 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHead Anchor Enhanced Detection and Association for Crowded Pedestrian Tracking
Aug 07, 2025Visual pedestrian tracking represents a promising research field, with extensive applications in intelligent surveillance, behavior analysis, and human-computer interaction. However, real-world applications face significant occlusion challenges. When multiple pedestrians interact or overlap, the loss of target features severely compromises the tracker's ability to maintain stable trajectories. Traditional tracking methods, which typically rely on full-body bounding box features extracted from {Re-ID} models and linear constant-velocity motion assumptions, often struggle in severe occlusion scenarios. To address these limitations, this work proposes an enhanced tracking framework that leverages richer feature representations and a more robust motion model. Specifically, the proposed method incorporates detection features from both the regression and classification branches of an object detector, embedding spatial and positional information directly into the feature representations. To further mitigate occlusion challenges, a head keypoint detection model is introduced, as the head is less prone to occlusion compared to the full body. In terms of motion modeling, we propose an iterative Kalman filtering approach designed to align with modern detector assumptions, integrating 3D priors to better complete motion trajectories in complex scenes. By combining these advancements in appearance and motion modeling, the proposed method offers a more robust solution for multi-object tracking in crowded environments where occlusions are prevalent.
Multi-tracklet Tracking for Generic Targets with Adaptive Detection Clustering
Aug 07, 2025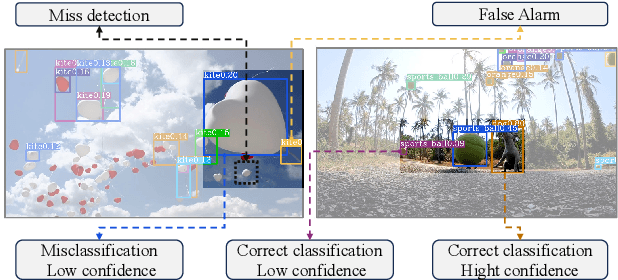
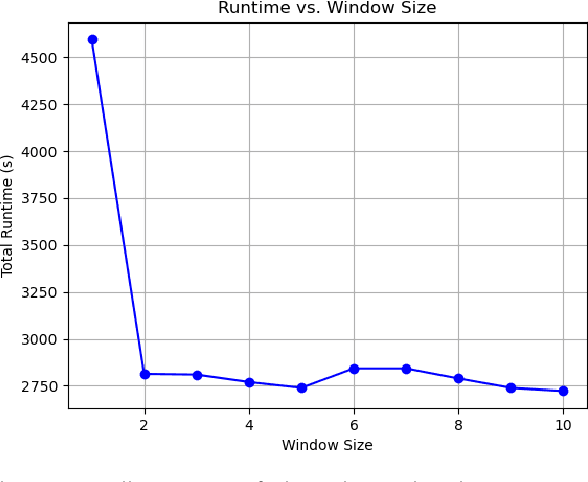
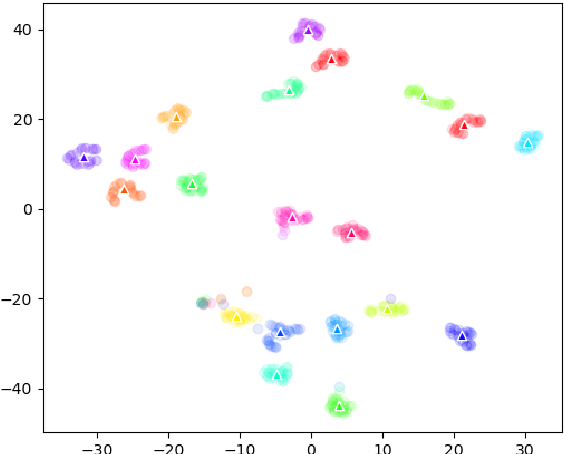
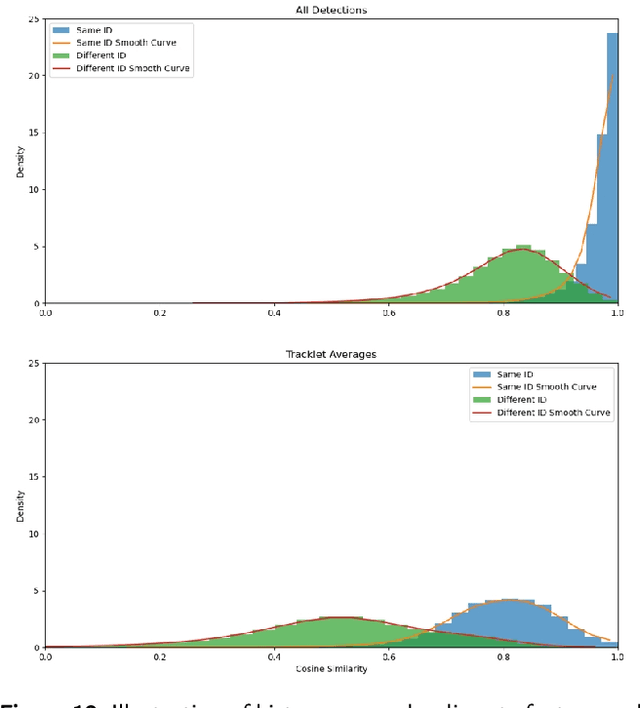
Tracking specific targets, such as pedestrians and vehicles, has been the focus of recent vision-based multitarget tracking studies. However, in some real-world scenarios, unseen categories often challenge existing methods due to low-confidence detections, weak motion and appearance constraints, and long-term occlusions. To address these issues, this article proposes a tracklet-enhanced tracker called Multi-Tracklet Tracking (MTT) that integrates flexible tracklet generation into a multi-tracklet association framework. This framework first adaptively