 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorridorVLA: Explicit Spatial Constraints for Generative Action Heads via Sparse Anchors
Apr 23, 2026Vision--Language--Action (VLA) models often use intermediate representations to connect multimodal inputs with continuous control, yet spatial guidance is often injected implicitly through latent features. We propose $CorridorVLA$, which predicts sparse spatial anchors as incremental physical changes (e.g., $Δ$-positions) and uses them to impose an explicit tolerance region in the training objective for action generation. The anchors define a corridor that guides a flow-matching action head: trajectories whose implied spatial evolution falls outside it receive corrective gradients, while minor deviations from contacts and execution noise are permitted. On the more challenging LIBERO-Plus benchmark, CorridorVLA yields consistent gains across both SmolVLA and GR00T, improving success rate by $3.4\%$--$12.4\%$ over the corresponding baselines; notably, our GR00T-Corr variant reaches a success rate of $83.21\%$. These results indicate that action-aligned physical cues can provide direct and interpretable constraints for generative action policies, complementing spatial guidance encoded in visual or latent forms. Code is available at https://github.com/corridorVLA.
PhyMix: Towards Physically Consistent Single-Image 3D Indoor Scene Generation with Implicit--Explicit Optimization
Apr 11, 2026Existing single-image 3D indoor scene generators often produce results that look visually plausible but fail to obey real-world physics, limiting their reliability in robotics, embodied AI, and design. To examine this gap, we introduce a unified Physics Evaluator that measures four main aspects: geometric priors, contact, stability, and deployability, which are further decomposed into nine sub-constraints, establishing the first benchmark to measure physical consistency. Based on this evaluator, our analysis shows that state-of-the-art methods remain largely physics-unaware. To overcome this limitation, we further propose a framework that integrates feedback from the Physics Evaluator into both training and inference, enhancing the physical plausibility of generated scenes. Specifically, we propose PhyMix, which is composed of two complementary components: (i) implicit alignment via Scene-GRPO, a critic-free group-relative policy optimization that leverages the Physics Evaluator as a preference signal and biases sampling towards physically feasible layouts, and (ii) explicit refinement via a plug-and-play Test-Time Optimizer (TTO) that uses differentiable evaluator signals to correct residual violations during generation. Overall, our method unifies evaluation, reward shaping, and inference-time correction, producing 3D indoor scenes that are visually faithful and physically plausible. Extensive synthetic evaluations confirm state-of-the-art performance in both visual fidelity and physical plausibility, and extensive qualitative examples in stylized and real-world images further showcase the robustness of the method. We will release codes and models upon publication.
Learning Task-Invariant Properties via Dreamer: Enabling Efficient Policy Transfer for Quadruped Robots
Apr 03, 2026Achieving quadruped robot locomotion across diverse and dynamic terrains presents significant challenges, primarily due to the discrepancies between simulation environments and real-world conditions. Traditional sim-to-real transfer methods often rely on manual feature design or costly real-world fine-tuning. To address these limitations, this paper proposes the DreamTIP framework, which incorporates Task-Invariant Properties learning within the Dreamer world model architecture to enhance sim-to-real transfer capabilities. Guided by large language models, DreamTIP identifies and leverages Task-Invariant Properties, such as contact stability and terrain clearance, which exhibit robustness to dynamic variations and strong transferability across tasks. These properties are integrated into the world model as auxiliary prediction targets, enabling the policy to learn representations that are insensitive to underlying dynamic changes. Furthermore, an efficient adaptation strategy is designed, employing a mixed replay buffer and regularization constraints to rapidly calibrate to real-world dynamics while effectively mitigating representation collapse and catastrophic forgetting. Extensive experiments on complex terrains, including Stair, Climb, Tilt, and Crawl, demonstrate that DreamTIP significantly outperforms state-of-the-art baselines in both simulated and real-world environments. Our method achieves an average performance improvement of 28.1% across eight distinct simulated transfer tasks. In the real-world Climb task, the baseline method achieved only a 10\ success rate, whereas our method attained a 100% success rate. These results indicate that incorporating Task-Invariant Properties into Dreamer learning offers a novel solution for achieving robust and transferable robot locomotion.
