 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
CME-CAD: Heterogeneous Collaborative Multi-Expert Reinforcement Learning for CAD Code Generation
Dec 29, 2025Computer-Aided Design (CAD) is essential in industrial design, but the complexity of traditional CAD modeling and workflows presents significant challenges for automating the generation of high-precision, editable CAD models. Existing methods that reconstruct 3D models from sketches often produce non-editable and approximate models that fall short of meeting the stringent requirements for precision and editability in industrial design. Moreover, the reliance on text or image-based inputs often requires significant manual annotation, limiting their scalability and applicability in industrial settings. To overcome these challenges, we propose the Heterogeneous Collaborative Multi-Expert Reinforcement Learning (CME-CAD) paradigm, a novel training paradigm for CAD code generation. Our approach integrates the complementary strengths of these models, facilitating collaborative learning and improving the model's ability to generate accurate, constraint-compatible, and fully editable CAD models. We introduce a two-stage training process: Multi-Expert Fine-Tuning (MEFT), and Multi-Expert Reinforcement Learning (MERL). Additionally, we present CADExpert, an open-source benchmark consisting of 17,299 instances, including orthographic projections with precise dimension annotations, expert-generated Chain-of-Thought (CoT) processes, executable CADQuery code, and rendered 3D models.
The Interaction Bottleneck of Deep Neural Networks: Discovery, Proof, and Modulation
Dec 21, 2025Understanding what kinds of cooperative structures deep neural networks (DNNs) can represent remains a fundamental yet insufficiently understood problem. In this work, we treat interactions as the fundamental units of such structure and investigate a largely unexplored question: how DNNs encode interactions under different levels of contextual complexity, and how these microscopic interaction patterns shape macroscopic representation capacity. To quantify this complexity, we use multi-order interactions [57], where each order reflects the amount of contextual information required to evaluate the joint interaction utility of a variable pair. This formulation enables a stratified analysis of cooperative patterns learned by DNNs. Building on this formulation, we develop a comprehensive study of interaction structure in DNNs. (i) We empirically discover a universal interaction bottleneck: across architectures and tasks, DNNs easily learn low-order and high-order interactions but consistently under-represent mid-order ones. (ii) We theoretically explain this bottleneck by proving that mid-order interactions incur the highest contextual variability, yielding large gradient variance and making them intrinsically difficult to learn. (iii) We further modulate the bottleneck by introducing losses that steer models toward emphasizing interactions of selected orders. Finally, we connect microscopic interaction structures with macroscopic representational behavior: low-order-emphasized models exhibit stronger generalization and robustness, whereas high-order-emphasized models demonstrate greater structural modeling and fitting capability. Together, these results uncover an inherent representational bias in modern DNNs and establish interaction order as a powerful lens for interpreting and guiding deep representations.
From Intent to Execution: Multimodal Chain-of-Thought Reinforcement Learning for Precise CAD Code Generation
Aug 13, 2025Computer-Aided Design (CAD) plays a vital role in engineering and manufacturing, yet current CAD workflows require extensive domain expertise and manual modeling effort. Recent advances in large language models (LLMs) have made it possible to generate code from natural language, opening new opportunities for automating parametric 3D modeling. However, directly translating human design intent into executable CAD code remains highly challenging, due to the need for logical reasoning, syntactic correctness, and numerical precision. In this work, we propose CAD-RL, a multimodal Chain-of-Thought (CoT) guided reinforcement learning post training framework for CAD modeling code generation. Our method combines CoT-based Cold Start with goal-driven reinforcement learning post training using three task-specific rewards: executability reward, geometric accuracy reward, and external evaluation reward. To ensure stable policy learning under sparse and high-variance reward conditions, we introduce three targeted optimization strategies: Trust Region Stretch for improved exploration, Precision Token Loss for enhanced dimensions parameter accuracy, and Overlong Filtering to reduce noisy supervision. To support training and benchmarking, we release ExeCAD, a noval dataset comprising 16,540 real-world CAD examples with paired natural language and structured design language descriptions, executable CADQuery scripts, and rendered 3D models. Experiments demonstrate that CAD-RL achieves significant improvements in reasoning quality, output precision, and code executability over existing VLMs.
