 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDUET: Dual-Paradigm Adaptive Expert Triage with Single-cell Inductive Prior for Spatial Transcriptomics Prediction
May 13, 2026Inferring spatially resolved gene expression from histology images offers a cost-effective complement to spatial transcriptomics (ST). However, existing methods reduce this task to a simple morphology-to-expression mapping, where visual similarity does not guarantee molecular consistency. Meanwhile, single-cell data has amassed rich resources far surpassing the scale of ST data, yet it remains underexplored in vision-omics modeling. Furthermore, current approaches commit to a monolithic paradigm with bottlenecks, unable to balance expressive flexibility with biological fidelity. To bridge these gaps, we propose DUET, a novel dual-paradigm framework that synergizes parametric prediction and memory-based retrieval under cellular inductive priors. DUET implements a parallel regression-retrieval paradigm, adaptively reconciling the outputs of its complementary pathways. To mitigate aleatoric vision ambiguity, we incorporate large-scale single-cell references to impose molecular states as biological constraints for faithful learning. Building upon structural refinement, we further design a lightweight adapter to dynamically assign branch preference across spatial contexts to achieve optimal performance. Extensive experiments on three public datasets across varied gene scales demonstrate that DUET achieves SOTA performance, with consistent gains contributed by each proposed component. Code is available at https://github.com/Junchao-Zhu/DUET
Square Superpixel Generation and Representation Learning via Granular Ball Computing
Mar 31, 2026Superpixels provide a compact region-based representation that preserves object boundaries and local structures, and have therefore been widely used in a variety of vision tasks to reduce computational cost. However, most existing superpixel algorithms produce irregularly shaped regions, which are not well aligned with regular operators such as convolutions. Consequently, superpixels are often treated as an offline preprocessing step, limiting parallel implementation and hindering end-to-end optimization within deep learning pipelines. Motivated by the adaptive representation and coverage property of granular-ball computing, we develop a square superpixel generation approach. Specifically, we approximate superpixels using multi-scale square blocks to avoid the computational and implementation difficulties induced by irregular shapes, enabling efficient parallel processing and learnable feature extraction. For each block, a purity score is computed based on pixel-intensity similarity, and high-quality blocks are selected accordingly. The resulting square superpixels can be readily integrated as graph nodes in graph neural networks (GNNs) or as tokens in Vision Transformers (ViTs), facilitating multi-scale information aggregation and structured visual representation. Experimental results on downstream tasks demonstrate consistent performance improvements, validating the effectiveness of the proposed method.
Explainable Pathomics Feature Visualization via Correlation-aware Conditional Feature Editing
Feb 05, 2026Pathomics is a recent approach that offers rich quantitative features beyond what black-box deep learning can provide, supporting more reproducible and explainable biomarkers in digital pathology. However, many derived features (e.g., "second-order moment") remain difficult to interpret, especially across different clinical contexts, which limits their practical adoption. Conditional diffusion models show promise for explainability through feature editing, but they typically assume feature independence**--**an assumption violated by intrinsically correlated pathomics features. Consequently, editing one feature while fixing others can push the model off the biological manifold and produce unrealistic artifacts. To address this, we propose a Manifold-Aware Diffusion (MAD) framework for controllable and biologically plausible cell nuclei editing. Unlike existing approaches, our method regularizes feature trajectories within a disentangled latent space learned by a variational auto-encoder (VAE). This ensures that manipulating a target feature automatically adjusts correlated attributes to remain within the learned distribution of real cells. These optimized features then guide a conditional diffusion model to synthesize high-fidelity images. Experiments demonstrate that our approach is able to navigate the manifold of pathomics features when editing those features. The proposed method outperforms baseline methods in conditional feature editing while preserving structural coherence.