clusters the detection results according to their short-term spatio-temporal correlation into robust tracklets and then estimates the best tracklet partitions using multiple clues, such as location and appearance over time to mitigate error propagation in long-term association. Finally, extensive experiments on the benchmark for generic multiple object tracking demonstrate the competitiveness of the proposed framework.
AAKT: Enhancing Knowledge Tracing with Alternate Autoregressive Modeling
Feb 17, 2025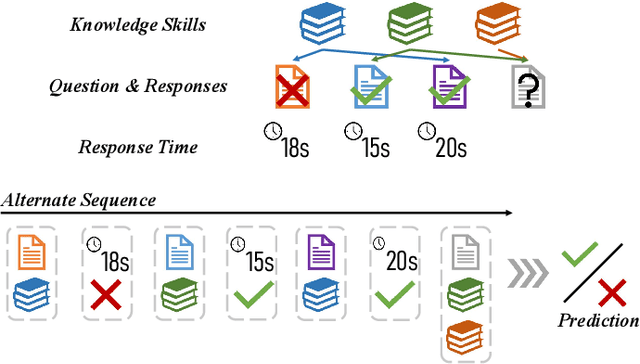
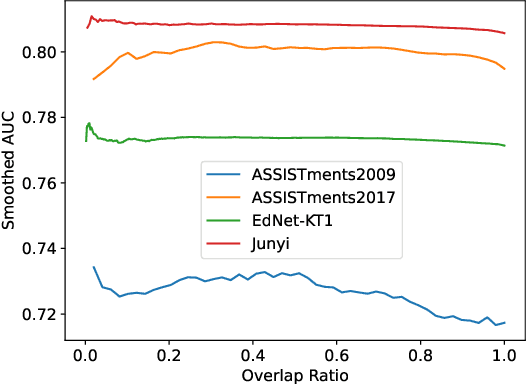
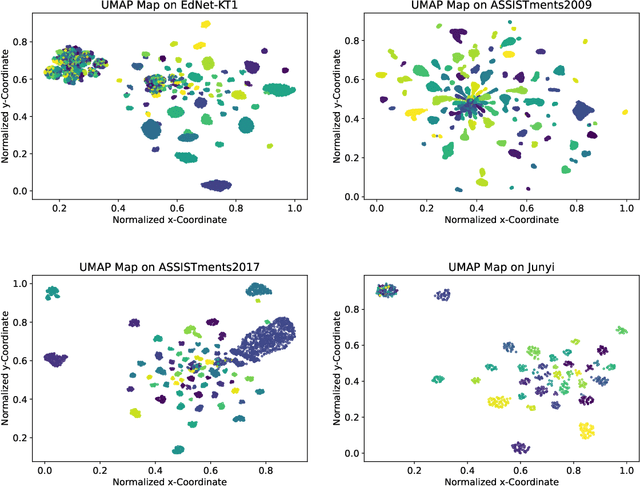
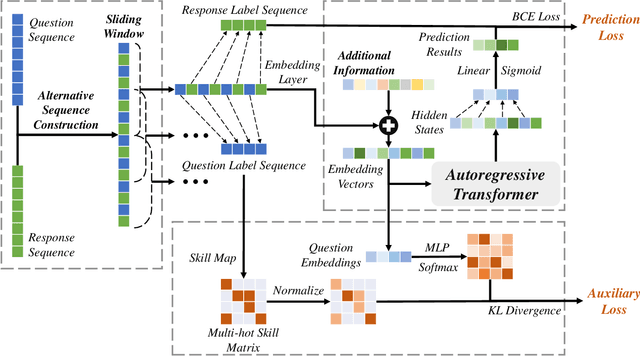
Knowledge Tracing (KT) aims to predict students' future performances based on their former exercises and additional information in educational settings. KT has received significant attention since it facilitates personalized experiences in educational situations. Simultaneously, the autoregressive modeling on the sequence of former exercises has been proven effective for this task. One of the primary challenges in autoregressive modeling for Knowledge Tracing is effectively representing the anterior (pre-response) and posterior (post-response) states of learners across exercises. Existing methods often employ complex model architectures to update learner states using question and response records. In this study, we propose a novel perspective on knowledge tracing task by treating it as a generative process, consistent with the principles of autoregressive models. We demonstrate that knowledge states can be directly represented through autoregressive encodings on a question-response alternate sequence, where model generate the most probable representation in hidden state space by analyzing history interactions. This approach underpins our framework, termed Alternate Autoregressive Knowledge Tracing (AAKT). Additionally, we incorporate supplementary educational information, such as question-related skills, into our framework through an auxiliary task, and include extra exercise details, like response time, as additional inputs. Our proposed framework is implemented using advanced autoregressive technologies from Natural Language Generation (NLG) for both training and prediction. Empirical evaluations on four real-world KT datasets indicate that AAKT consistently outperforms all baseline models in terms of AUC, ACC, and RMSE. Furthermore, extensive ablation studies and visualized analysis validate the effectiveness of key components in AAKT.
