 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCMU's IWSLT 2025 Simultaneous Speech Translation System
Jun 16, 2025This paper presents CMU's submission to the IWSLT 2025 Simultaneous Speech Translation (SST) task for translating unsegmented English speech into Chinese and German text in a streaming manner. Our end-to-end speech-to-text system integrates a chunkwise causal Wav2Vec 2.0 speech encoder, an adapter, and the Qwen2.5-7B-Instruct as the decoder. We use a two-stage simultaneous training procedure on robust speech segments curated from LibriSpeech, CommonVoice, and VoxPopuli datasets, utilizing standard cross-entropy loss. Our model supports adjustable latency through a configurable latency multiplier. Experimental results demonstrate that our system achieves 44.3 BLEU for English-to-Chinese and 25.1 BLEU for English-to-German translations on the ACL60/60 development set, with computation-aware latencies of 2.7 seconds and 2.3 seconds, and theoretical latencies of 2.2 and 1.7 seconds, respectively.
InfiniSST: Simultaneous Translation of Unbounded Speech with Large Language Model
Mar 04, 2025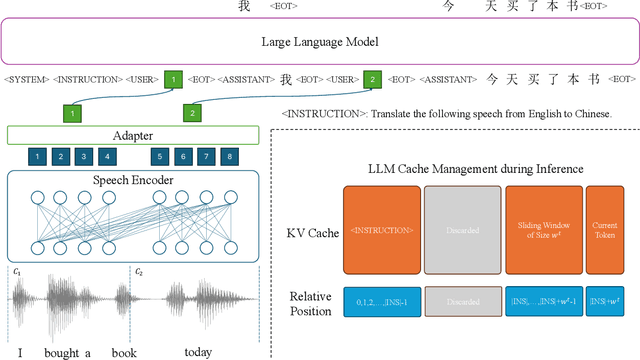



Simultaneous translation of unbounded streaming speech remains a challenging problem due to the need for effectively processing the history speech context and past translations so that quality and latency, including computation overhead, can be balanced. Most prior works assume pre-segmented speech, limiting their real-world applicability. In this paper, we propose InfiniSST, a novel approach that formulates SST as a multi-turn dialogue task, enabling seamless translation of unbounded speech. We construct translation trajectories and robust segments from MuST-C with multi-latency augmentation during training and develop a key-value (KV) cache management strategy to facilitate efficient inference. Experiments on MuST-C En-Es, En-De, and En-Zh demonstrate that InfiniSST reduces computation-aware latency by 0.5 to 1 second while maintaining the same translation quality compared to baselines. Ablation studies further validate the contributions of our data construction and cache management strategy. We release the code at https://github.com/LeiLiLab/InfiniSST
Topology and Intersection-Union Constrained Loss Function for Multi-Region Anatomical Segmentation in Ocular Images
Nov 01, 2024



Ocular Myasthenia Gravis (OMG) is a rare and challenging disease to detect in its early stages, but symptoms often first appear in the eye muscles, such as drooping eyelids and double vision. Ocular images can be used for early diagnosis by segmenting different regions, such as the sclera, iris, and pupil, which allows for the calculation of area ratios to support accurate medical assessments. However, no publicly available dataset and tools currently exist for this purpose. To address this, we propose a new topology and intersection-union constrained loss function (TIU loss) that improves performance using small training datasets. We conducted experiments on a public dataset consisting of 55 subjects and 2,197 images. Our proposed method outperformed two widely used loss functions across three deep learning networks, achieving a mean Dice score of 83.12% [82.47%, 83.81%] with a 95% bootstrap confidence interval. In a low-percentage training scenario (10% of the training data), our approach showed an 8.32% improvement in Dice score compared to the baseline. Additionally, we evaluated the method in a clinical setting with 47 subjects and 501 images, achieving a Dice score of 64.44% [63.22%, 65.62%]. We did observe some bias when applying the model in clinical settings. These results demonstrate that the proposed method is accurate, and our code along with the trained model is publicly available.
CA*: Addressing Evaluation Pitfalls in Computation-Aware Latency for Simultaneous Speech Translation
Oct 21, 2024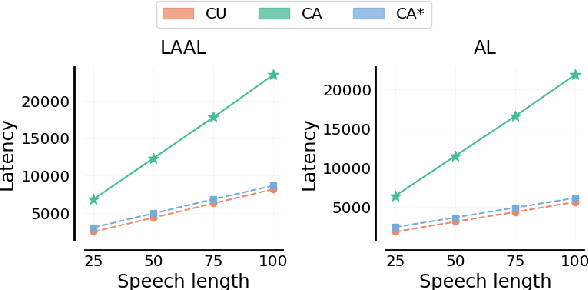

