 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverview of the NLPCC 2025 Shared Task: Gender Bias Mitigation Challenge
Jun 14, 2025As natural language processing for gender bias becomes a significant interdisciplinary topic, the prevalent data-driven techniques, such as pre-trained language models, suffer from biased corpus. This case becomes more obvious regarding those languages with less fairness-related computational linguistic resources, such as Chinese. To this end, we propose a Chinese cOrpus foR Gender bIas Probing and Mitigation (CORGI-PM), which contains 32.9k sentences with high-quality labels derived by following an annotation scheme specifically developed for gender bias in the Chinese context. It is worth noting that CORGI-PM contains 5.2k gender-biased sentences along with the corresponding bias-eliminated versions rewritten by human annotators. We pose three challenges as a shared task to automate the mitigation of textual gender bias, which requires the models to detect, classify, and mitigate textual gender bias. In the literature, we present the results and analysis for the teams participating this shared task in NLPCC 2025.
Beyond One-Size-Fits-All: Inversion Learning for Highly Effective NLG Evaluation Prompts
Apr 29, 2025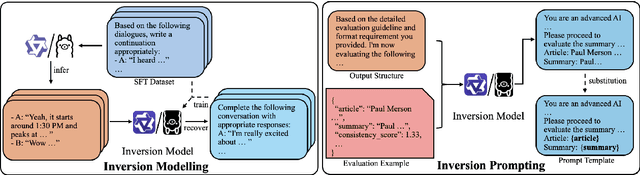
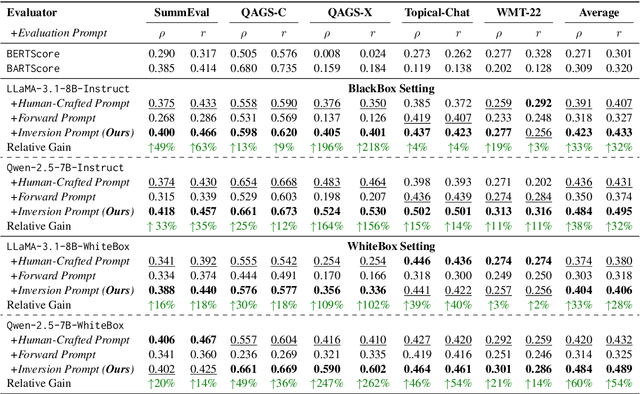

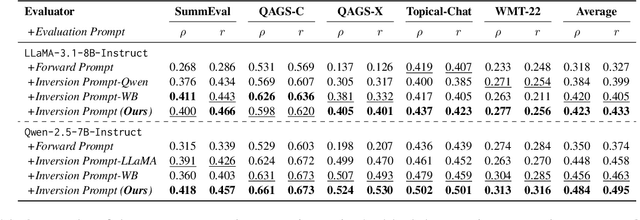
Evaluating natural language generation (NLG) systems is challenging due to the diversity of valid outputs. While human evaluation is the gold standard, it suffers from inconsistencies, lack of standardisation, and demographic biases, limiting reproducibility. LLM-based evaluation offers a scalable alternative but is highly sensitive to prompt design, where small variations can lead to significant discrepancies. In this work, we propose an inversion learning method that learns effective reverse mappings from model outputs back to their input instructions, enabling the automatic generation of highly effective, model-specific evaluation prompts. Our method requires only a single evaluation sample and eliminates the need for time-consuming manual prompt engineering, thereby improving both efficiency and robustness. Our work contributes toward a new direction for more robust and efficient LLM-based evaluation.
Leveraging Estimated Transferability Over Human Intuition for Model Selection in Text Ranking
Sep 24, 2024


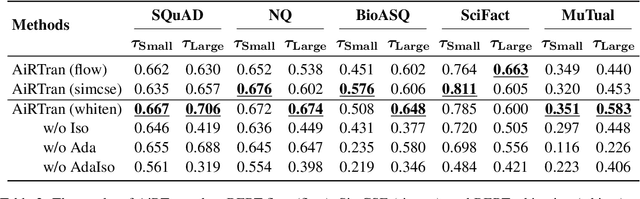
Text ranking has witnessed significant advancements, attributed to the utilization of dual-encoder enhanced by Pre-trained Language Models (PLMs). Given the proliferation of available PLMs, selecting the most effective one for a given dataset has become a non-trivial challenge. As a promising alternative to human intuition and brute-force fine-tuning, Transferability Estimation (TE) has emerged as an effective approach to model selection. However, current TE methods are primarily designed for classification tasks, and their estimated transferability may not align well with the objectives of text ranking. To address this challenge, we propose to compute the expected rank as transferability, explicitly reflecting the model's ranking capability. Furthermore, to mitigate anisotropy and incorporate training dynamics, we adaptively scale isotropic sentence embeddings to yield an accurate expected rank score. Our resulting method, Adaptive Ranking Transferability (AiRTran), can effectively capture subtle differences between models. On challenging model selection scenarios across various text ranking datasets, it demonstrates significant improvements over previous classification-oriented TE methods, human intuition, and ChatGPT with minor time consumption.
