 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMe-Agent: A Personalized Mobile Agent with Two-Level User Habit Learning for Enhanced Interaction
Jan 28, 2026Large Language Model (LLM)-based mobile agents have made significant performance advancements. However, these agents often follow explicit user instructions while overlooking personalized needs, leading to significant limitations for real users, particularly without personalized context: (1) inability to interpret ambiguous instructions, (2) lack of learning from user interaction history, and (3) failure to handle personalized instructions. To alleviate the above challenges, we propose Me-Agent, a learnable and memorable personalized mobile agent. Specifically, Me-Agent incorporates a two-level user habit learning approach. At the prompt level, we design a user preference learning strategy enhanced with a Personal Reward Model to improve personalization performance. At the memory level, we design a Hierarchical Preference Memory, which stores users' long-term memory and app-specific memory in different level memory. To validate the personalization capabilities of mobile agents, we introduce User FingerTip, a new benchmark featuring numerous ambiguous instructions for daily life. Extensive experiments on User FingerTip and general benchmarks demonstrate that Me-Agent achieves state-of-the-art performance in personalization while maintaining competitive instruction execution performance.
DiffER: Diffusion Entity-Relation Modeling for Reversal Curse in Diffusion Large Language Models
Jan 12, 2026The "reversal curse" refers to the phenomenon where large language models (LLMs) exhibit predominantly unidirectional behavior when processing logically bidirectional relationships. Prior work attributed this to autoregressive training -- predicting the next token inherently favors left-to-right information flow over genuine bidirectional knowledge associations. However, we observe that Diffusion LLMs (DLLMs), despite being trained bidirectionally, also suffer from the reversal curse. To investigate the root causes, we conduct systematic experiments on DLLMs and identify three key reasons: 1) entity fragmentation during training, 2) data asymmetry, and 3) missing entity relations. Motivated by the analysis of these reasons, we propose Diffusion Entity-Relation Modeling (DiffER), which addresses the reversal curse through entity-aware training and balanced data construction. Specifically, DiffER introduces whole-entity masking, which mitigates entity fragmentation by predicting complete entities in a single step. DiffER further employs distribution-symmetric and relation-enhanced data construction strategies to alleviate data asymmetry and missing relations. Extensive experiments demonstrate that DiffER effectively alleviates the reversal curse in Diffusion LLMs, offering new perspectives for future research.
Rethinking the Reliability of Multi-agent System: A Perspective from Byzantine Fault Tolerance
Nov 13, 2025Ensuring the reliability of agent architectures and effectively identifying problematic agents when failures occur are crucial challenges in multi-agent systems (MAS). Advances in large language models (LLMs) have established LLM-based agents as a major branch of MAS, enabling major breakthroughs in complex problem solving and world modeling. However, the reliability implications of this shift remain largely unexplored. i.e., whether substituting traditional agents with LLM-based agents can effectively enhance the reliability of MAS. In this work, we investigate and quantify the reliability of LLM-based agents from the perspective of Byzantine fault tolerance. We observe that LLM-based agents demonstrate stronger skepticism when processing erroneous message flows, a characteristic that enables them to outperform traditional agents across different topological structures. Motivated by the results of the pilot experiment, we design CP-WBFT, a confidence probe-based weighted Byzantine Fault Tolerant consensus mechanism to enhance the stability of MAS with different topologies. It capitalizes on the intrinsic reflective and discriminative capabilities of LLMs by employing a probe-based, weighted information flow transmission method to improve the reliability of LLM-based agents. Extensive experiments demonstrate that CP-WBFT achieves superior performance across diverse network topologies under extreme Byzantine conditions (85.7\% fault rate). Notably, our approach surpasses traditional methods by attaining remarkable accuracy on various topologies and maintaining strong reliability in both mathematical reasoning and safety assessment tasks.
Feature-Aware Malicious Output Detection and Mitigation
Apr 12, 2025



The rapid advancement of large language models (LLMs) has brought significant benefits to various domains while introducing substantial risks. Despite being fine-tuned through reinforcement learning, LLMs lack the capability to discern malicious content, limiting their defense against jailbreak. To address these safety concerns, we propose a feature-aware method for harmful response rejection (FMM), which detects the presence of malicious features within the model's feature space and adaptively adjusts the model's rejection mechanism. By employing a simple discriminator, we detect potential malicious traits during the decoding phase. Upon detecting features indicative of toxic tokens, FMM regenerates the current token. By employing activation patching, an additional rejection vector is incorporated during the subsequent token generation, steering the model towards a refusal response. Experimental results demonstrate the effectiveness of our approach across multiple language models and diverse attack techniques, while crucially maintaining the models' standard generation capabilities.