Explainable Few-shot Knowledge Tracing
May 23, 2024



Knowledge tracing (KT), aiming to mine students' mastery of knowledge by their exercise records and predict their performance on future test questions, is a critical task in educational assessment. While researchers achieved tremendous success with the rapid development of deep learning techniques, current knowledge tracing tasks fall into the cracks from real-world teaching scenarios. Relying heavily on extensive student data and solely predicting numerical performances differs from the settings where teachers assess students' knowledge state from limited practices and provide explanatory feedback. To fill this gap, we explore a new task formulation: Explainable Few-shot Knowledge Tracing. By leveraging the powerful reasoning and generation abilities of large language models (LLMs), we then propose a cognition-guided framework that can track the student knowledge from a few student records while providing natural language explanations. Experimental results from three widely used datasets show that LLMs can perform comparable or superior to competitive deep knowledge tracing methods. We also discuss potential directions and call for future improvements in relevant topics.
Wasserstein Dependent Graph Attention Network for Collaborative Filtering with Uncertainty
Apr 09, 2024



Collaborative filtering (CF) is an essential technique in recommender systems that provides personalized recommendations by only leveraging user-item interactions. However, most CF methods represent users and items as fixed points in the latent space, lacking the ability to capture uncertainty. In this paper, we propose a novel approach, called the Wasserstein dependent Graph ATtention network (W-GAT), for collaborative filtering with uncertainty. We utilize graph attention network and Wasserstein distance to address the limitations of LightGCN and Kullback-Leibler divergence (KL) divergence to learn Gaussian embedding for each user and item. Additionally, our method incorporates Wasserstein-dependent mutual information further to increase the similarity between positive pairs and to tackle the challenges induced by KL divergence. Experimental results on three benchmark datasets show the superiority of W-GAT compared to several representative baselines. Extensive experimental analysis validates the effectiveness of W-GAT in capturing uncertainty by modeling the range of user preferences and categories associated with items.
