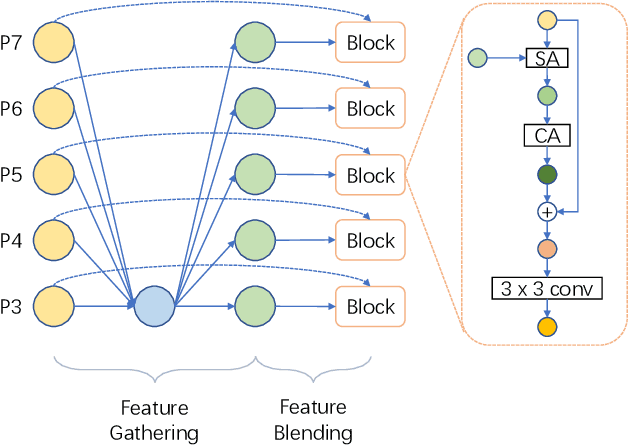
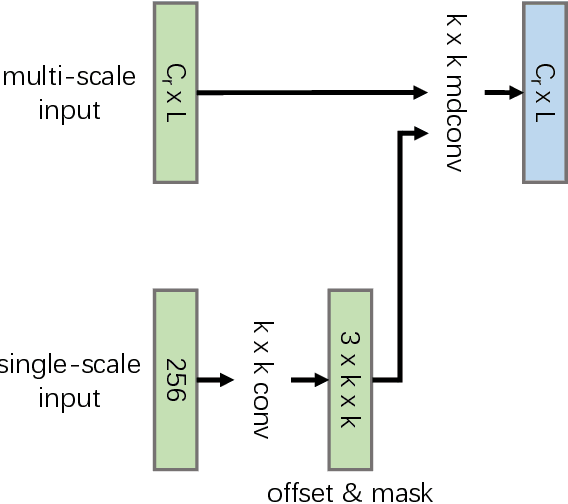
Object detection has made substantial progress in the last decade, due to the capability of convolution in extracting local context of objects. However, the scales of objects are diverse and current convolution can only process single-scale input. The capability of traditional convolution with a fixed receptive field in dealing with such a scale variance problem, is thus limited. Multi-scale feature representation has been proven to be an effective way to mitigate the scale variance problem. Recent researches mainly adopt partial connection with certain scales, or aggregate features from all scales and focus on the global information across the scales. However, the information across spatial and depth dimensions is ignored. Inspired by this, we propose the multi-scale convolution (MSConv) to handle this problem. Taking into consideration scale, spatial and depth information at the same time, MSConv is able to process multi-scale input more comprehensively. MSConv is effective and computationally efficient, with only a small increase of computational cost. For most of the single-stage object detectors, replacing the traditional convolutions with MSConvs in the detection head can bring more than 2.5\% improvement in AP (on COCO 2017 dataset), with only 3\% increase of FLOPs. MSConv is also flexible and effective for two-stage object detectors. When extended to the mainstream two-stage object detectors, MSConv can bring up to 3.0\% improvement in AP. Our best model under single-scale testing achieves 48.9\% AP on COCO 2017 \textit{test-dev} split, which surpasses many state-of-the-art methods.
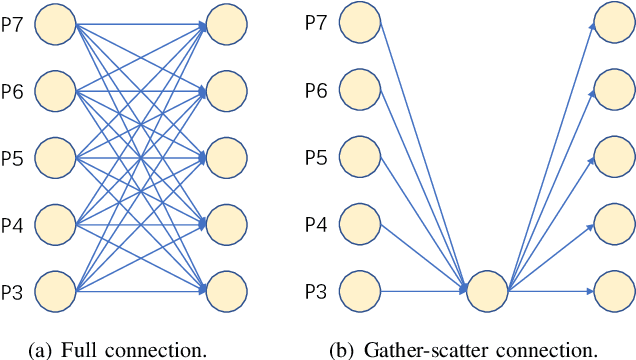
Selective Multi-Scale Learning for Object Detection
Jun 16, 2022Pyramidal networks are standard methods for multi-scale object detection. Current researches on feature pyramid networks usually adopt layer connections to collect features from certain levels of the feature hierarchy, and do not consider the significant differences among them. We propose a better architecture of feature pyramid networks, named selective multi-scale learning (SMSL), to address this issue. SMSL is efficient and general, which can be integrated in both single-stage and two-stage detectors to boost detection performance, with nearly no extra inference cost. RetinaNet combined with SMSL obtains 1.8\% improvement in AP (from 39.1\% to 40.9\%) on COCO dataset. When integrated with SMSL, two-stage detectors can get around 1.0\% improvement in AP.
