 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArchitectural Co-Design for Zero-Shot Anomaly Detection: Decoupling Representation and Dynamically Fusing Features in CLIP
Aug 11, 2025Pre-trained Vision-Language Models (VLMs) face a significant adaptation gap when applied to Zero-Shot Anomaly Detection (ZSAD), stemming from their lack of local inductive biases for dense prediction and their reliance on inflexible feature fusion paradigms. We address these limitations through an Architectural Co-Design framework that jointly refines feature representation and cross-modal fusion. Our method integrates a parameter-efficient Convolutional Low-Rank Adaptation (Conv-LoRA) adapter to inject local inductive biases for fine-grained representation, and introduces a Dynamic Fusion Gateway (DFG) that leverages visual context to adaptively modulate text prompts, enabling a powerful bidirectional fusion. Extensive experiments on diverse industrial and medical benchmarks demonstrate superior accuracy and robustness, validating that this synergistic co-design is critical for robustly adapting foundation models to dense perception tasks.
Seed1.5-VL Technical Report
May 11, 2025



We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research. Seed1.5-VL is now accessible at https://www.volcengine.com/ (Volcano Engine Model ID: doubao-1-5-thinking-vision-pro-250428)
HiFuse: Hierarchical Multi-Scale Feature Fusion Network for Medical Image Classification
Sep 21, 2022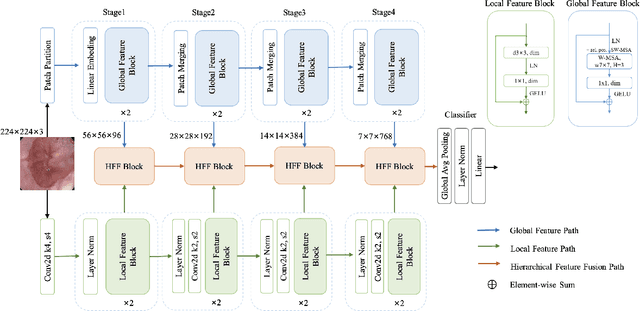
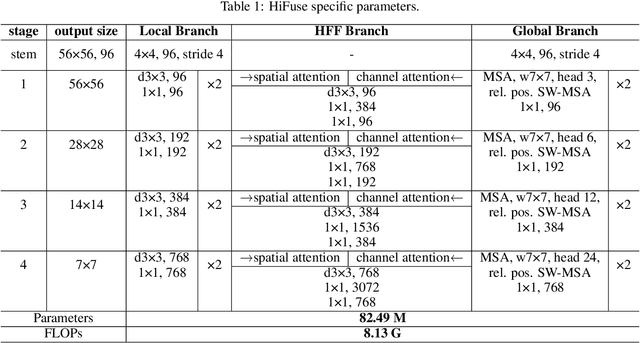
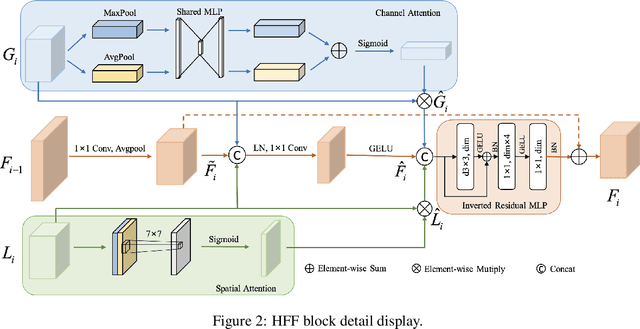
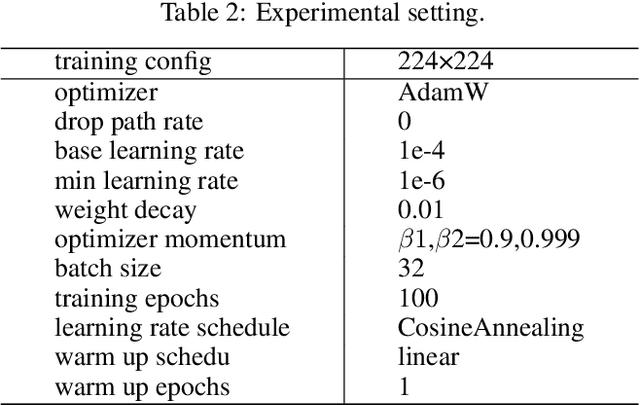
Medical image classification has developed rapidly under the impetus of the convolutional neural network (CNN). Due to the fixed size of the receptive field of the convolution kernel, it is difficult to capture the global features of medical images. Although the self-attention-based Transformer can model long-range dependencies, it has high computational complexity and lacks local inductive bias. Much research has demonstrated that global and local features are crucial for image classification. However, medical images have a lot of noisy, scattered features, intra-class variation, and inter-class similarities. This