 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocialMOIF: Multi-Order Intention Fusion for Pedestrian Trajectory Prediction
Apr 22, 2025The analysis and prediction of agent trajectories are crucial for decision-making processes in intelligent systems, with precise short-term trajectory forecasting being highly significant across a range of applications. Agents and their social interactions have been quantified and modeled by researchers from various perspectives; however, substantial limitations exist in the current work due to the inherent high uncertainty of agent intentions and the complex higher-order influences among neighboring groups. SocialMOIF is proposed to tackle these challenges, concentrating on the higher-order intention interactions among neighboring groups while reinforcing the primary role of first-order intention interactions between neighbors and the target agent. This method develops a multi-order intention fusion model to achieve a more comprehensive understanding of both direct and indirect intention information. Within SocialMOIF, a trajectory distribution approximator is designed to guide the trajectories toward values that align more closely with the actual data, thereby enhancing model interpretability. Furthermore, a global trajectory optimizer is introduced to enable more accurate and efficient parallel predictions. By incorporating a novel loss function that accounts for distance and direction during training, experimental results demonstrate that the model outperforms previous state-of-the-art baselines across multiple metrics in both dynamic and static datasets.
Accurate and Data-Efficient Micro-XRD Phase Identification Using Multi-Task Learning: Application to Hydrothermal Fluids
Mar 15, 2024



Traditional analysis of highly distorted micro-X-ray diffraction ({\mu}-XRD) patterns from hydrothermal fluid environments is a time-consuming process, often requiring substantial data preprocessing and labeled experimental data. This study demonstrates the potential of deep learning with a multitask learning (MTL) architecture to overcome these limitations. We trained MTL models to identify phase information in {\mu}-XRD patterns, minimizing the need for labeled experimental data and masking preprocessing steps. Notably, MTL models showed superior accuracy compared to binary classification CNNs. Additionally, introducing a tailored cross-entropy loss function improved MTL model performance. Most significantly, MTL models tuned to analyze raw and unmasked XRD patterns achieved close performance to models analyzing preprocessed data, with minimal accuracy differences. This work indicates that advanced deep learning architectures like MTL can automate arduous data handling tasks, streamline the analysis of distorted XRD patterns, and reduce the reliance on labor-intensive experimental datasets.
Machine Learning Automated Approach for Enormous Synchrotron X-Ray Diffraction Data Interpretation
Mar 20, 2023Manual analysis of XRD data is usually laborious and time consuming. The deep neural network (DNN) based models trained by synthetic XRD patterns are proved to be an automatic, accurate, and high throughput method to analysis common XRD data collected from solid sample in ambient environment. However, it remains unknown that whether synthetic XRD based models are capable to solve u-XRD mapping data for in-situ experiments involving liquid phase exhibiting lower quality with significant artifacts. In this study, we collected u-XRD mapping data from an LaCl3-calcite hydrothermal fluid system and trained two categories of models to solve the experimental XRD patterns. The models trained by synthetic XRD patterns show low accuracy (as low as 64%) when solving experimental u-XRD mapping data. The accuracy of the DNN models was significantly improved (90% or above) when training them with the dataset containing both synthetic and small number of labeled experimental u-XRD patterns. This study highlighted the importance of labeled experimental patterns on the training of DNN models to solve u-XRD mapping data from in-situ experiments involving liquid phase.
SemFormer: Semantic Guided Activation Transformer for Weakly Supervised Semantic Segmentation
Oct 26, 2022



Recent mainstream weakly supervised semantic segmentation (WSSS) approaches are mainly based on Class Activation Map (CAM) generated by a CNN (Convolutional Neural Network) based image classifier. In this paper, we propose a novel transformer-based framework, named Semantic Guided Activation Transformer (SemFormer), for WSSS. We design a transformer-based Class-Aware AutoEncoder (CAAE) to extract the class embeddings for the input image and learn class semantics for all classes of the dataset. The class embeddings and learned class semantics are then used to guide the generation of activation maps with four losses, i.e., class-foreground, class-background, activation suppression, and activation complementation loss. Experimental results show that our SemFormer achieves \textbf{74.3}\% mIoU and surpasses many recent mainstream WSSS approaches by a large margin on PASCAL VOC 2012 dataset. Code will be available at \url{https://github.com/JLChen-C/SemFormer}.