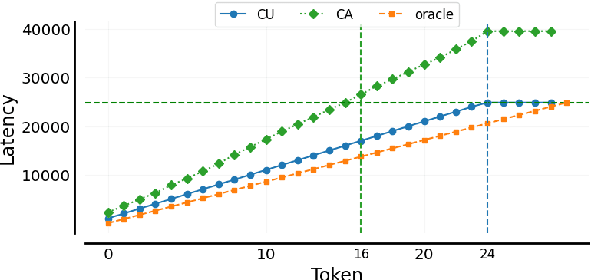
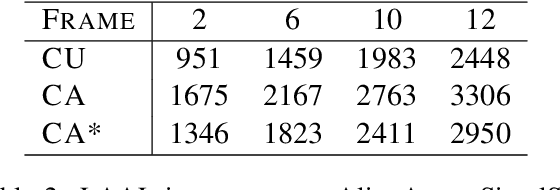
Simultaneous speech translation (SimulST) systems must balance translation quality with response time, making latency measurement crucial for evaluating their real-world performance. However, there has been a longstanding belief that current metrics yield unrealistically high latency measurements in unsegmented streaming settings. In this paper, we investigate this phenomenon, revealing its root cause in a fundamental misconception underlying existing latency evaluation approaches. We demonstrate that this issue affects not only streaming but also segment-level latency evaluation across different metrics. Furthermore, we propose a modification to correctly measure computation-aware latency for SimulST systems, addressing the limitations present in existing metrics.
Translation Canvas: An Explainable Interface to Pinpoint and Analyze Translation Systems
Oct 07, 2024


With the rapid advancement of machine translation research, evaluation toolkits have become essential for benchmarking system progress. Tools like COMET and SacreBLEU offer single quality score assessments that are effective for pairwise system comparisons. However, these tools provide limited insights for fine-grained system-level comparisons and the analysis of instance-level defects. To address these limitations, we introduce Translation Canvas, an explainable interface designed to pinpoint and analyze translation systems' performance: 1) Translation Canvas assists machine translation researchers in comprehending system-level model performance by identifying common errors (their frequency and severity) and analyzing relationships between different systems based on various evaluation metrics. 2) It supports fine-grained analysis by highlighting error spans with explanations and selectively displaying systems' predictions. According to human evaluation, Translation Canvas demonstrates superior performance over COMET and SacreBLEU packages under enjoyability and understandability criteria.
FASST: Fast LLM-based Simultaneous Speech Translation
Aug 18, 2024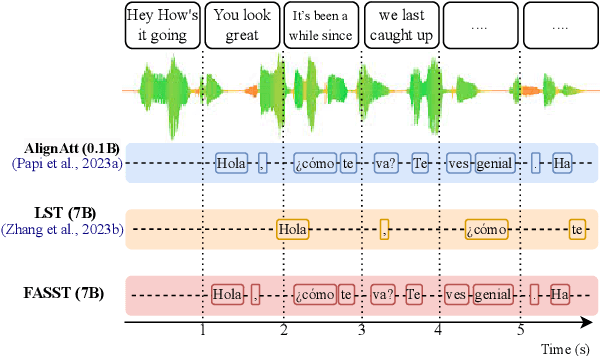