paper proposes a three-branch hierarchical multi-scale feature fusion network structure termed as HiFuse for medical image classification as a new method. It can fuse the advantages of Transformer and CNN from multi-scale hierarchies without destroying the respective modeling so as to improve the classification accuracy of various medical images. A parallel hierarchy of local and global feature blocks is designed to efficiently extract local features and global representations at various semantic scales, with the flexibility to model at different scales and linear computational complexity relevant to image size. Moreover, an adaptive hierarchical feature fusion block (HFF block) is designed to utilize the features obtained at different hierarchical levels comprehensively. The HFF block contains spatial attention, channel attention, residual inverted MLP, and shortcut to adaptively fuse semantic information between various scale features of each branch. The accuracy of our proposed model on the ISIC2018 dataset is 7.6% higher than baseline, 21.5% on the Covid-19 dataset, and 10.4% on the Kvasir dataset. Compared with other advanced models, the HiFuse model performs the best. Our code is open-source and available from https://github.com/huoxiangzuo/HiFuse.
Compound Figure Separation of Biomedical Images: Mining Large Datasets for Self-supervised Learning
Aug 30, 2022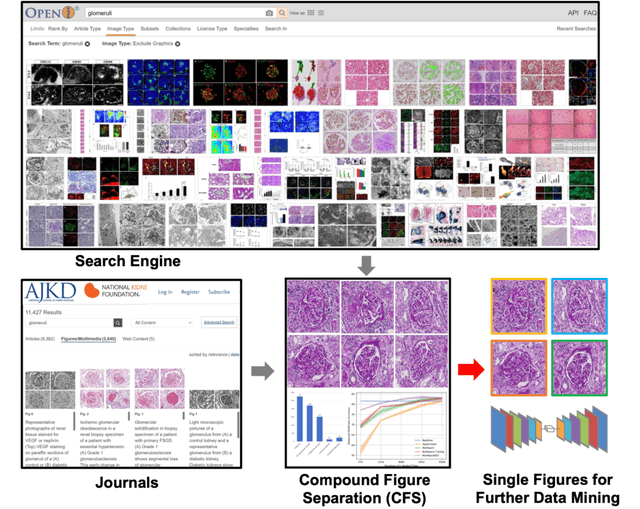
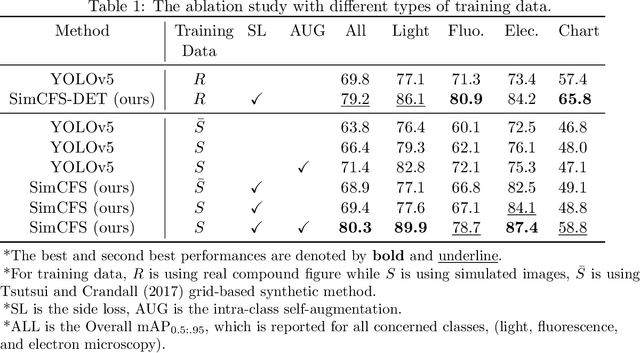
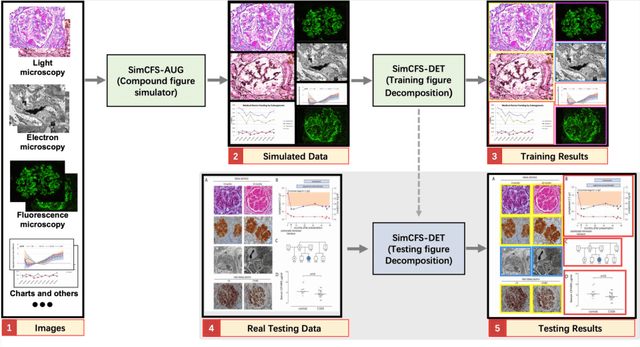
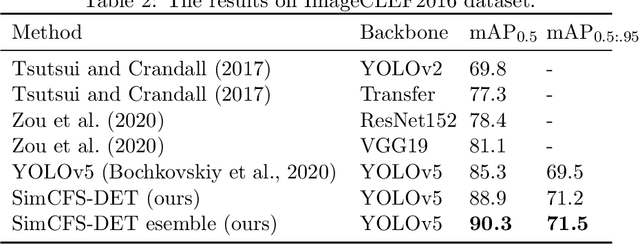
With the rapid development of self-supervised learning (e.g., contrastive learning), the importance of having large-scale images (even without annotations) for training a more generalizable AI model has been widely recognized in medical image analysis. However, collecting large-scale task-specific unannotated data at scale can be challenging for individual labs. Existing online resources, such as digital books, publications, and search engines, provide a new resource for obtaining large-scale images. However, published images in healthcare (e.g., radiology and pathology) consist of a considerable amount of compound figures with subplots. In order to extract and separate compound figures into usable