CrowdTrack: A Benchmark for Difficult Multiple Pedestrian Tracking in Real Scenarios
Jul 03, 2025Multi-object tracking is a classic field in computer vision. Among them, pedestrian tracking has extremely high application value and has become the most popular research category. Existing methods mainly use motion or appearance information for tracking, which is often difficult in complex scenarios. For the motion information, mutual occlusions between objects often prevent updating of the motion state; for the appearance information, non-robust results are often obtained due to reasons such as only partial visibility of the object or blurred images. Although learning how to perform tracking in these situations from the annotated data is the simplest solution, the existing MOT dataset fails to satisfy this solution. Existing methods mainly have two drawbacks: relatively simple scene composition and non-realistic scenarios. Although some of the video sequences in existing dataset do not have the above-mentioned drawbacks, the number is far from adequate for research purposes. To this end, we propose a difficult large-scale dataset for multi-pedestrian tracking, shot mainly from the first-person view and all from real-life complex scenarios. We name it ``CrowdTrack'' because there are numerous objects in most of the sequences. Our dataset consists of 33 videos, containing a total of 5,185 trajectories. Each object is annotated with a complete bounding box and a unique object ID. The dataset will provide a platform to facilitate the development of algorithms that remain effective in complex situations. We analyzed the dataset comprehensively and tested multiple SOTA models on our dataset. Besides, we analyzed the performance of the foundation models on our dataset. The dataset and project code is released at: https://github.com/loseevaya/CrowdTrack .
Leveraging Estimated Transferability Over Human Intuition for Model Selection in Text Ranking
Sep 24, 2024


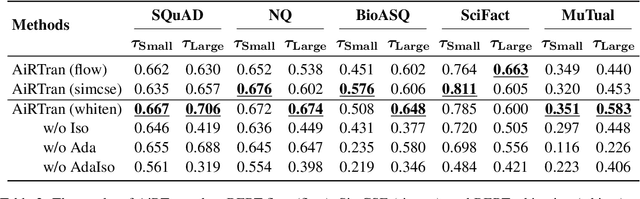
Text ranking has witnessed significant advancements, attributed to the utilization of dual-encoder enhanced by Pre-trained Language Models (PLMs). Given the proliferation of available PLMs, selecting the most effective one for a given dataset has become a non-trivial challenge. As a promising alternative to human intuition and brute-force fine-tuning, Transferability Estimation (TE) has emerged as an effective approach to model selection. However, current TE methods are primarily designed for classification tasks, and their estimated transferability may not align well with the objectives of text ranking. To address this challenge, we propose to compute the expected rank as transferability, explicitly reflecting the model's ranking capability. Furthermore, to mitigate anisotropy and incorporate training dynamics, we adaptively scale isotropic sentence embeddings to yield an accurate expected rank score. Our resulting method, Adaptive Ranking Transferability (AiRTran), can effectively capture subtle differences between models. On challenging model selection scenarios across various text ranking datasets, it demonstrates significant improvements over previous classification-oriented TE methods, human intuition, and ChatGPT with minor time consumption.
