 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOSA: Echocardiography Video Segmentation via Orthogonalized State Update and Anatomical Prior-aware Feature Enhancement
Mar 27, 2026Accurate and temporally consistent segmentation of the left ventricle from echocardiography videos is essential for estimating the ejection fraction and assessing cardiac function. However, modeling spatiotemporal dynamics remains difficult due to severe speckle noise and rapid non-rigid deformations. Existing linear recurrent models offer efficient in-context associative recall for temporal tracking, but rely on unconstrained state updates, which cause progressive singular value decay in the state matrix, a phenomenon known as rank collapse, resulting in anatomical details being overwhelmed by noise. To address this, we propose OSA, a framework that constrains the state evolution on the Stiefel manifold. We introduce the Orthogonalized State Update (OSU) mechanism, which formulates the memory evolution as Euclidean projected gradient descent on the Stiefel manifold to prevent rank collapse and maintain stable temporal transitions. Furthermore, an Anatomical Prior-aware Feature Enhancement module explicitly separates anatomical structures from speckle noise through a physics-driven process, providing the temporal tracker with noise-resilient structural cues. Comprehensive experiments on the CAMUS and EchoNet-Dynamic datasets show that OSA achieves state-of-the-art segmentation accuracy and temporal stability, while maintaining real-time inference efficiency for clinical deployment. Codes are available at https://github.com/wangrui2025/OSA.
GDKVM: Echocardiography Video Segmentation via Spatiotemporal Key-Value Memory with Gated Delta Rule
Dec 11, 2025



Accurate segmentation of cardiac chambers in echocardiography sequences is crucial for the quantitative analysis of cardiac function, aiding in clinical diagnosis and treatment. The imaging noise, artifacts, and the deformation and motion of the heart pose challenges to segmentation algorithms. While existing methods based on convolutional neural networks, Transformers, and space-time memory networks have improved segmentation accuracy, they often struggle with the trade-off between capturing long-range spatiotemporal dependencies and maintaining computational efficiency with fine-grained feature representation. In this paper, we introduce GDKVM, a novel architecture for echocardiography video segmentation. The model employs Linear Key-Value Association (LKVA) to effectively model inter-frame correlations, and introduces Gated Delta Rule (GDR) to efficiently store intermediate memory states. Key-Pixel Feature Fusion (KPFF) module is designed to integrate local and global features at multiple scales, enhancing robustness against boundary blurring and noise interference. We validated GDKVM on two mainstream echocardiography video datasets (CAMUS and EchoNet-Dynamic) and compared it with various state-of-the-art methods. Experimental results show that GDKVM outperforms existing approaches in terms of segmentation accuracy and robustness, while ensuring real-time performance. Code is available at https://github.com/wangrui2025/GDKVM.
Benchmarking the Robustness of Temporal Action Detection Models Against Temporal Corruptions
Mar 29, 2024Temporal action detection (TAD) aims to locate action positions and recognize action categories in long-term untrimmed videos. Although many methods have achieved promising results, their robustness has not been thoroughly studied. In practice, we observe that temporal information in videos can be occasionally corrupted, such as missing or blurred frames. Interestingly, existing methods often incur a significant performance drop even if only one frame is affected. To formally evaluate the robustness, we establish two temporal corruption robustness benchmarks, namely THUMOS14-C and ActivityNet-v1.3-C. In this paper, we extensively analyze the robustness of seven leading TAD methods and obtain some interesting findings: 1) Existing methods are particularly vulnerable to temporal corruptions, and end-to-end methods are often more susceptible than those with a pre-trained feature extractor; 2) Vulnerability mainly comes from localization error rather than classification error; 3) When corruptions occur in the middle of an action instance, TAD models tend to yield the largest performance drop. Besides building a benchmark, we further develop a simple but effective robust training method to defend against temporal corruptions, through the FrameDrop augmentation and Temporal-Robust Consistency loss. Remarkably, our approach not only improves robustness but also yields promising improvements on clean data. We believe that this study will serve as a benchmark for future research in robust video analysis. Source code and models are available at https://github.com/Alvin-Zeng/temporal-robustness-benchmark.
Sample hardness based gradient loss for long-tailed cervical cell detection
Aug 07, 2022
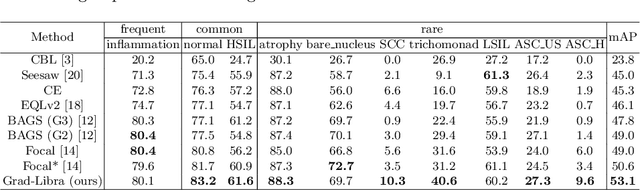
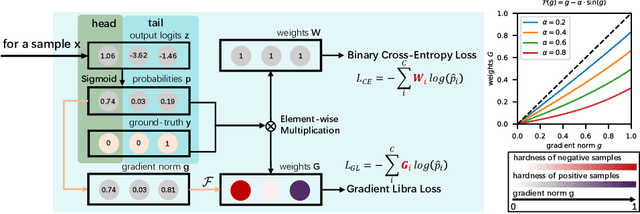
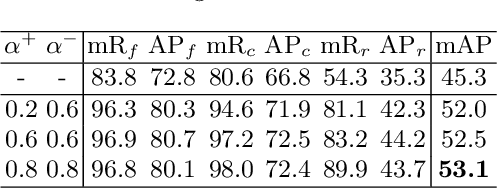
Due to the difficulty of cancer samples collection and annotation, cervical cancer datasets usually exhibit a long-tailed data distribution. When training a detector to detect the cancer cells in a WSI (Whole Slice Image) image captured from the TCT (Thinprep Cytology Test) specimen, head categories (e.g. normal cells and inflammatory cells) typically have a much larger number of samples than tail categories (e.g. cancer cells). Most existing state-of-the-art long-tailed learning methods in object detection focus on category distribution statistics to solve the problem in the long-tailed scenario without considering the "hardness" of each sample. To address this problem, in this work we propose a Grad-Libra Loss that leverages the gradients to dynamically calibrate the degree of hardness of each sample for different categories, and re-balance the gradients of positive and negative samples. Our loss can thus help the detector to put more emphasis on those hard samples in both head and tail categories. Extensive experiments on a long-tailed TCT WSI image dataset show that the mainstream detectors, e.g. RepPoints, FCOS, ATSS, YOLOF, etc. trained using our proposed Gradient-Libra Loss, achieved much higher (7.8%) mAP than that trained using cross-entropy classification loss.