Contrastive learning of Class-agnostic Activation Map for Weakly Supervised Object Localization and Semantic Segmentation
Mar 25, 2022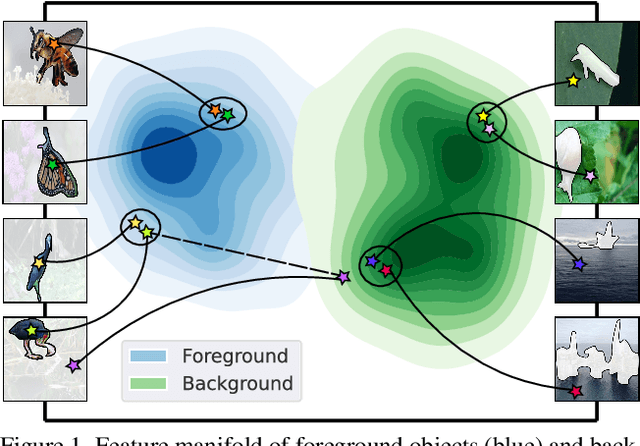
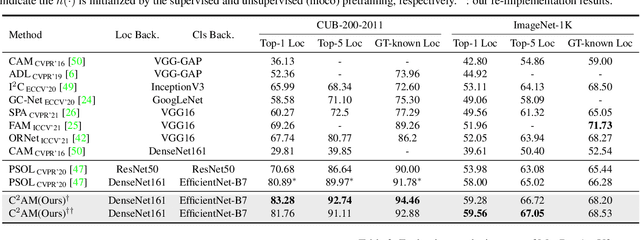
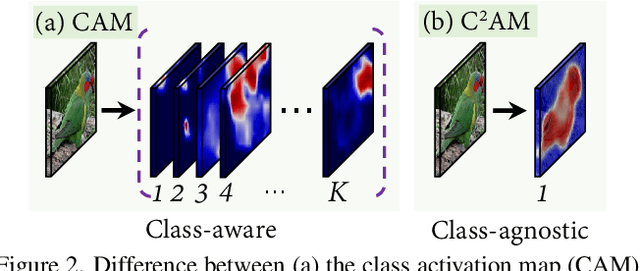
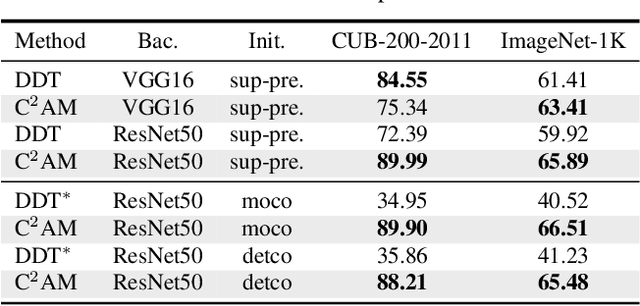
While class activation map (CAM) generated by image classification network has been widely used for weakly supervised object localization (WSOL) and semantic segmentation (WSSS), such classifiers usually focus on discriminative object regions. In this paper, we propose Contrastive learning for Class-agnostic Activation Map (C$^2$AM) generation only using unlabeled image data, without the involvement of image-level supervision. The core idea comes from the observation that i) semantic information of foreground objects usually differs from their backgrounds; ii) foreground objects with similar appearance or background with similar color/texture have similar representations in the feature space. We form the positive and negative pairs based on the above relations and force the network to disentangle foreground and background with a class-agnostic activation map using a novel contrastive loss. As the network is guided to discriminate cross-image foreground-background, the class-agnostic activation maps learned by our approach generate more complete object regions. We successfully extracted from C$^2$AM class-agnostic object bounding boxes for object localization and background cues to refine CAM generated by classification network for semantic segmentation. Extensive experiments on CUB-200-2011, ImageNet-1K, and PASCAL VOC2012 datasets show that both WSOL and WSSS can benefit from the proposed C$^2$AM.