HistoWAS: A Pathomics Framework for Large-Scale Feature-Wide Association Studies of Tissue Topology and Patient Outcomes
Dec 23, 2025High-throughput "pathomic" analysis of Whole Slide Images (WSIs) offers new opportunities to study tissue characteristics and for biomarker discovery. However, the clinical relevance of the tissue characteristics at the micro- and macro-environment level is limited by the lack of tools that facilitate the measurement of the spatial interaction of individual structure characteristics and their association with clinical parameters. To address these challenges, we introduce HistoWAS (Histology-Wide Association Study), a computational framework designed to link tissue spatial organization to clinical outcomes. Specifically, HistoWAS implements (1) a feature space that augments conventional metrics with 30 topological and spatial features, adapted from Geographic Information Systems (GIS) point pattern analysis, to quantify tissue micro-architecture; and (2) an association study engine, inspired by Phenome-Wide Association Studies (PheWAS), that performs mass univariate regression for each feature with statistical correction. As a proof of concept, we applied HistoWAS to analyze a total of 102 features (72 conventional object-level features and our 30 spatial features) using 385 PAS-stained WSIs from 206 participants in the Kidney Precision Medicine Project (KPMP). The code and data have been released to https://github.com/hrlblab/histoWAS.
SCR2-ST: Combine Single Cell with Spatial Transcriptomics for Efficient Active Sampling via Reinforcement Learning
Dec 15, 2025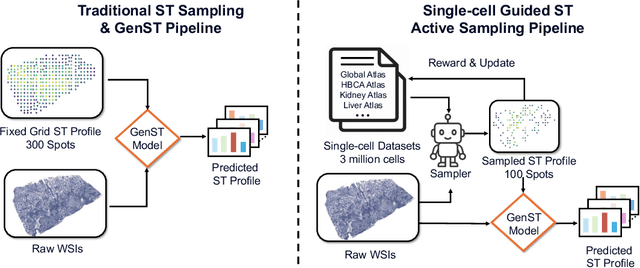
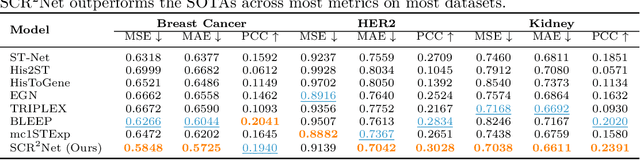
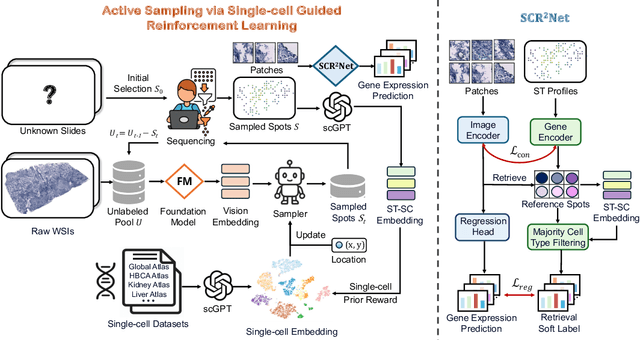
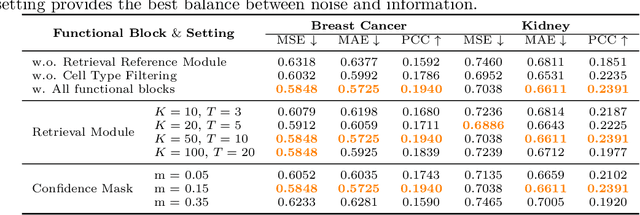
Spatial transcriptomics (ST) is an emerging technology that enables researchers to investigate the molecular relationships underlying tissue morphology. However, acquiring ST data remains prohibitively expensive, and traditional fixed-grid sampling strategies lead to redundant measurements of morphologically similar or biologically uninformative regions, thus resulting in scarce data that constrain current methods. The well-established single-cell sequencing field, however, could provide rich biological data as an effective auxiliary source to mitigate this limitation. To bridge these gaps, we introduce SCR2-ST, a unified framework that leverages single-cell prior knowledge to guide efficient data acquisition and accurate expression prediction. SCR2-ST integrates a single-cell guided reinforcement learning-based (SCRL) active