 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHISR: Hindsight Information Modulated Segmental Process Rewards For Multi-turn Agentic Reinforcement Learning
Mar 19, 2026While large language models excel in diverse domains, their performance on complex longhorizon agentic decision-making tasks remains limited. Most existing methods concentrate on designing effective reward models (RMs) to advance performance via multi-turn reinforcement learning. However, they suffer from delayed propagation in sparse outcome rewards and unreliable credit assignment with potentially overly fine-grained and unfocused turnlevel process rewards. In this paper, we propose (HISR) exploiting Hindsight Information to modulate Segmental process Rewards, which closely aligns rewards with sub-goals and underscores significant segments to enhance the reliability of credit assignment. Specifically, a segment-level process RM is presented to assign rewards for each sub-goal in the task, avoiding excessively granular allocation to turns. To emphasize significant segments in the trajectory, a hindsight model is devised to reflect the preference of performing a certain action after knowing the trajectory outcome. With this characteristic, we design the ratios of sequence likelihoods between hindsight and policy model to measure action importance. The ratios are subsequently employed to aggregate segment importance scores, which in turn modulate segmental process rewards, enhancing credit assignment reliability. Extensive experimental results on three publicly benchmarks demonstrate the validity of our method.
LongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
Rectify Evaluation Preference: Improving LLMs' Critique on Math Reasoning via Perplexity-aware Reinforcement Learning
Nov 13, 2025To improve Multi-step Mathematical Reasoning (MsMR) of Large Language Models (LLMs), it is crucial to obtain scalable supervision from the corpus by automatically critiquing mistakes in the reasoning process of MsMR and rendering a final verdict of the problem-solution. Most existing methods rely on crafting high-quality supervised fine-tuning demonstrations for critiquing capability enhancement and pay little attention to delving into the underlying reason for the poor critiquing performance of LLMs. In this paper, we orthogonally quantify and investigate the potential reason -- imbalanced evaluation preference, and conduct a statistical preference analysis. Motivated by the analysis of the reason, a novel perplexity-aware reinforcement learning algorithm is proposed to rectify the evaluation preference, elevating the critiquing capability. Specifically, to probe into LLMs' critiquing characteristics, a One-to-many Problem-Solution (OPS) benchmark is meticulously constructed to quantify the behavior difference of LLMs when evaluating the problem solutions generated by itself and others. Then, to investigate the behavior difference in depth, we conduct a statistical preference analysis oriented on perplexity and find an intriguing phenomenon -- ``LLMs incline to judge solutions with lower perplexity as correct'', which is dubbed as \textit{imbalanced evaluation preference}. To rectify this preference, we regard perplexity as the baton in the algorithm of Group Relative Policy Optimization, supporting the LLMs to explore trajectories that judge lower perplexity as wrong and higher perplexity as correct. Extensive experimental results on our built OPS and existing available critic benchmarks demonstrate the validity of our method.
Feature-Aware Malicious Output Detection and Mitigation
Apr 12, 2025



The rapid advancement of large language models (LLMs) has brought significant benefits to various domains while introducing substantial risks. Despite being fine-tuned through reinforcement learning, LLMs lack the capability to discern malicious content, limiting their defense against jailbreak. To address these safety concerns, we propose a feature-aware method for harmful response rejection (FMM), which detects the presence of malicious features within the model's feature space and adaptively adjusts the model's rejection mechanism. By employing a simple discriminator, we detect potential malicious traits during the decoding phase. Upon detecting features indicative of toxic tokens, FMM regenerates the current token. By employing activation patching, an additional rejection vector is incorporated during the subsequent token generation, steering the model towards a refusal response. Experimental results demonstrate the effectiveness of our approach across multiple language models and diverse attack techniques, while crucially maintaining the models' standard generation capabilities.