A Review of Data Mining in Personalized Education: Current Trends and Future Prospects
Feb 27, 2024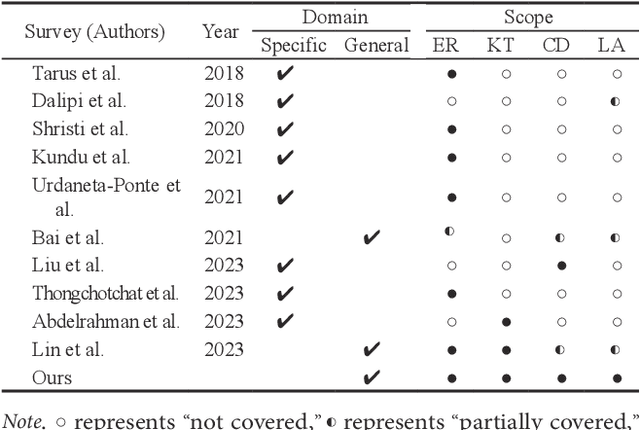
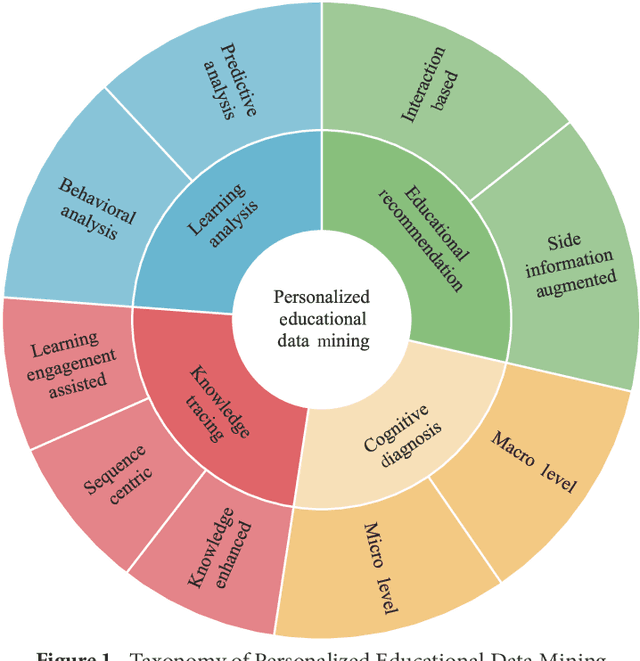
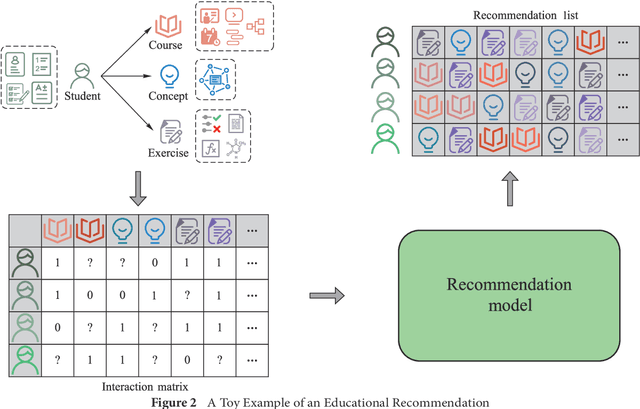
Personalized education, tailored to individual student needs, leverages educational technology and artificial intelligence (AI) in the digital age to enhance learning effectiveness. The integration of AI in educational platforms provides insights into academic performance, learning preferences, and behaviors, optimizing the personal learning process. Driven by data mining techniques, it not only benefits students but also provides educators and institutions with tools to craft customized learning experiences. To offer a comprehensive review of recent advancements in personalized educational data mining, this paper focuses on four primary scenarios: educational recommendation, cognitive diagnosis, knowledge tracing, and learning analysis. This paper presents a structured taxonomy for each area, compiles commonly used datasets, and identifies future research directions, emphasizing the role of data mining in enhancing personalized education and paving the way for future exploration and innovation.