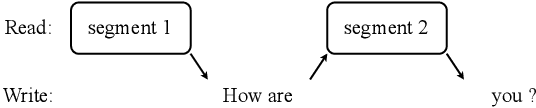

Simultaneous speech translation (SST) takes streaming speech input and generates text translation on the fly. Existing methods either have high latency due to recomputation of input representations, or fall behind of offline ST in translation quality. In this paper, we propose FASST, a fast large language model based method for streaming speech translation. We propose blockwise-causal speech encoding and consistency mask, so that streaming speech input can be encoded incrementally without recomputation. Furthermore, we develop a two-stage training strategy to optimize FASST for simultaneous inference. We evaluate FASST and multiple strong prior models on MuST-C dataset. Experiment results show that FASST achieves the best quality-latency trade-off. It outperforms the previous best model by an average of 1.5 BLEU under the same latency for English to Spanish translation.
CMU's IWSLT 2024 Simultaneous Speech Translation System
Aug 14, 2024This paper describes CMU's submission to the IWSLT 2024 Simultaneous Speech Translation (SST) task for translating English speech to German text in a streaming manner. Our end-to-end speech-to-text (ST) system integrates the WavLM speech encoder, a modality adapter, and the Llama2-7B-Base model as the decoder. We employ a two-stage training approach: initially, we align the representations of speech and text, followed by full fine-tuning. Both stages are trained on MuST-c v2 data with cross-entropy loss. We adapt our offline ST model for SST using a simple fixed hold-n policy. Experiments show that our model obtains an offline BLEU score of 31.1 and a BLEU score of 29.5 under 2 seconds latency on the MuST-C-v2 tst-COMMON.
How to Determine the Most Powerful Pre-trained Language Model without Brute Force Fine-tuning? An Empirical Survey
Dec 08, 2023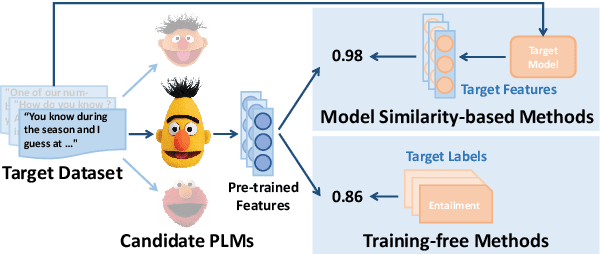
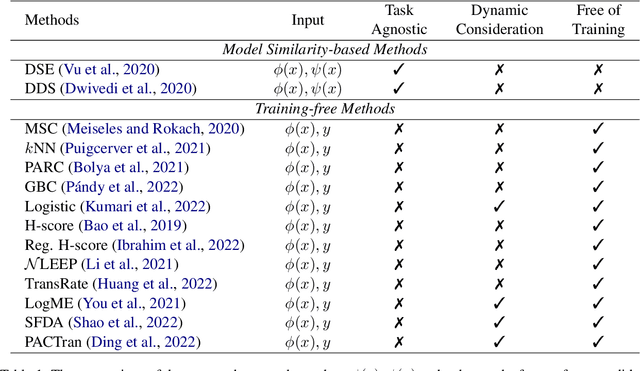
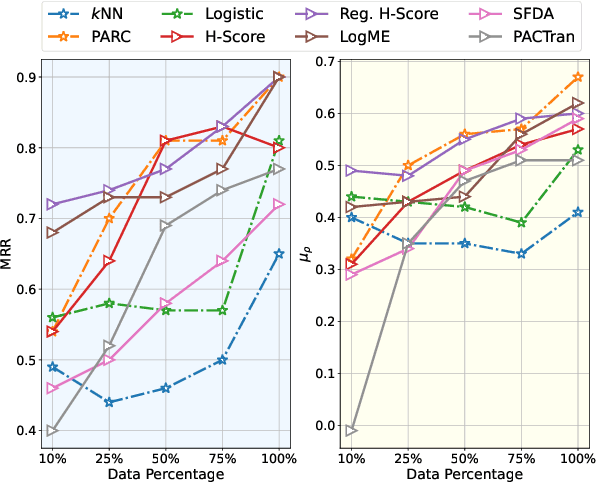
Transferability estimation has been attached to great attention in the computer vision fields. Researchers try to estimate with low computational cost the performance of a model when transferred from a source task to a given target task. Considering the effectiveness of such estimations, the communities of natural language processing also began to study similar problems for the selection of pre-trained language models. However, there is a lack of a comprehensive comparison between these estimation methods yet. Also, the differences between vision and language scenarios make it doubtful whether previous conclusions can be established across fields. In this paper, we first conduct a thorough survey of existing transferability estimation methods being able to find the most suitable model, then we conduct a detailed empirical study for the surveyed methods based on the GLUE benchmark. From qualitative and quantitative analyses, we demonstrate the strengths and weaknesses of existing methods and show that H-Score generally performs well with superiorities in effectiveness and efficiency. We also outline the difficulties of consideration of training details, applicability to text generation, and consistency to certain metrics which shed light on future directions.
A Two-Stage Generative Model with CycleGAN and Joint Diffusion for MRI-based Brain Tumor Detection
Nov 06, 2023Accurate detection and segmentation of brain tumors is critical for medical diagnosis. However, current supervised learning methods require extensively annotated images and the state-of-the-art generative models used in unsupervised methods often have limitations in covering the whole data distribution. In this paper, we propose a novel framework Two-Stage Generative Model (TSGM) that combines Cycle Generative Adversarial Network (CycleGAN) and Variance Exploding stochastic differential equation using joint probability (VE-JP) to improve brain tumor detection and segmentation. The CycleGAN is trained on unpaired data to generate abnormal images from healthy images as data prior. Then VE-JP is implemented to reconstruct healthy images using synthetic paired abnormal images as a guide, which alters only pathological regions but not regions of healthy. Notably, our method directly learned the joint probability distribution for conditional generation. The residual between input and reconstructed images suggests the abnormalities and a thresholding method is subsequently applied to obtain segmentation results. Furthermore, the multimodal results are weighted with different weights to improve the segmentation accuracy further. We validated our method on three datasets, and compared with other unsupervised methods for anomaly detection and segmentation. The DSC score of 0.8590 in BraTs2020 dataset, 0.6226 in ITCS dataset and 0.7403 in In-house dataset show that our method achieves better segmentation performance and has better generalization.
CRRS: Concentric Rectangles Regression Strategy for Multi-point Representation on Fisheye Images
Mar 26, 2023Modern object detectors take advantage of rectangular bounding boxes as a conventional way to represent objects. When it comes to fisheye images, rectangular boxes involve more background noise rather than semantic information. Although multi-point representation has been proposed, both the regression accuracy and convergence still perform inferior to the widely used rectangular boxes. In order to further exploit the advantages of multi-point representation for distorted images, Concentric Rectangles Regression Strategy(CRRS) is proposed in this work. We adopt smoother mean loss to allocate weights and discuss the effect of hyper-parameter to prediction results. Moreover, an accurate pixel-level method is designed to obtain irregular IoU for estimating detector performance. Compared with the previous work for muti-point representation, the experiments show that CRRS can improve the training performance both in accurate and stability. We also prove that multi-task weighting strategy facilitates regression process in this design.