 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYanTian: An Application Platform for AI Global Weather Forecasting Models
Oct 06, 2024



To promote the practical application of AI Global Weather Forecasting Models (AIGWFM), we have developed an adaptable application platform named 'YanTian'. This platform enhances existing open-source AIGWFM with a suite of capability-enhancing modules and is constructed by a "loosely coupled" plug-in architecture. The goal of 'YanTian' is to address the limitations of current open-source AIGWFM in operational application, including improving local forecast accuracy, providing spatial high-resolution forecasts, increasing density of forecast intervals, and generating diverse products with the provision of AIGC capabilities. 'YianTian' also provides a simple, visualized user interface, allowing meteorologists easily access both basic and extended capabilities of the platform by simply configuring the platform UI. Users do not need to possess the complex artificial intelligence knowledge and the coding techniques. Additionally, 'YianTian' can be deployed on a PC with GPUs. We hope 'YianTian' can facilitate the operational widespread adoption of AIGWFMs.
The Compatibility between the Pangu Weather Forecasting Model and Meteorological Operational Data
Aug 07, 2023



Recently, multiple data-driven models based on machine learning for weather forecasting have emerged. These models are highly competitive in terms of accuracy compared to traditional numerical weather prediction (NWP) systems. In particular, the Pangu-Weather model, which is open source for non-commercial use, has been validated for its forecasting performance by the European Centre for Medium-Range Weather Forecasts (ECMWF) and has recently been published in the journal "Nature". In this paper, we evaluate the compatibility of the Pangu-Weather model with several commonly used NWP operational analyses through case studies. The results indicate that the Pangu-Weather model is compatible with different operational analyses from various NWP systems as the model initial conditions, and it exhibits a relatively stable forecasting capability. Furthermore, we have verified that improving the quality of global or local initial conditions significantly contributes to enhancing the forecasting performance of the Pangu-Weather model.
Compound Figure Separation of Biomedical Images: Mining Large Datasets for Self-supervised Learning
Aug 30, 2022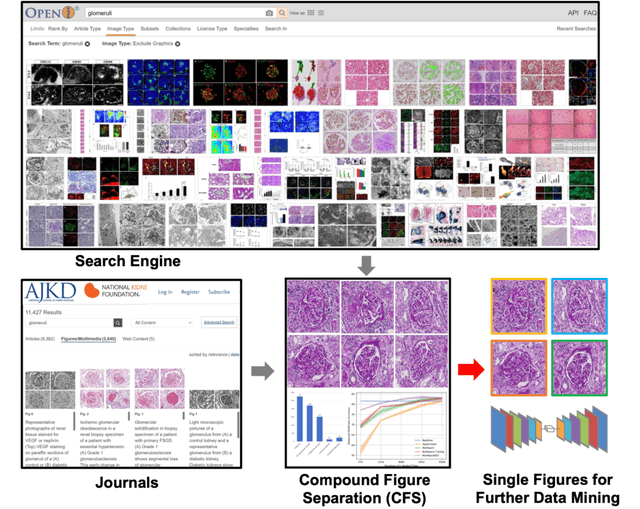
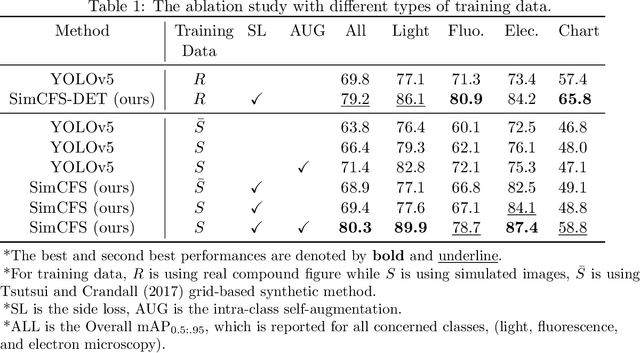
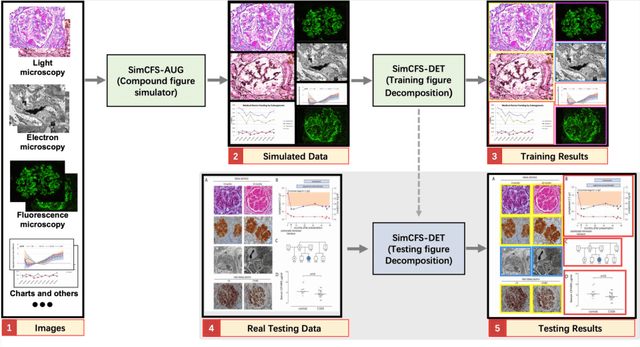
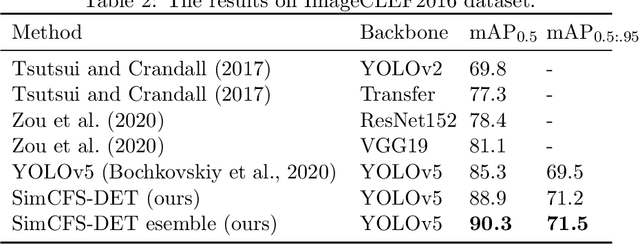
With the rapid development of self-supervised learning (e.g., contrastive learning), the importance of having large-scale images (even without annotations) for training a more generalizable AI model has been widely recognized in medical image analysis. However, collecting large-scale task-specific unannotated data at scale can be challenging for individual labs. Existing online resources, such as digital books, publications, and search engines, provide a new resource for obtaining large-scale images. However, published images in healthcare (e.g., radiology and pathology) consist of a considerable amount of compound figures with subplots. In order to