* 25 pages, 5 figures
Knowledge-Driven CoT: Exploring Faithful Reasoning in LLMs for Knowledge-intensive Question Answering
Aug 25, 2023



Equipped with Chain-of-Thought (CoT), Large language models (LLMs) have shown impressive reasoning ability in various downstream tasks. Even so, suffering from hallucinations and the inability to access external knowledge, LLMs often come with incorrect or unfaithful intermediate reasoning steps, especially in the context of answering knowledge-intensive tasks such as KBQA. To alleviate this issue, we propose a framework called Knowledge-Driven Chain-of-Thought (KD-CoT) to verify and modify reasoning traces in CoT via interaction with external knowledge, and thus overcome the hallucinations and error propagation. Concretely, we formulate the CoT rationale process of LLMs into a structured multi-round QA format. In each round, LLMs interact with a QA system that retrieves external knowledge and produce faithful reasoning traces based on retrieved precise answers. The structured CoT reasoning of LLMs is facilitated by our developed KBQA CoT collection, which serves as in-context learning demonstrations and can also be utilized as feedback augmentation to train a robust retriever. Extensive experiments on WebQSP and ComplexWebQuestion datasets demonstrate the effectiveness of proposed KD-CoT in task-solving reasoning generation, which outperforms the vanilla CoT ICL with an absolute success rate of 8.0% and 5.1%. Furthermore, our proposed feedback-augmented retriever outperforms the state-of-the-art baselines for retrieving knowledge, achieving significant improvement in Hit performance.
Transformer-Patcher: One Mistake worth One Neuron
Jan 24, 2023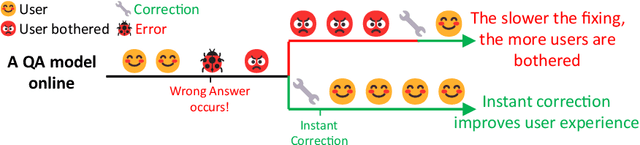
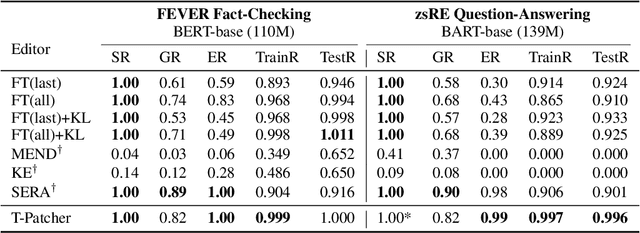
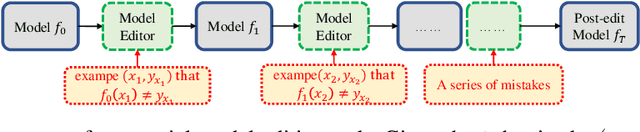
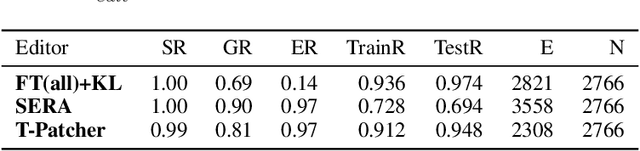
Large Transformer-based Pretrained Language Models (PLMs) dominate almost all Natural Language Processing (NLP) tasks. Nevertheless, they still make mistakes from time to time. For a model deployed in an industrial environment, fixing these mistakes quickly and robustly is vital to improve user experiences. Previous works formalize such problems as Model Editing (ME) and mostly focus on fixing one mistake. However, the one-mistake-fixing scenario is not an accurate abstraction of the real-world challenge. In the deployment of AI services, there are ever-emerging mistakes, and the same mistake may recur if not corrected in time. Thus a preferable solution is to rectify the mistakes as soon as they appear nonstop. Therefore, we extend the existing ME into Sequential Model Editing (SME) to help develop more practical editing methods. Our study shows that most current ME methods could yield unsatisfying results in this scenario. We then introduce Transformer-Patcher, a novel model editor that can shift the behavior of transformer-based models by simply adding and training a few neurons in the last Feed-Forward Network layer. Experimental results on both classification and generation tasks show that Transformer-Patcher can successively correct up to thousands of errors (Reliability) and generalize to their equivalent inputs (Generality) while retaining the model's accuracy on irrelevant inputs (Locality). Our method outperforms previous fine-tuning and HyperNetwork-based methods and achieves state-of-the-art performance for Sequential Model Editing (SME). The code is available at https://github.com/ZeroYuHuang/Transformer-Patcher.