individual images for downstream learning, we propose a simple compound figure separation (SimCFS) framework without using the traditionally required detection bounding box annotations, with a new loss function and a hard case simulation. Our technical contribution is four-fold: (1) we introduce a simulation-based training framework that minimizes the need for resource extensive bounding box annotations; (2) we propose a new side loss that is optimized for compound figure separation; (3) we propose an intra-class image augmentation method to simulate hard cases; and (4) to the best of our knowledge, this is the first study that evaluates the efficacy of leveraging self-supervised learning with compound image separation. From the results, the proposed SimCFS achieved state-of-the-art performance on the ImageCLEF 2016 Compound Figure Separation Database. The pretrained self-supervised learning model using large-scale mined figures improved the accuracy of downstream image classification tasks with a contrastive learning algorithm. The source code of SimCFS is made publicly available at https://github.com/hrlblab/ImageSeperation.
* Accepted for publication at the Journal of Machine Learning for Biomedical Imaging (MELBA) https://www.melba-journal.org/papers/2022:025.html. arXiv admin note: substantial text overlap with arXiv:2107.08650
Omni-Seg+: A Scale-aware Dynamic Network for Pathological Image Segmentation
Jun 27, 2022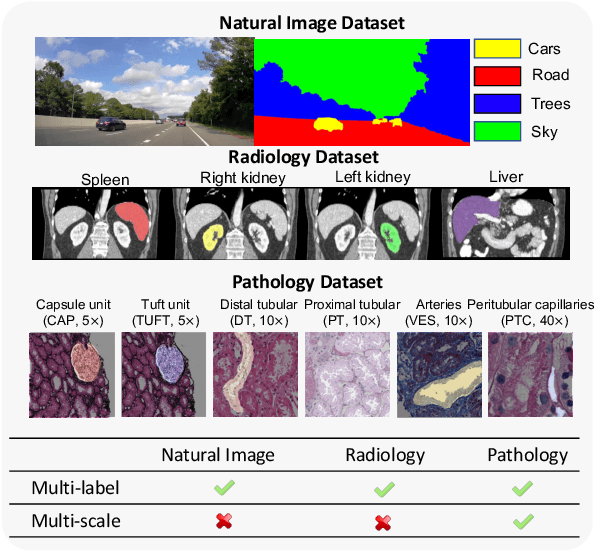
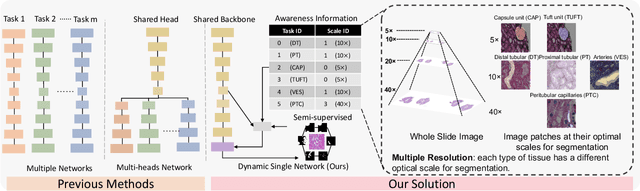
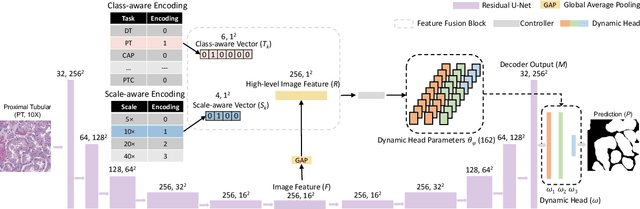
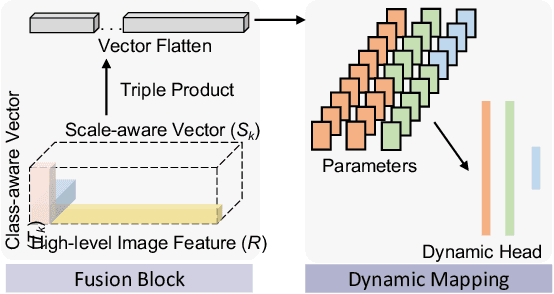
Comprehensive semantic segmentation on renal pathological images is challenging due to the heterogeneous scales of the objects. For example, on a whole slide image (WSI), the cross-sectional areas of glomeruli can be 64 times larger than that of the peritubular capillaries, making it impractical to segment both objects on the same patch, at the same scale. To handle this scaling issue, prior studies have typically trained multiple segmentation networks in order to match the optimal pixel resolution of heterogeneous tissue types. This multi-network solution is resource-intensive and fails to model the spatial relationship between tissue types. In this