Latent Distribution Decoupling: A Probabilistic Framework for Uncertainty-Aware Multimodal Emotion Recognition
Feb 19, 2025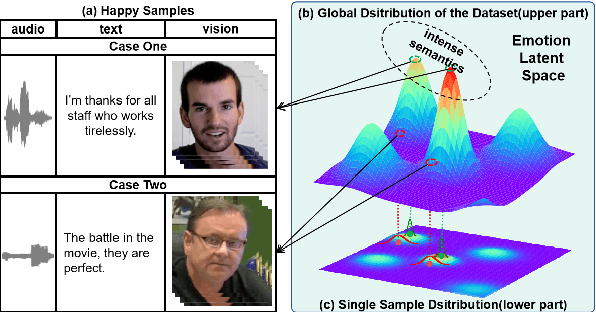
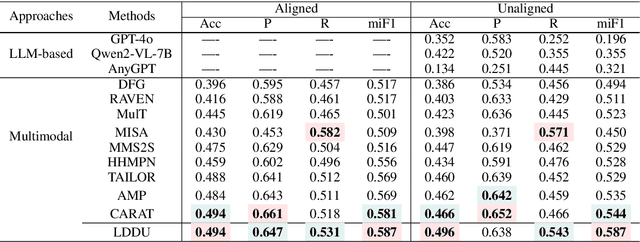
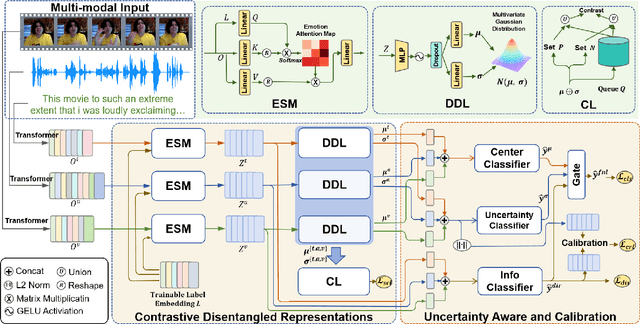
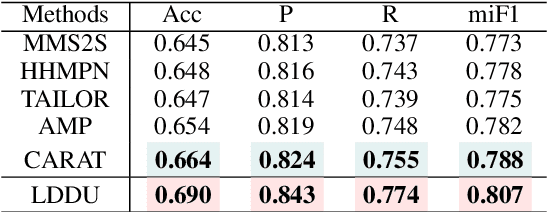
Multimodal multi-label emotion recognition (MMER) aims to identify the concurrent presence of multiple emotions in multimodal data. Existing studies primarily focus on improving fusion strategies and modeling modality-to-label dependencies. However, they often overlook the impact of \textbf{aleatoric uncertainty}, which is the inherent noise in the multimodal data and hinders the effectiveness of modality fusion by introducing ambiguity into feature representations. To address this issue and effectively model aleatoric uncertainty, this paper proposes Latent emotional Distribution Decomposition with Uncertainty perception (LDDU) framework from a novel perspective of latent emotional space probabilistic modeling. Specifically, we introduce a contrastive disentangled distribution mechanism within the emotion space to model the multimodal data, allowing for the extraction of semantic features and uncertainty. Furthermore, we design an uncertainty-aware fusion multimodal method that accounts for the dispersed distribution of uncertainty and integrates distribution information. Experimental results show that LDDU achieves state-of-the-art performance on the CMU-MOSEI and M$^3$ED datasets, highlighting the importance of uncertainty modeling in MMER. Code is available at https://github.com/201983290498/lddu\_mmer.git.
LLMs Know What They Need: Leveraging a Missing Information Guided Framework to Empower Retrieval-Augmented Generation
Apr 22, 2024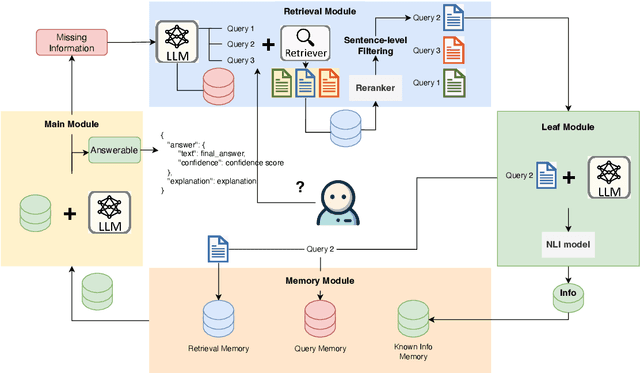
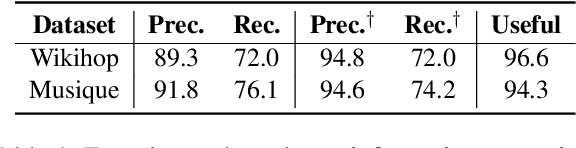
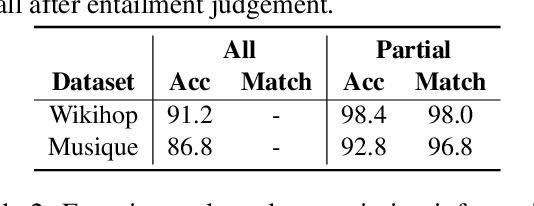
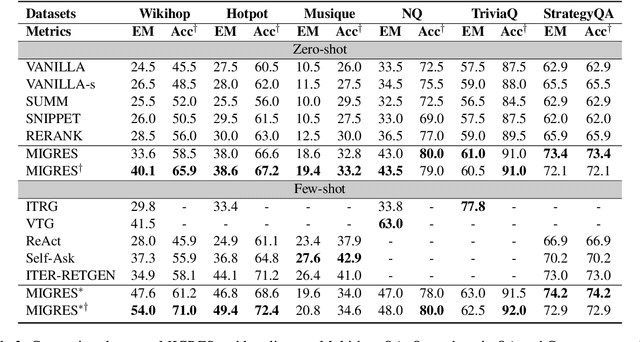
Retrieval-Augmented Generation (RAG) demonstrates great value in alleviating outdated knowledge or hallucination by supplying LLMs with updated and relevant knowledge. However, there are still several difficulties for RAG in understanding complex multi-hop query and retrieving relevant documents, which require LLMs to perform reasoning and retrieve step by step. Inspired by human's reasoning process in which they gradually search for the required information, it is natural to ask whether the LLMs could notice the missing information in each reasoning step. In this work, we first experimentally verified the ability of LLMs to extract information as well as to know the missing. Based on the above discovery, we propose a Missing Information Guided Retrieve-Extraction-Solving paradigm (MIGRES), where we leverage the identification of missing information to generate a targeted query that steers the subsequent knowledge retrieval. Besides, we design a sentence-level re-ranking filtering approach to filter the irrelevant content out from document, along with the information extraction capability of LLMs to extract useful information from cleaned-up documents, which in turn to bolster the overall efficacy of RAG. Extensive experiments conducted on multiple public datasets reveal the superiority of the proposed MIGRES method, and analytical experiments demonstrate the effectiveness of our proposed modules.