Mixture of Attention Heads: Selecting Attention Heads Per Token
Oct 11, 2022
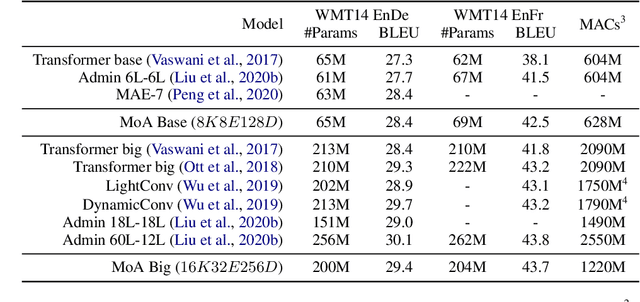
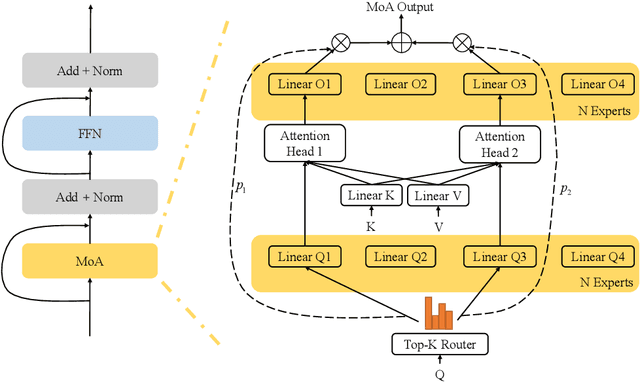
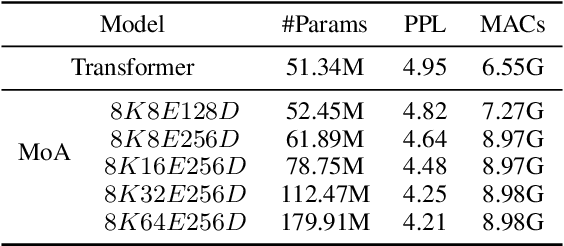
Mixture-of-Experts (MoE) networks have been proposed as an efficient way to scale up model capacity and implement conditional computing. However, the study of MoE components mostly focused on the feedforward layer in Transformer architecture. This paper proposes the Mixture of Attention Heads (MoA), a new architecture that combines multi-head attention with the MoE mechanism. MoA includes a set of attention heads that each has its own set of parameters. Given an input, a router dynamically selects a subset of $k$ attention heads per token. This conditional computation schema allows MoA to achieve stronger performance than the standard multi-head attention layer. Furthermore, the sparsely gated MoA can easily scale up the number of attention heads and the number of parameters while preserving computational efficiency. In addition to the performance improvements, MoA also automatically differentiates heads' utilities, providing a new perspective to discuss the model's interpretability. We conducted experiments on several important tasks, including Machine Translation and Masked Language Modeling. Experiments have shown promising results on several tasks against strong baselines that involve large and very deep models.
PREMA: Part-based REcurrent Multi-view Aggregation Network for 3D Shape Retrieval
Nov 09, 2021



We propose the Part-based Recurrent Multi-view Aggregation network(PREMA) to eliminate the detrimental effects of the practical view defects, such as insufficient view numbers, occlusions or background clutters, and also enhance the discriminative ability of shape representations. Inspired by the fact that human recognize an object mainly by its discriminant parts, we define the multi-view coherent part(MCP), a discriminant part reoccurring in different views. Our PREMA can reliably locate and effectively utilize MCPs to build robust shape representations. Comprehensively, we design a novel Regional Attention Unit(RAU) in PREMA to compute the confidence map for each view, and extract MCPs by applying those maps to view features. PREMA accentuates MCPs via correlating features of different views, and aggregates the part-aware features for shape representation.