paper, we propose the Omni-Seg+ network, a scale-aware dynamic neural network that achieves multi-object (six tissue types) and multi-scale (5X to 40X scale) pathological image segmentation via a single neural network. The contribution of this paper is three-fold: (1) a novel scale-aware controller is proposed to generalize the dynamic neural network from single-scale to multi-scale; (2) semi-supervised consistency regularization of pseudo-labels is introduced to model the inter-scale correlation of unannotated tissue types into a single end-to-end learning paradigm; and (3) superior scale-aware generalization is evidenced by directly applying a model trained on human kidney images to mouse kidney images, without retraining. By learning from ~150,000 human pathological image patches from six tissue types at three different resolutions, our approach achieved superior segmentation performance according to human visual assessment and evaluation of image-omics (i.e., spatial transcriptomics). The official implementation is available at https://github.com/ddrrnn123/Omni-Seg.
Glo-In-One: Holistic Glomerular Detection, Segmentation, and Lesion Characterization with Large-scale Web Image Mining
May 31, 2022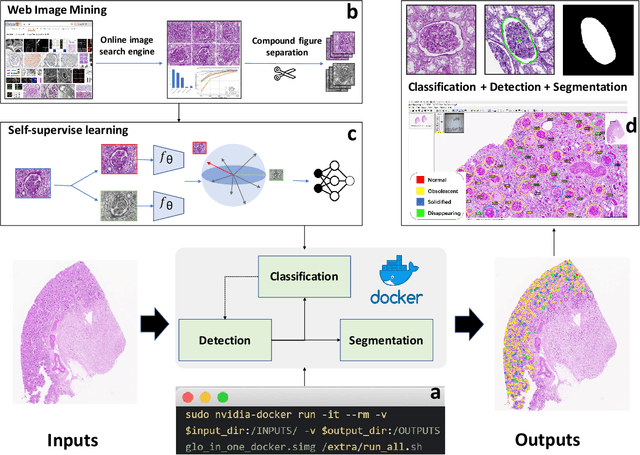
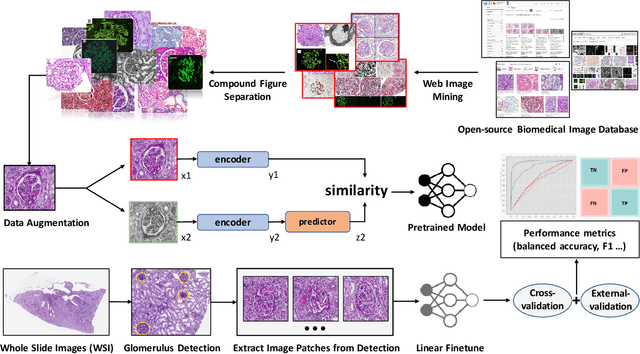
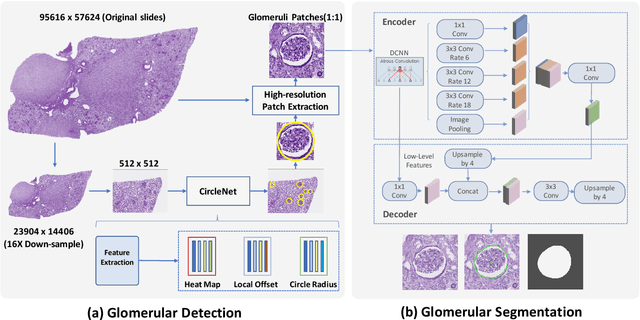
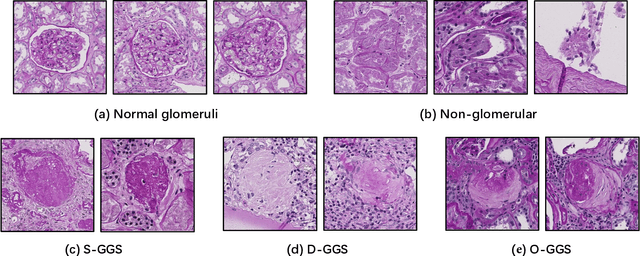
The quantitative detection, segmentation, and characterization of glomeruli from high-resolution whole slide imaging (WSI) play essential roles in the computer-assisted diagnosis and scientific research in digital renal pathology. Historically, such comprehensive quantification requires extensive programming skills in order to be able to handle heterogeneous and customized computational tools. To bridge the gap of performing glomerular quantification for non-technical users, we develop the Glo-In-One toolkit to achieve holistic glomerular detection, segmentation, and characterization via a single line of command. Additionally, we release a large-scale collection of 30,000 unlabeled glomerular images to further facilitate the algorithmic development of self-supervised deep learning. The inputs of the Glo-In-One toolkit are WSIs, while the outputs are (1) WSI-level multi-class