How to Determine the Most Powerful Pre-trained Language Model without Brute Force Fine-tuning? An Empirical Survey
Dec 08, 2023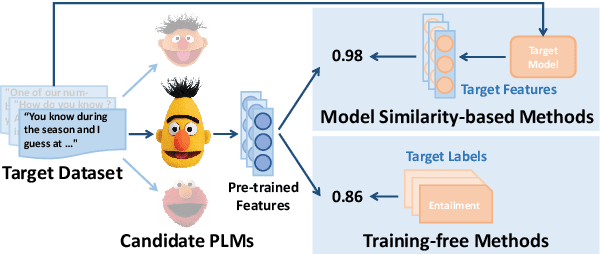
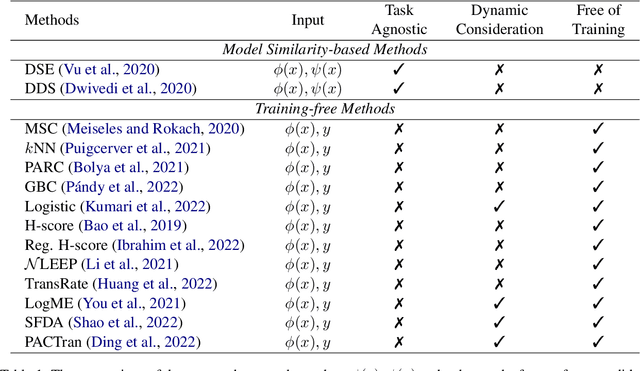
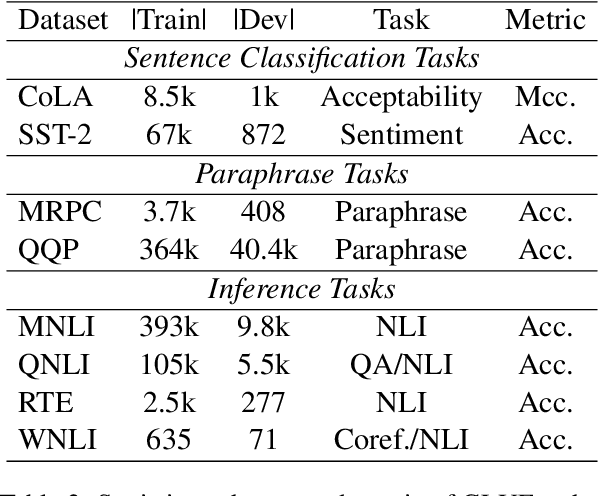
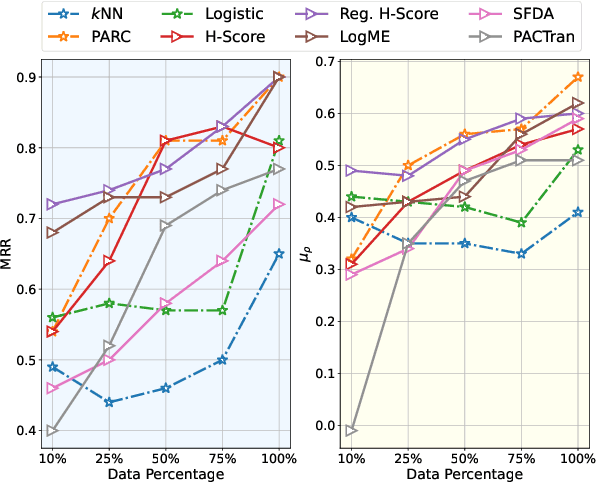
Transferability estimation has been attached to great attention in the computer vision fields. Researchers try to estimate with low computational cost the performance of a model when transferred from a source task to a given target task. Considering the effectiveness of such estimations, the communities of natural language processing also began to study similar problems for the selection of pre-trained language models. However, there is a lack of a comprehensive comparison between these estimation methods yet. Also, the differences between vision and language scenarios make it doubtful whether previous conclusions can be established across fields. In this paper, we first conduct a thorough survey of existing transferability estimation methods being able to find the most suitable model, then we conduct a detailed empirical study for the surveyed methods based on the GLUE benchmark. From qualitative and quantitative analyses, we demonstrate the strengths and weaknesses of existing methods and show that H-Score generally performs well with superiorities in effectiveness and efficiency. We also outline the difficulties of consideration of training details, applicability to text generation, and consistency to certain metrics which shed light on future directions.