Exploiting Low-Rank Structure in Max-K-Cut Problems
Feb 23, 2026We approach the Max-3-Cut problem through the lens of maximizing complex-valued quadratic forms and demonstrate that low-rank structure in the objective matrix can be exploited, leading to alternative algorithms to classical semidefinite programming (SDP) relaxations and heuristic techniques. We propose an algorithm for maximizing these quadratic forms over a domain of size $K$ that enumerates and evaluates a set of $O\left(n^{2r-1}\right)$ candidate solutions, where $n$ is the dimension of the matrix and $r$ represents the rank of an approximation of the objective. We prove that this candidate set is guaranteed to include the exact maximizer when $K=3$ (corresponding to Max-3-Cut) and the objective is low-rank, and provide approximation guarantees when the objective is a perturbation of a low-rank matrix. This construction results in a family of novel, inherently parallelizable and theoretically-motivated algorithms for Max-3-Cut. Extensive experimental results demonstrate that our approach achieves performance comparable to existing algorithms across a wide range of graphs, while being highly scalable.
Unveiling Scaling Behaviors in Molecular Language Models: Effects of Model Size, Data, and Representation
Jan 30, 2026Molecular generative models, often employing GPT-style language modeling on molecular string representations, have shown promising capabilities when scaled to large datasets and model sizes. However, it remains unclear and subject to debate whether these models adhere to predictable scaling laws under fixed computational budgets, which is a crucial understanding for optimally allocating resources between model size, data volume, and molecular representation. In this study, we systematically investigate the scaling behavior of molecular language models across both pretraining and downstream tasks. We train 300 models and conduct over 10,000 experiments, rigorously controlling compute budgets while independently varying model size, number of training tokens, and molecular representation. Our results demonstrate clear scaling laws in molecular models for both pretraining and downstream transfer, reveal the substantial impact of molecular representation on performance, and explain previously observed inconsistencies in scaling behavior for molecular generation. Additionally, we publicly release the largest library of molecular language models to date to facilitate future research and development. Code and models are available at https://github.com/SZU-ADDG/MLM-Scaling.
From Tokens to Blocks: A Block-Diffusion Perspective on Molecular Generation
Jan 29, 2026Drug discovery can be viewed as a combinatorial search over an immense chemical space, motivating the development of deep generative models for de novo molecular design. Among these, GPT-based molecular language models (MLM) have shown strong molecular design performance by learning chemical syntax and semantics from large-scale data. However, existing MLMs face two fundamental limitations: they inadequately capture the graph-structured nature of molecules when formulated as next-token prediction problems, and they typically lack explicit mechanisms for target-aware generation. Here, we propose SoftMol, a unified framework that co-designs molecular representation, model architecture, and search strategy for target-aware molecular generation. SoftMol introduces soft fragments, a rule-free block representation of SMILES that enables diffusion-native modeling, and develops SoftBD, the first block-diffusion molecular language model that combines local bidirectional diffusion with autoregressive generation under molecular structural constraints. To favor generated molecules with high drug-likeness and synthetic accessibility, SoftBD is trained on a carefully curated dataset named ZINC-Curated. SoftMol further integrates a gated Monte Carlo tree search to assemble fragments in a target-aware manner. Experimental results show that, compared with current state-of-the-art models, SoftMol achieves 100% chemical validity, improves binding affinity by 9.7%, yields a 2-3x increase in molecular diversity, and delivers a 6.6x speedup in inference efficiency. Code is available at https://github.com/szu-aicourse/softmol
Toward Closed-loop Molecular Discovery via Language Model, Property Alignment and Strategic Search
Dec 18, 2025Drug discovery is a time-consuming and expensive process, with traditional high-throughput and docking-based virtual screening hampered by low success rates and limited scalability. Recent advances in generative modelling, including autoregressive, diffusion, and flow-based approaches, have enabled de novo ligand design beyond the limits of enumerative screening. Yet these models often suffer from inadequate generalization, limited interpretability, and an overemphasis on binding affinity at the expense of key pharmacological properties, thereby restricting their translational utility. Here we present Trio, a molecular generation framework integrating fragment-based molecular language modeling, reinforcement learning, and Monte Carlo tree search, for effective and interpretable closed-loop targeted molecular design. Through the three key components, Trio enables context-aware fragment assembly, enforces physicochemical and synthetic feasibility, and guides a balanced search between the exploration of novel chemotypes and the exploitation of promising intermediates within protein binding pockets. Experimental results show that Trio reliably achieves chemically valid and pharmacologically enhanced ligands, outperforming state-of-the-art approaches with improved binding affinity (+7.85%), drug-likeness (+11.10%) and synthetic accessibility (+12.05%), while expanding molecular diversity more than fourfold. By combining generalization, plausibility, and interpretability, Trio establishes a closed-loop generative paradigm that redefines how chemical space can be navigated, offering a transformative foundation for the next era of AI-driven drug discovery.