circle glomerular detection results (which can be directly manipulated with ImageScope), (2) glomerular image patches with segmentation masks, and (3) different lesion types. To leverage the performance of the Glo-In-One toolkit, we introduce self-supervised deep learning to glomerular quantification via large-scale web image mining. The GGS fine-grained classification model achieved a decent performance compared with baseline supervised methods while only using 10% of the annotated data. The glomerular detection achieved an average precision of 0.627 with circle representations, while the glomerular segmentation achieved a 0.955 patch-wise Dice Similarity Coefficient (DSC).
Multi-object Tracking with a Hierarchical Single-branch Network
Jan 06, 2021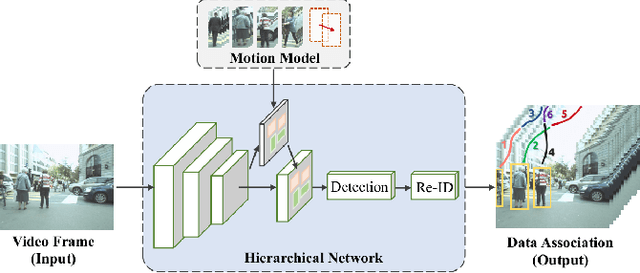
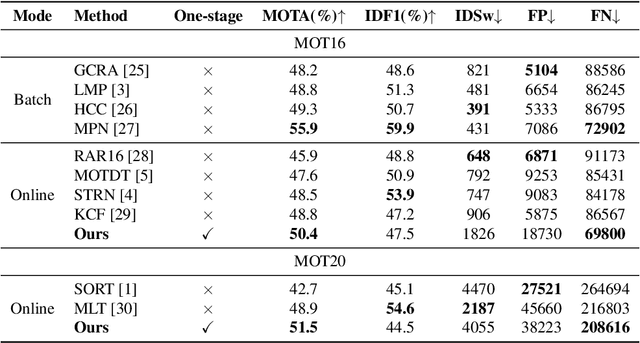
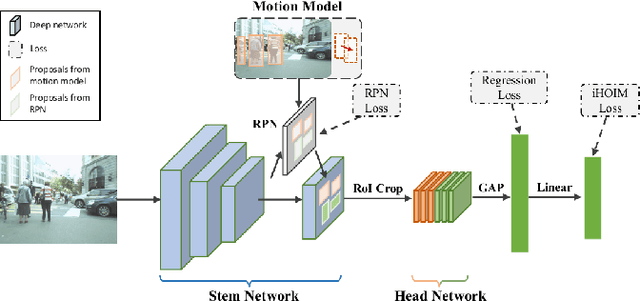

Recent Multiple Object Tracking (MOT) methods have gradually attempted to integrate object detection and instance re-identification (Re-ID) into a united network to form a one-stage solution. Typically, these methods use two separated branches within a single network to accomplish detection and Re-ID respectively without studying the inter-relationship between them, which inevitably impedes the tracking performance. In this paper, we propose an online multi-object tracking framework based on a hierarchical single-branch network to solve this problem. Specifically, the proposed single-branch network utilizes an improved Hierarchical Online In-stance Matching (iHOIM) loss to explicitly model the inter-relationship between object detection and Re-ID. Our novel iHOIM loss function unifies the objectives of the two sub-tasks and encourages better detection performance and feature learning even in extremely crowded scenes. Moreover, we propose to introduce the object positions, predicted by a motion model, as region proposals for subsequent object detection, where the intuition is that detection results and motion predictions can complement each other in different scenarios. Experimental results on MOT16 and MOT20 datasets show that we can achieve state-of-the-art tracking performance, and the ablation study verifies the effectiveness of each proposed component.
