 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelving into the Scale Variance Problem in Object Detection
Paper and Code
Jun 16, 2022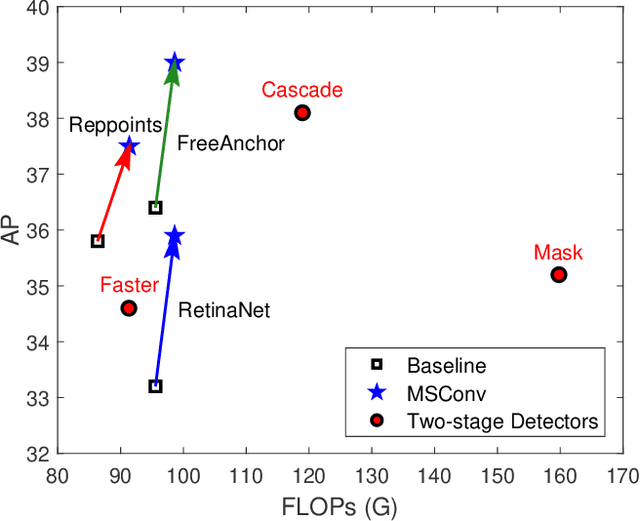
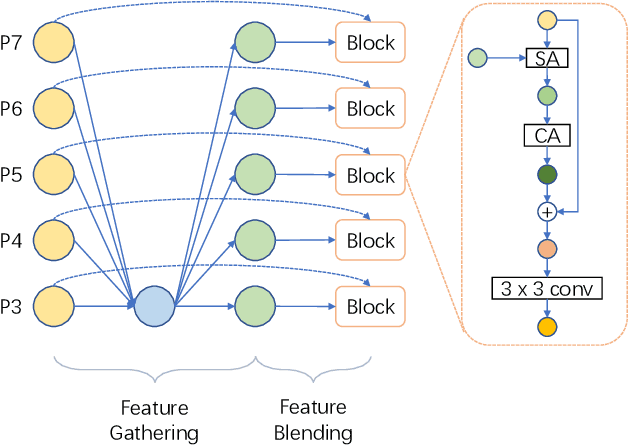
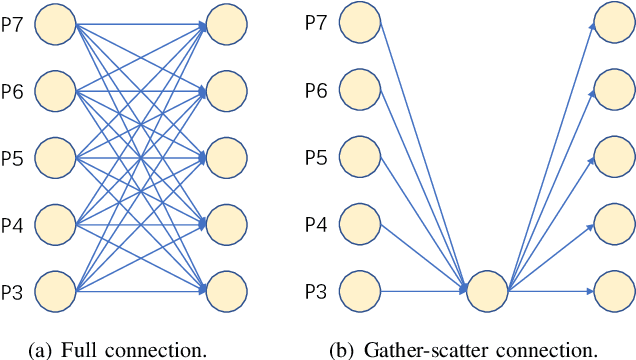
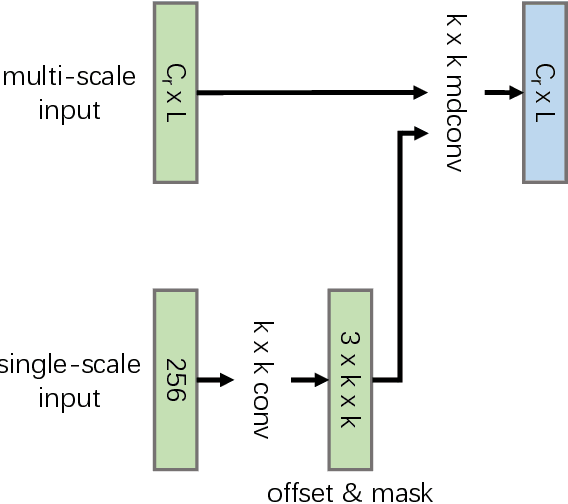
Object detection has made substantial progress in the last decade, due to the capability of convolution in extracting local context of objects. However, the scales of objects are diverse and current convolution can only process single-scale input. The capability of traditional convolution with a fixed receptive field in dealing with such a scale variance problem, is thus limited. Multi-scale feature representation has been proven to be an effective way to mitigate the scale variance problem. Recent researches mainly adopt partial connection with certain scales, or aggregate features from all scales and focus on the global information across the scales. However, the information across spatial and depth dimensions is ignored. Inspired by this, we propose the multi-scale convolution (MSConv) to handle this problem. Taking into consideration scale, spatial and depth information at the same time, MSConv is able to process multi-scale input more comprehensively. MSConv is effective and computationally efficient, with only a small increase of computational cost. For most of the single-stage object detectors, replacing the traditional convolutions with MSConvs in the detection head can bring more than 2.5\% improvement in AP (on COCO 2017 dataset), with only 3\% increase of FLOPs. MSConv is also flexible and effective for two-stage object detectors. When extended to the mainstream two-stage object detectors, MSConv can bring up to 3.0\% improvement in AP. Our best model under single-scale testing achieves 48.9\% AP on COCO 2017 \textit{test-dev} split, which surpasses many state-of-the-art methods.