A Review of Data Mining in Personalized Education: Current Trends and Future Prospects
Feb 27, 2024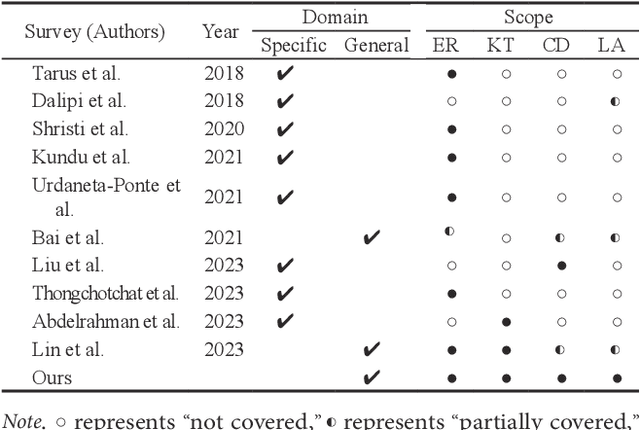
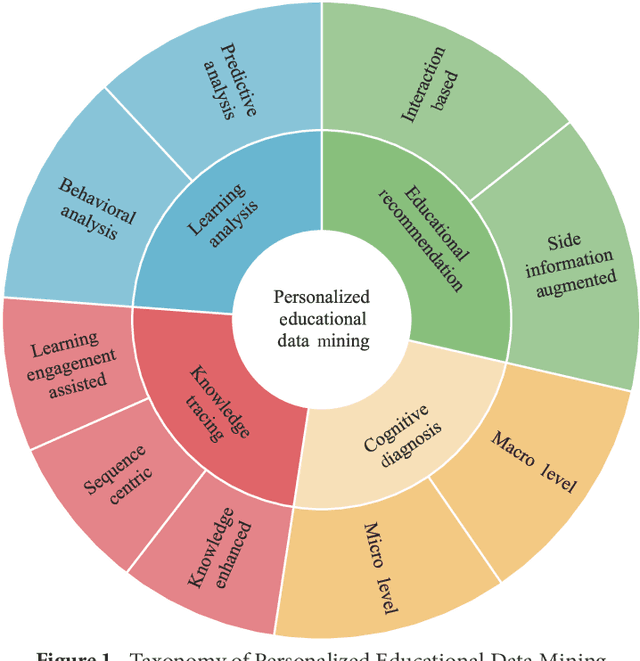
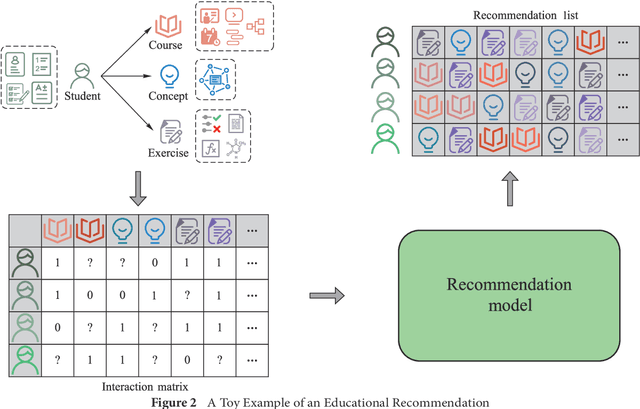
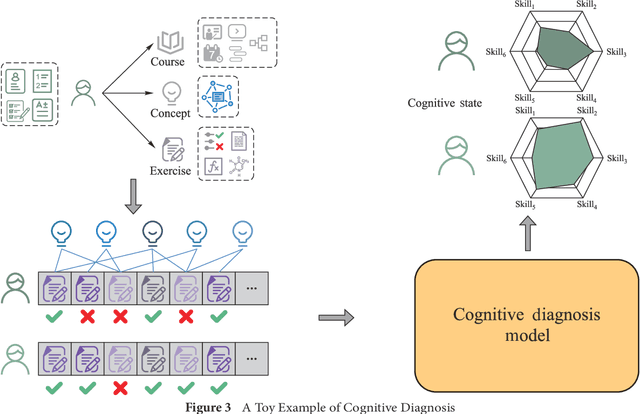
Personalized education, tailored to individual student needs, leverages educational technology and artificial intelligence (AI) in the digital age to enhance learning effectiveness. The integration of AI in educational platforms provides insights into academic performance, learning preferences, and behaviors, optimizing the personal learning process. Driven by data mining techniques, it not only benefits students but also provides educators and institutions with tools to craft customized learning experiences. To offer a comprehensive review of recent advancements in personalized educational data mining, this paper focuses on four primary scenarios: educational recommendation, cognitive diagnosis, knowledge tracing, and learning analysis. This paper presents a structured taxonomy for each area, compiles commonly used datasets, and identifies future research directions, emphasizing the role of data mining in enhancing personalized education and paving the way for future exploration and innovation.
* 25 pages, 5 figures