Asymmetric Deep Semantic Quantization for Image Retrieval
Mar 29, 2019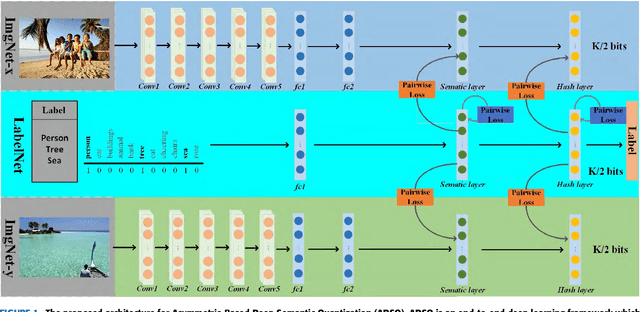
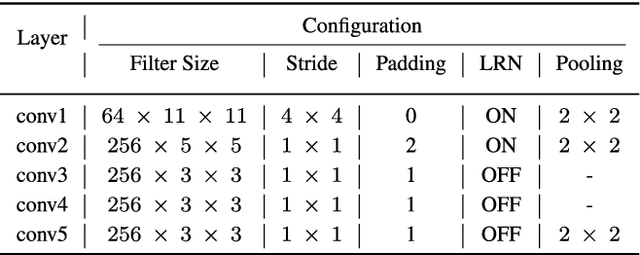

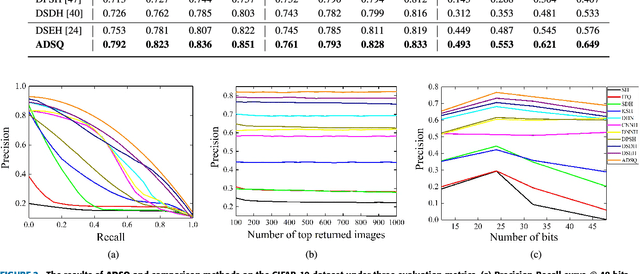
Due to its fast retrieval and storage efficiency capabilities, hashing has been widely used in nearest neighbor retrieval tasks. By using deep learning based techniques, hashing can outperform non-learning based hashing in many applications. However, there are some limitations to previous learning based hashing methods (e.g., the learned hash codes are not discriminative due to the hashing methods being unable to discover rich semantic information and the training strategy having difficulty optimizing the discrete binary codes). In this paper, we propose a novel learning based hashing method, named \textbf{\underline{A}}symmetric \textbf{\underline{D}}eep \textbf{\underline{S}}emantic \textbf{\underline{Q}}uantization (\textbf{ADSQ}). \textbf{ADSQ} is implemented using three stream frameworks, which consists of one \emph{LabelNet} and two \emph{ImgNets}. The \emph{LabelNet} leverages three fully-connected layers, which is used to capture rich semantic information between image pairs. For the two \emph{ImgNets}, they each adopt the same convolutional neural network structure, but with different weights (i.e., asymmetric convolutional neural networks). The two \emph{ImgNets} are used to generate discriminative compact hash codes. Specifically, the function of the \emph{LabelNet} is to capture rich semantic information that is used to guide the two \emph{ImgNets} in minimizing the gap between the real-continuous features and discrete binary codes. By doing this, \textbf{ADSQ} can make full use of the most critical semantic information to guide the feature learning process and consider the consistency of the common semantic space and Hamming space. Results from our experiments demonstrate that \textbf{ADSQ} can generate high discriminative compact hash codes and it outperforms current state-of-the-art methods on three benchmark datasets, CIFAR-10, NUS-WIDE, and ImageNet.