Automating Conflict-Aware ACL Configurations with Natural Language Intents
Aug 25, 2025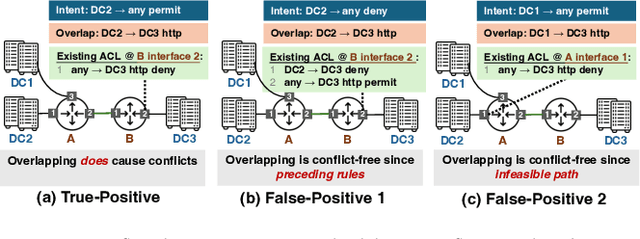

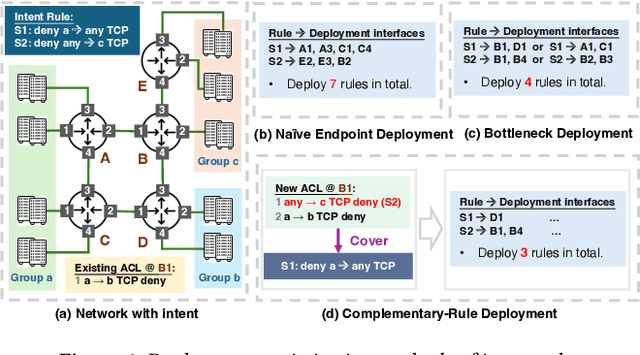
ACL configuration is essential for managing network flow reachability, yet its complexity grows significantly with topologies and pre-existing rules. To carry out ACL configuration, the operator needs to (1) understand the new configuration policies or intents and translate them into concrete ACL rules, (2) check and resolve any conflicts between the new and existing rules, and (3) deploy them across the network. Existing systems rely heavily on manual efforts for these tasks, especially for the first two, which are tedious, error-prone, and impractical to scale. We propose Xumi to tackle this problem. Leveraging LLMs with domain knowledge of the target network, Xumi automatically and accurately translates the natural language intents into complete ACL rules to reduce operators' manual efforts. Xumi then detects all potential conflicts between new and existing rules and generates resolved intents for deployment with operators' guidance, and finally identifies the best deployment plan that minimizes the rule additions while satisfying all intents. Evaluation shows that Xumi accelerates the entire configuration pipeline by over 10x compared to current practices, addresses O(100) conflicting ACLs and reduces rule additions by ~40% in modern cloud network.