extract and separate compound figures into usable individual images for downstream learning, we propose a simple compound figure separation (SimCFS) framework without using the traditionally required detection bounding box annotations, with a new loss function and a hard case simulation. Our technical contribution is four-fold: (1) we introduce a simulation-based training framework that minimizes the need for resource extensive bounding box annotations; (2) we propose a new side loss that is optimized for compound figure separation; (3) we propose an intra-class image augmentation method to simulate hard cases; and (4) to the best of our knowledge, this is the first study that evaluates the efficacy of leveraging self-supervised learning with compound image separation. From the results, the proposed SimCFS achieved state-of-the-art performance on the ImageCLEF 2016 Compound Figure Separation Database. The pretrained self-supervised learning model using large-scale mined figures improved the accuracy of downstream image classification tasks with a contrastive learning algorithm. The source code of SimCFS is made publicly available at https://github.com/hrlblab/ImageSeperation.
* Accepted for publication at the Journal of Machine Learning for Biomedical Imaging (MELBA) https://www.melba-journal.org/papers/2022:025.html. arXiv admin note: substantial text overlap with arXiv:2107.08650
Compound Figure Separation of Biomedical Images with Side Loss
Jul 19, 2021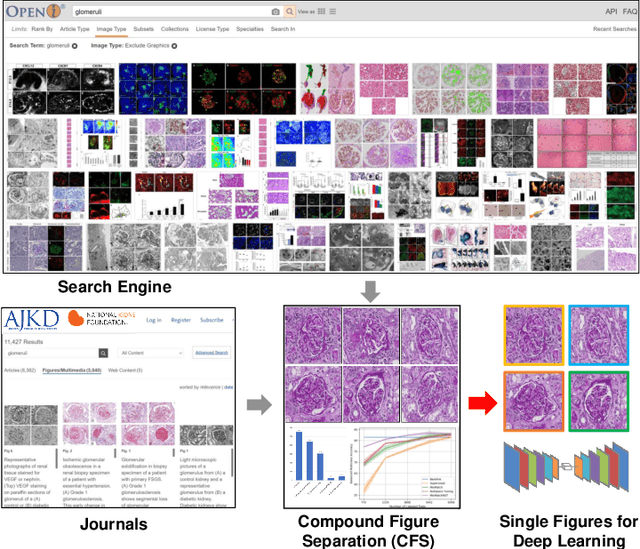
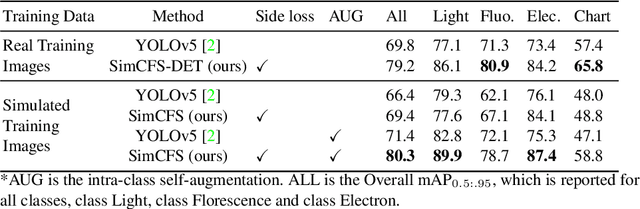
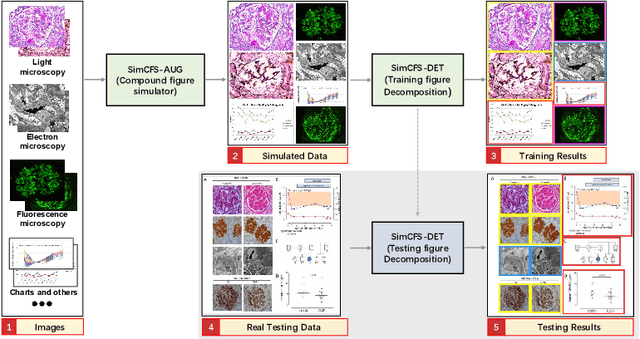

Unsupervised learning algorithms (e.g., self-supervised learning, auto-encoder, contrastive learning) allow deep learning models to learn effective image representations from large-scale unlabeled data. In medical image analysis, even unannotated data can be difficult to obtain for individual labs. Fortunately, national-level efforts have been made to provide efficient access to obtain biomedical image data from previous scientific publications. For instance, NIH has launched the Open-i search engine that provides a large-scale image database with free access. However, the images in scientific publications consist of a considerable amount of compound figures with subplots. To extract and curate individual subplots, many different compound figure separation approaches have been developed, especially with the recent advances in deep learning. However, previous approaches typically required resource extensive bounding box annotation to train detection models. In this paper, we propose a simple compound figure separation (SimCFS) framework that uses weak classification annotations from individual images. Our technical contribution is three-fold: (1) we introduce a new side loss that is designed for compound figure separation; (2) we introduce an intra-class image augmentation method to simulate hard cases; (3) the proposed framework enables an efficient deployment to new classes of images, without requiring resource extensive bounding box annotations. From the results, the SimCFS achieved a new state-of-the-art performance on the ImageCLEF 2016 Compound Figure Separation Database. The source code of SimCFS is made publicly available at https://github.com/hrlblab/ImageSeperation.