Beyond the Sequence: Statistics-Driven Pre-training for Stabilizing Sequential Recommendation Model
Apr 08, 2024The sequential recommendation task aims to predict the item that user is interested in according to his/her historical action sequence. However, inevitable random action, i.e. user randomly accesses an item among multiple candidates or clicks several items at random order, cause the sequence fails to provide stable and high-quality signals. To alleviate the issue, we propose the StatisTics-Driven Pre-traing framework (called STDP briefly). The main idea of the work lies in the exploration of utilizing the statistics information along with the pre-training paradigm to stabilize the optimization of recommendation model. Specifically, we derive two types of statistical information: item co-occurrence across sequence and attribute frequency within the sequence. And we design the following pre-training tasks: 1) The co-occurred items prediction task, which encourages the model to distribute its attention on multiple suitable targets instead of just focusing on the next item that may be unstable. 2) We generate a paired sequence by replacing items with their co-occurred items and enforce its representation close with the original one, thus enhancing the model's robustness to the random noise. 3) To reduce the impact of random on user's long-term preferences, we encourage the model to capture sequence-level frequent attributes. The significant improvement over six datasets demonstrates the effectiveness and superiority of the proposal, and further analysis verified the generalization of the STDP framework on other models.
Knowledge-Driven CoT: Exploring Faithful Reasoning in LLMs for Knowledge-intensive Question Answering
Aug 25, 2023



Equipped with Chain-of-Thought (CoT), Large language models (LLMs) have shown impressive reasoning ability in various downstream tasks. Even so, suffering from hallucinations and the inability to access external knowledge, LLMs often come with incorrect or unfaithful intermediate reasoning steps, especially in the context of answering knowledge-intensive tasks such as KBQA. To alleviate this issue, we propose a framework called Knowledge-Driven Chain-of-Thought (KD-CoT) to verify and modify reasoning traces in CoT via interaction with external knowledge, and thus overcome the hallucinations and error propagation. Concretely, we formulate the CoT rationale process of LLMs into a structured multi-round QA format. In each round, LLMs interact with a QA system that retrieves external knowledge and produce faithful reasoning traces based on retrieved precise answers. The structured CoT reasoning of LLMs is facilitated by our developed KBQA CoT collection, which serves as in-context learning demonstrations and can also be utilized as feedback augmentation to train a robust retriever. Extensive experiments on WebQSP and ComplexWebQuestion datasets demonstrate the effectiveness of proposed KD-CoT in task-solving reasoning generation, which outperforms the vanilla CoT ICL with an absolute success rate of 8.0% and 5.1%. Furthermore, our proposed feedback-augmented retriever outperforms the state-of-the-art baselines for retrieving knowledge, achieving significant improvement in Hit performance.