 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample hardness based gradient loss for long-tailed cervical cell detection
Paper and Code

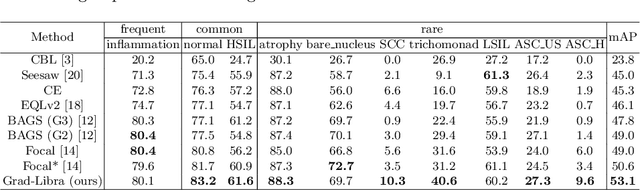
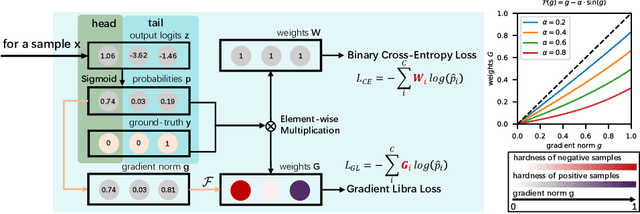
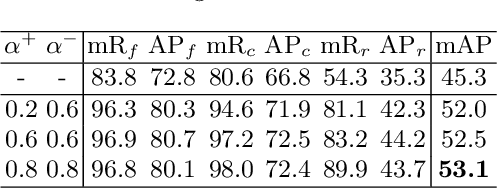
Due to the difficulty of cancer samples collection and annotation, cervical cancer datasets usually exhibit a long-tailed data distribution. When training a detector to detect the cancer cells in a WSI (Whole Slice Image) image captured from the TCT (Thinprep Cytology Test) specimen, head categories (e.g. normal cells and inflammatory cells) typically have a much larger number of samples than tail categories (e.g. cancer cells). Most existing state-of-the-art long-tailed learning methods in object detection focus on category distribution statistics to solve the problem in the long-tailed scenario without considering the "hardness" of each sample. To address this problem, in this work we propose a Grad-Libra Loss that leverages the gradients to dynamically calibrate the degree of hardness of each sample for different categories, and re-balance the gradients of positive and negative samples. Our loss can thus help the detector to put more emphasis on those hard samples in both head and tail categories. Extensive experiments on a long-tailed TCT WSI image dataset show that the mainstream detectors, e.g. RepPoints, FCOS, ATSS, YOLOF, etc. trained using our proposed Gradient-Libra Loss, achieved much higher (7.8%) mAP than that trained using cross-entropy classification loss.