BiggerGait: Unlocking Gait Recognition with Layer-wise Representations from Large Vision Models
May 23, 2025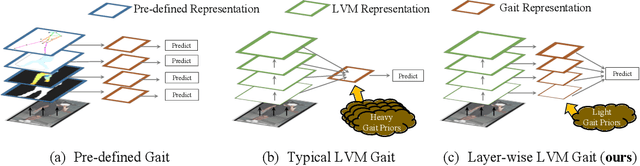
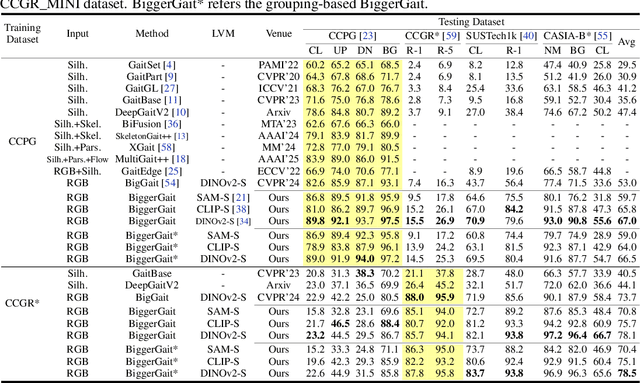
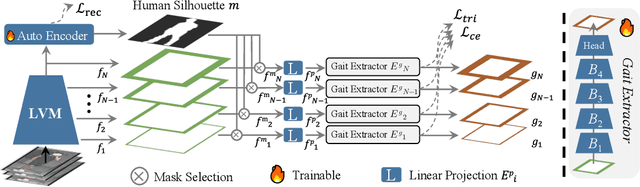
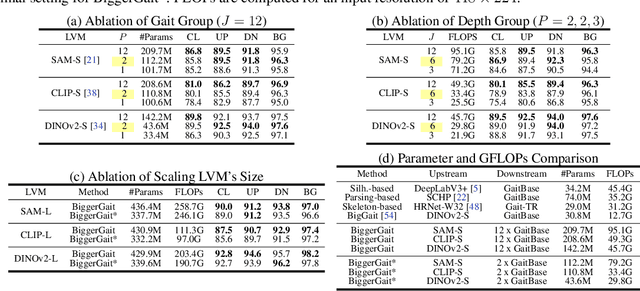
Large vision models (LVM) based gait recognition has achieved impressive performance. However, existing LVM-based approaches may overemphasize gait priors while neglecting the intrinsic value of LVM itself, particularly the rich, distinct representations across its multi-layers. To adequately unlock LVM's potential, this work investigates the impact of layer-wise representations on downstream recognition tasks. Our analysis reveals that LVM's intermediate layers offer complementary properties across tasks, integrating them yields an impressive improvement even without rich well-designed gait priors. Building on this insight, we propose a simple and universal baseline for LVM-based gait recognition, termed BiggerGait. Comprehensive evaluations on CCPG, CAISA-B*, SUSTech1K, and CCGR\_MINI validate the superiority of BiggerGait across both within- and cross-domain tasks, establishing it as a simple yet practical baseline for gait representation learning. All the models and code will be publicly available.
ADNP-15: An Open-Source Histopathological Dataset for Neuritic Plaque Segmentation in Human Brain Whole Slide Images with Frequency Domain Image Enhancement for Stain Normalization
May 08, 2025Alzheimer's Disease (AD) is a neurodegenerative disorder characterized by amyloid-beta plaques and tau neurofibrillary tangles, which serve as key histopathological features. The identification and segmentation of these lesions are crucial for understanding AD progression but remain challenging due to the lack of large-scale annotated datasets and the impact of staining variations on automated image analysis. Deep learning has emerged as a powerful tool for pathology image segmentation; however, model performance is significantly influenced by variations in staining characteristics, necessitating effective stain normalization and enhancement techniques. In this study, we address these challenges by introducing an open-source dataset (ADNP-15) of neuritic plaques (i.e., amyloid deposits combined with a crown of dystrophic tau-positive neurites) in human brain whole slide images. We establish a comprehensive benchmark by evaluating five widely adopted deep learning models across four stain normalization techniques, providing deeper insights into their influence on neuritic plaque segmentation. Additionally, we propose a novel image enhancement method that improves segmentation accuracy, particularly in complex tissue structures, by enhancing structural details and mitigating staining inconsistencies. Our experimental results demonstrate that this enhancement strategy significantly boosts model generalization and segmentation accuracy. All datasets and code are open-source, ensuring transparency and reproducibility while enabling further advancements in the field.