From Pixels to Tokens: Revisiting Object Hallucinations in Large Vision-Language Models
Oct 09, 2024



Hallucinations in large vision-language models (LVLMs) are a significant challenge, i.e., generating objects that are not presented in the visual input, which impairs their reliability. Recent studies often attribute hallucinations to a lack of understanding of visual input, yet ignore a more fundamental issue: the model's inability to effectively extract or decouple visual features. In this paper, we revisit the hallucinations in LVLMs from an architectural perspective, investigating whether the primary cause lies in the visual encoder (feature extraction) or the modal alignment module (feature decoupling). Motivated by our findings on the preliminary investigation, we propose a novel tuning strategy, PATCH, to mitigate hallucinations in LVLMs. This plug-and-play method can be integrated into various LVLMs, utilizing adaptive virtual tokens to extract object features from bounding boxes, thereby addressing hallucinations caused by insufficient decoupling of visual features. PATCH achieves state-of-the-art performance on multiple multi-modal hallucination datasets. We hope this approach provides researchers with deeper insights into the underlying causes of hallucinations in LVLMs, fostering further advancements and innovation in this field.
Root Defence Strategies: Ensuring Safety of LLM at the Decoding Level
Oct 09, 2024Large language models (LLMs) have demonstrated immense utility across various industries. However, as LLMs advance, the risk of harmful outputs increases due to incorrect or malicious instruction prompts. While current methods effectively address jailbreak risks, they share common limitations: 1) Judging harmful responses from the prefill-level lacks utilization of the model's decoding outputs, leading to relatively lower effectiveness and robustness. 2) Rejecting potentially harmful responses based on a single evaluation can significantly impair the model's helpfulness.This paper examines the LLMs' capability to recognize harmful outputs, revealing and quantifying their proficiency in assessing the danger of previous tokens. Motivated by pilot experiment results, we design a robust defense mechanism at the decoding level. Our novel decoder-oriented, step-by-step defense architecture corrects harmful queries directly rather than rejecting them outright. We introduce speculative decoding to enhance usability and facilitate deployment to boost secure decoding speed. Extensive experiments demonstrate that our approach improves model security without compromising reasoning speed. Notably, our method leverages the model's ability to discern hazardous information, maintaining its helpfulness compared to existing methods.
YanTian: An Application Platform for AI Global Weather Forecasting Models
Oct 06, 2024



To promote the practical application of AI Global Weather Forecasting Models (AIGWFM), we have developed an adaptable application platform named 'YanTian'. This platform enhances existing open-source AIGWFM with a suite of capability-enhancing modules and is constructed by a "loosely coupled" plug-in architecture. The goal of 'YanTian' is to address the limitations of current open-source AIGWFM in operational application, including improving local forecast accuracy, providing spatial high-resolution forecasts, increasing density of forecast intervals, and generating diverse products with the provision of AIGC capabilities. 'YianTian' also provides a simple, visualized user interface, allowing meteorologists easily access both basic and extended capabilities of the platform by simply configuring the platform UI. Users do not need to possess the complex artificial intelligence knowledge and the coding techniques. Additionally, 'YianTian' can be deployed on a PC with GPUs. We hope 'YianTian' can facilitate the operational widespread adoption of AIGWFMs.
BTMuda: A Bi-level Multi-source unsupervised domain adaptation framework for breast cancer diagnosis
Aug 30, 2024Deep learning has revolutionized the early detection of breast cancer, resulting in a significant decrease in mortality rates. However, difficulties in obtaining annotations and huge variations in distribution between training sets and real scenes have limited their clinical applications. To address these limitations, unsupervised domain adaptation (UDA) methods have been used to transfer knowledge from one labeled source domain to the unlabeled target domain, yet these approaches suffer from severe domain shift issues and often ignore the potential benefits of leveraging multiple relevant sources in practical applications. To address these limitations, in this work, we construct a Three-Branch Mixed extractor and propose a Bi-level Multi-source unsupervised domain adaptation method called BTMuda for breast cancer diagnosis. Our method addresses the problems of domain shift by dividing domain shift issues into two levels: intra-domain and inter-domain. To reduce the intra-domain shift, we jointly train a CNN and a Transformer as two paths of a domain mixed feature extractor to obtain robust representations rich in both low-level local and high-level global information. As for the inter-domain shift, we redesign the Transformer delicately to a three-branch architecture with cross-attention and distillation, which learns domain-invariant representations from multiple domains. Besides, we introduce two alignment modules - one for feature alignment and one for classifier alignment - to improve the alignment process. Extensive experiments conducted on three public mammographic datasets demonstrate that our BTMuda outperforms state-of-the-art methods.