Delving into the Scale Variance Problem in Object Detection
Jun 16, 2022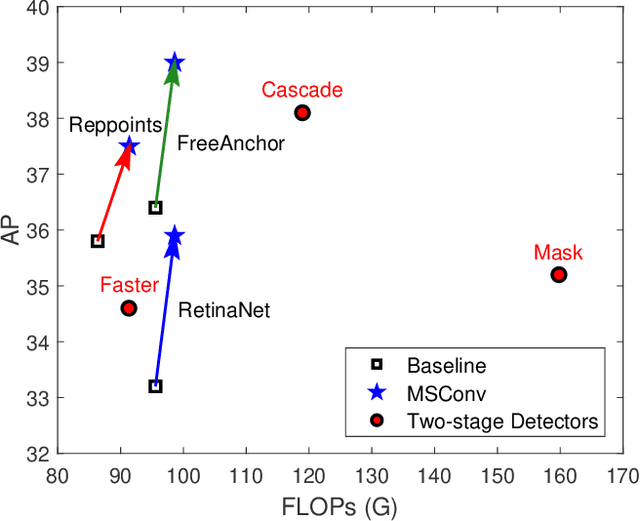
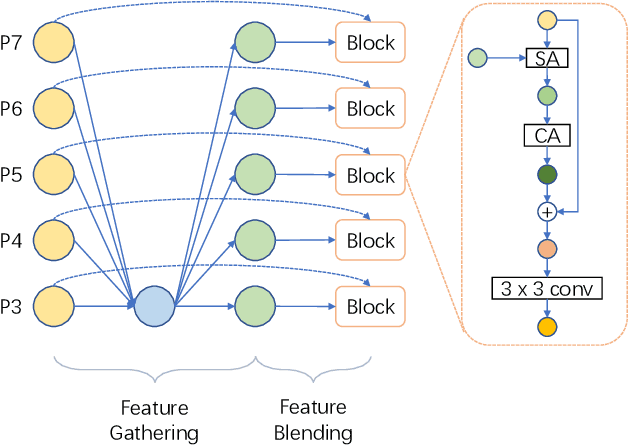
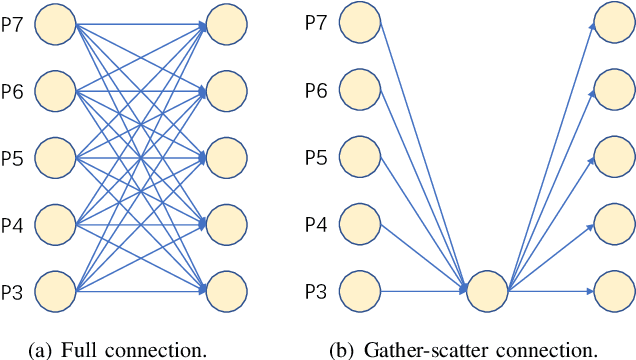
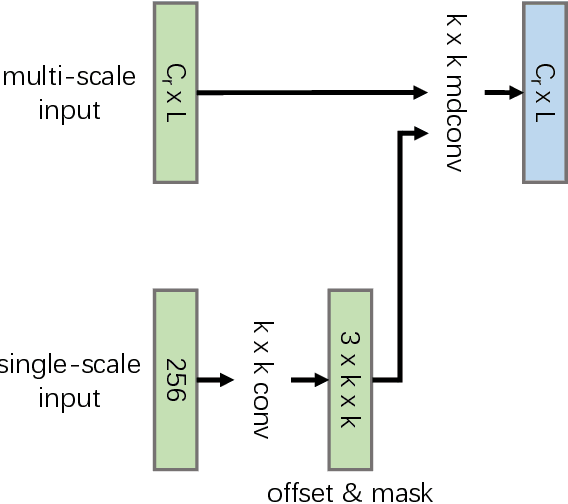
Object detection has made substantial progress in the last decade, due to the capability of convolution in extracting local context of objects. However, the scales of objects are diverse and current convolution can only process single-scale input. The capability of traditional convolution with a fixed receptive field in dealing with such a scale variance problem, is thus limited. Multi-scale feature representation has been proven to be an effective way to mitigate the scale variance problem. Recent researches mainly adopt partial connection with certain scales, or aggregate features from all scales and focus on the global information across the scales. However, the information across spatial and depth dimensions is ignored. Inspired by this, we propose the multi-scale convolution (MSConv) to handle this problem. Taking into consideration scale, spatial and depth information at the same time, MSConv is able to process multi-scale input more comprehensively. MSConv is effective and computationally efficient, with only a small increase of computational cost. For most of the single-stage object detectors, replacing the traditional convolutions with MSConvs in the detection head can bring more than 2.5\% improvement in AP (on COCO 2017 dataset), with only 3\% increase of FLOPs. MSConv is also flexible and effective for two-stage object detectors. When extended to the mainstream two-stage object detectors, MSConv can bring up to 3.0\% improvement in AP. Our best model under single-scale testing achieves 48.9\% AP on COCO 2017 \textit{test-dev} split, which surpasses many state-of-the-art methods.