Dual Residual Network for Accurate Human Activity Recognition
Mar 13, 2019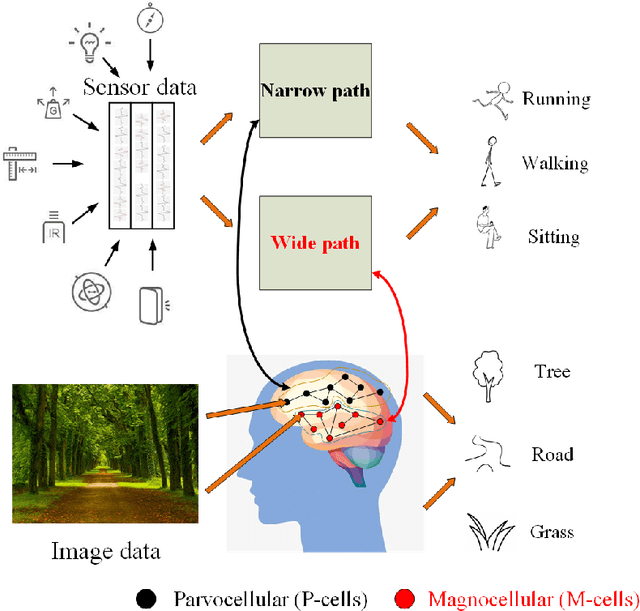

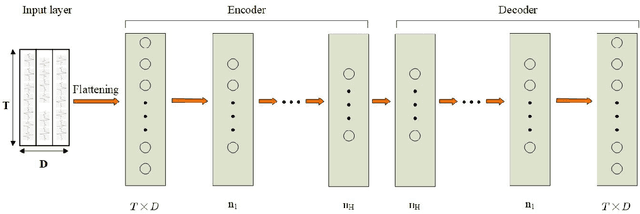
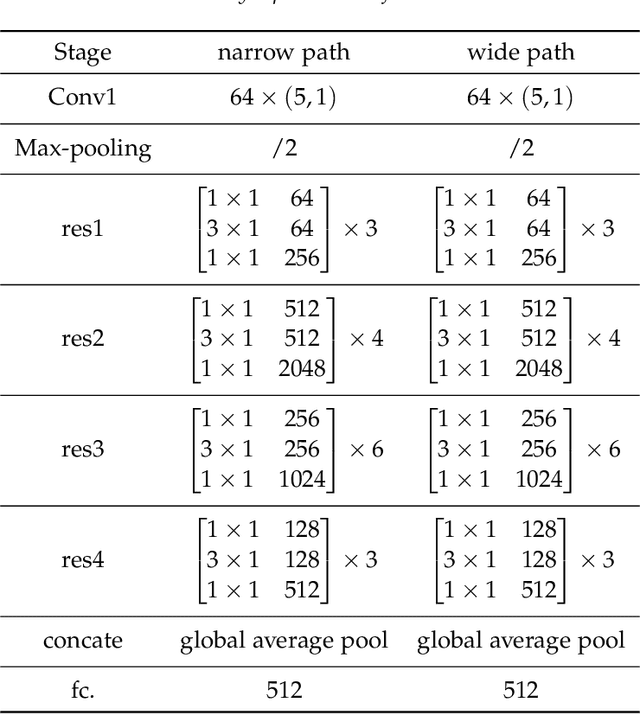
Human Activity Recognition (HAR) using deep neural network has become a hot topic in human-computer interaction. Machine can effectively identify human naturalistic activities by learning from a large collection of sensor data. Activity recognition is not only an interesting research problem, but also has many real-world practical applications. Based on the success of residual networks in achieving a high level of aesthetic representation of the automatic learning, we propose a novel \textbf{D}ual \textbf{R}esidual \textbf{N}etwork, named DRN. DRN is implemented using two identical path frameworks consisting of (1) a short time window, which is used to capture spatial features, and (2) a long time window, which is used to capture fine temporal features. The long time window path can be made very lightweight by reducing its channel capacity, yet still being able to learn useful temporal representations for activity recognition. In this paper, we mainly focus on proposing a new model to improve the accuracy of HAR. In order to demonstrate the effectiveness of DRN model, we carried out extensive experiments and compared with conventional recognition methods (HC, CBH, CBS) and learning-based methods (AE, MLP, CNN, LSTM, Hybrid, ResNet). The benchmark datasets (OPPORTUNITY, UniMiB-SHAR) were adopted by our experiments. Results from our experiments show that our model is effective in recognizing human activities via wearable datasets. We discuss the influence of networks parameters on performance to provide insights about its optimization.