Learning with Alignments: Tackling the Inter- and Intra-domain Shifts for Cross-multidomain Facial Expression Recognition
Jul 08, 2024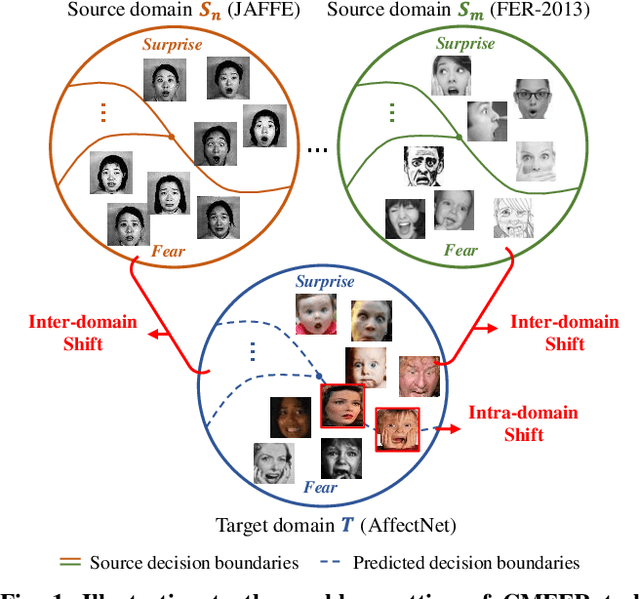

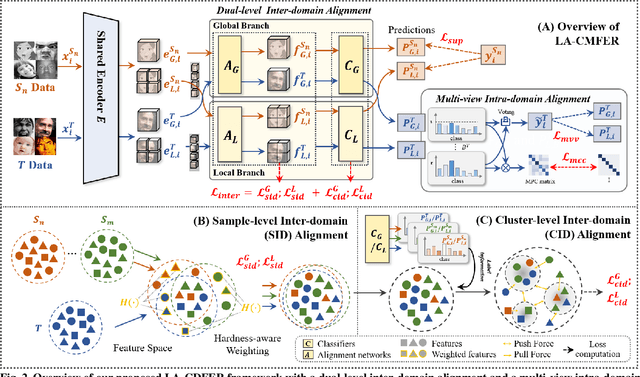
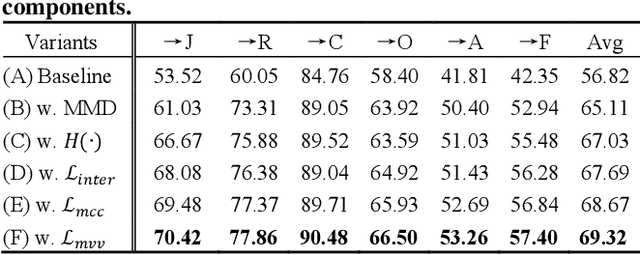
Facial Expression Recognition (FER) holds significant importance in human-computer interactions. Existing cross-domain FER methods often transfer knowledge solely from a single labeled source domain to an unlabeled target domain, neglecting the comprehensive information across multiple sources. Nevertheless, cross-multidomain FER (CMFER) is very challenging for (i) the inherent inter-domain shifts across multiple domains and (ii) the intra-domain shifts stemming from the ambiguous expressions and low inter-class distinctions. In this paper, we propose a novel Learning with Alignments CMFER framework, named LA-CMFER, to handle both inter- and intra-domain shifts. Specifically, LA-CMFER is constructed with a global branch and a local branch to extract features from the full images and local subtle expressions, respectively. Based on this, LA-CMFER presents a dual-level inter-domain alignment method to force the model to prioritize hard-to-align samples in knowledge transfer at a sample level while gradually generating a well-clustered feature space with the guidance of class attributes at a cluster level, thus narrowing the inter-domain shifts. To address the intra-domain shifts, LA-CMFER introduces a multi-view intra-domain alignment method with a multi-view clustering consistency constraint where a prediction similarity matrix is built to pursue consistency between the global and local views, thus refining pseudo labels and eliminating latent noise. Extensive experiments on six benchmark datasets have validated the superiority of our LA-CMFER.
MCAD: Multi-modal Conditioned Adversarial Diffusion Model for High-Quality PET Image Reconstruction
Jun 19, 2024Radiation hazards associated with standard-dose positron emission tomography (SPET) images remain a concern, whereas the quality of low-dose PET (LPET) images fails to meet clinical requirements. Therefore, there is great interest in reconstructing SPET images from LPET images. However, prior studies focus solely on image data, neglecting vital complementary information from other modalities, e.g., patients' clinical tabular, resulting in compromised reconstruction with limited diagnostic utility. Moreover, they often overlook the semantic consistency between real SPET and reconstructed images, leading to distorted semantic contexts. To tackle these problems, we propose a novel Multi-modal Conditioned Adversarial Diffusion model (MCAD) to reconstruct SPET images from multi-modal inputs, including LPET images and clinical tabular. Specifically, our MCAD incorporates a Multi-modal conditional Encoder (Mc-Encoder) to extract multi-modal features, followed by a conditional diffusion process to blend noise with multi-modal features and gradually map blended features to the target SPET images. To balance multi-modal inputs, the Mc-Encoder embeds Optimal Multi-modal Transport co-Attention (OMTA) to narrow the heterogeneity gap between image and tabular while capturing their interactions, providing sufficient guidance for reconstruction. In addition, to mitigate semantic distortions, we introduce the Multi-Modal Masked Text Reconstruction (M3TRec), which leverages semantic knowledge extracted from denoised PET images to restore the masked clinical tabular, thereby compelling the network to maintain accurate semantics during reconstruction. To expedite the diffusion process, we further introduce an adversarial diffusive network with a reduced number of diffusion steps. Experiments show that our method achieves the state-of-the-art performance both qualitatively and quantitatively.