Contrastive learning of Class-agnostic Activation Map for Weakly Supervised Object Localization and Semantic Segmentation
Mar 25, 2022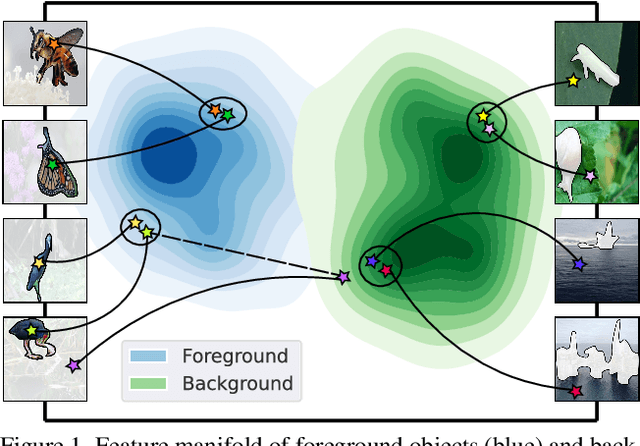
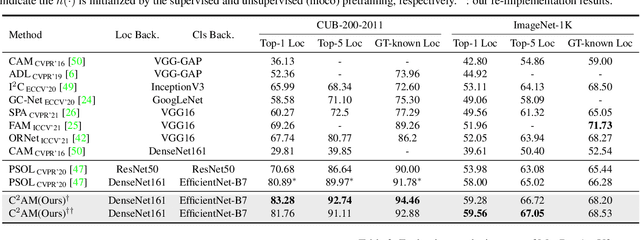
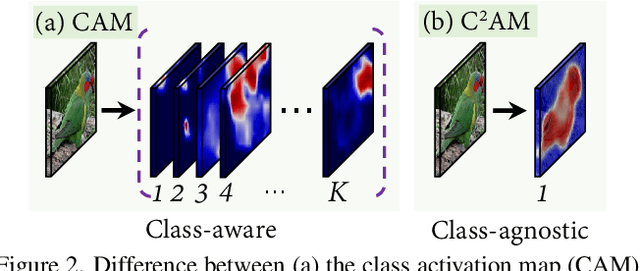
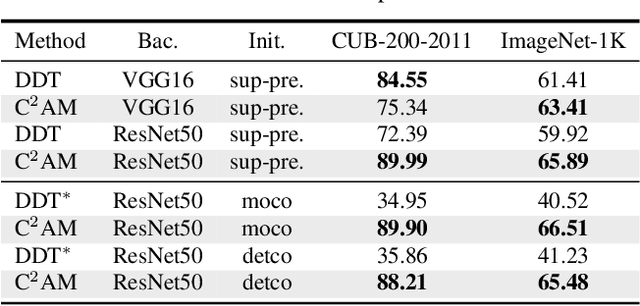
While class activation map (CAM) generated by image classification network has been widely used for weakly supervised object localization (WSOL) and semantic segmentation (WSSS), such classifiers usually focus on discriminative object regions. In this paper, we propose Contrastive learning for Class-agnostic Activation Map (C$^2$AM) generation only using unlabeled image data, without the involvement of image-level supervision. The core idea comes from the observation that i) semantic information of foreground objects usually differs from their backgrounds; ii) foreground objects with similar appearance or background with similar color/texture have similar representations in the feature space. We form the positive and negative pairs based on the above relations and force the network to disentangle foreground and background with a class-agnostic activation map using a novel contrastive loss. As the network is guided to discriminate cross-image foreground-background, the class-agnostic activation maps learned by our approach generate more complete object regions. We successfully extracted from C$^2$AM class-agnostic object bounding boxes for object localization and background cues to refine CAM generated by classification network for semantic segmentation. Extensive experiments on CUB-200-2011, ImageNet-1K, and PASCAL VOC2012 datasets show that both WSOL and WSSS can benefit from the proposed C$^2$AM.