DFTerNet: Towards 2-bit Dynamic Fusion Networks for Accurate Human Activity Recognition
Sep 29, 2018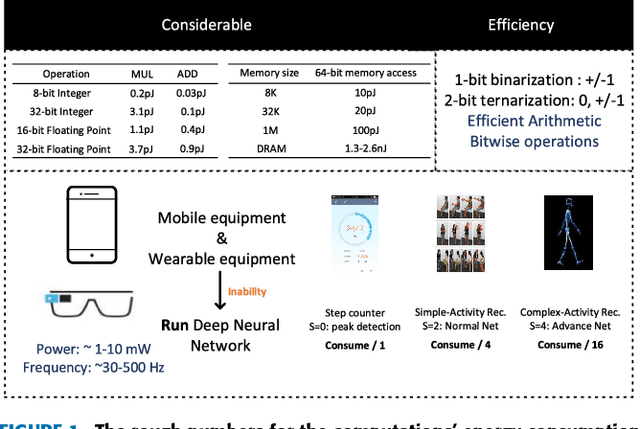
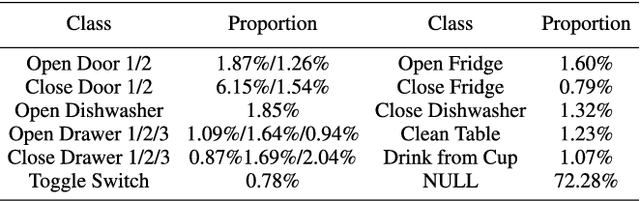
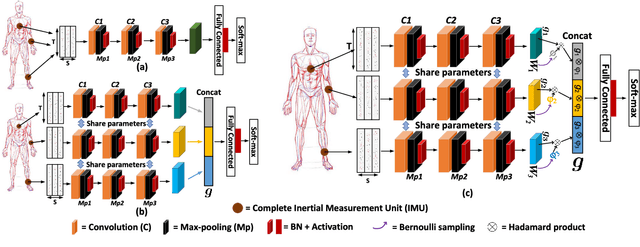
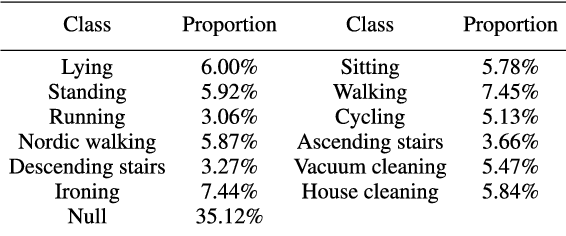
Deep Convolutional Neural Networks (DCNNs) are currently popular in human activity recognition applications. However, in the face of modern artificial intelligence sensor-based games, many research achievements cannot be practically applied on portable devices. DCNNs are typically resource-intensive and too large to be deployed on portable devices, thus this limits the practical application of complex activity detection. In addition, since portable devices do not possess high-performance Graphic Processing Units (GPUs), there is hardly any improvement in Action Game (ACT) experience. Besides, in order to deal with multi-sensor collaboration, all previous human activity recognition models typically treated the representations from different sensor signal sources equally. However, distinct types of activities should adopt different fusion strategies. In this paper, a novel scheme is proposed. This scheme is used to train 2-bit Convolutional Neural Networks with weights and activations constrained to {-0.5,0,0.5}. It takes into account the correlation between different sensor signal sources and the activity types. This model, which we refer to as DFTerNet, aims at producing a more reliable inference and better trade-offs for practical applications. Our basic idea is to exploit quantization of weights and activations directly in pre-trained filter banks and adopt dynamic fusion strategies for different activity types. Experiments demonstrate that by using dynamic fusion strategy can exceed the baseline model performance by up to ~5% on activity recognition like OPPORTUNITY and PAMAP2 datasets. Using the quantization method proposed, we were able to achieve performances closer to that of full-precision counterpart. These results were also verified using the UniMiB-SHAR dataset. In addition, the proposed method can achieve ~9x acceleration on CPUs and ~11x memory saving.