sampling and a hybrid regression-retrieval prediction network SCR2Net. SCRL combines single-cell foundation model embeddings with spatial density information to construct biologically grounded reward signals, enabling selective acquisition of informative tissue regions under constrained sequencing budgets. SCR2Net then leverages the actively sampled data through a hybrid architecture combining regression-based modeling with retrieval-augmented inference, where a majority cell-type filtering mechanism suppresses noisy matches and retrieved expression profiles serve as soft labels for auxiliary supervision. We evaluated SCR2-ST on three public ST datasets, demonstrating SOTA performance in both sampling efficiency and prediction accuracy, particularly under low-budget scenarios. Code is publicly available at: https://github.com/hrlblab/SCR2ST
How Close Are We? Limitations and Progress of AI Models in Banff Lesion Scoring
Oct 31, 2025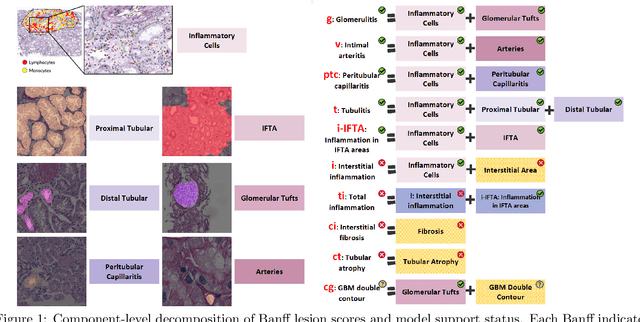
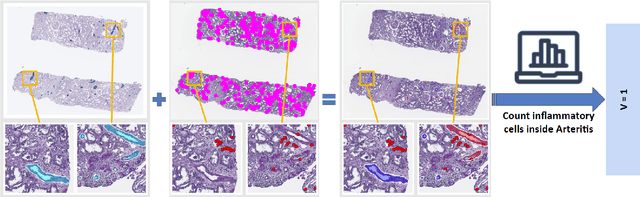
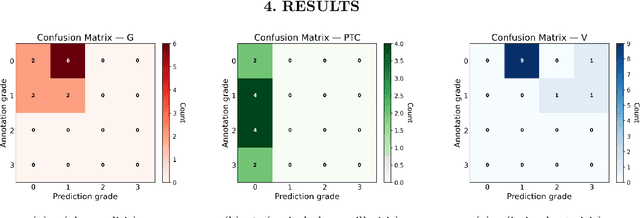
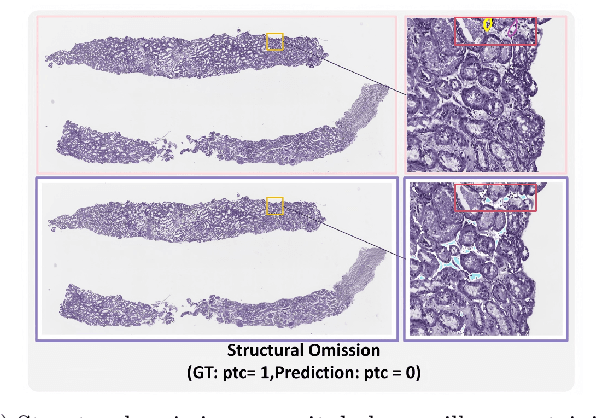
The Banff Classification provides the global standard for evaluating renal transplant biopsies, yet its semi-quantitative nature, complex criteria, and inter-observer variability present significant challenges for computational replication. In this study, we explore the feasibility of approximating Banff lesion scores using existing deep learning models through a modular, rule-based framework. We decompose each Banff indicator - such as glomerulitis (g), peritubular capillaritis (ptc), and intimal arteritis (v) - into its constituent structural and inflammatory components, and assess whether current segmentation and detection tools can support their computation. Model outputs are mapped to Banff scores using heuristic rules aligned with expert guidelines, and evaluated against expert-annotated ground truths. Our findings highlight both partial successes and critical failure modes, including structural omission, hallucination, and detection ambiguity. Even when final scores match expert annotations, inconsistencies in intermediate representations often undermine interpretability. These results reveal the limitations of current AI pipelines in replicating computational expert-level grading, and emphasize the importance of modular evaluation and computational Banff grading standard in guiding future model development for transplant pathology.
Img2ST-Net: Efficient High-Resolution Spatial Omics Prediction from Whole Slide Histology Images via Fully Convolutional Image-to-Image Learning
Aug 20, 2025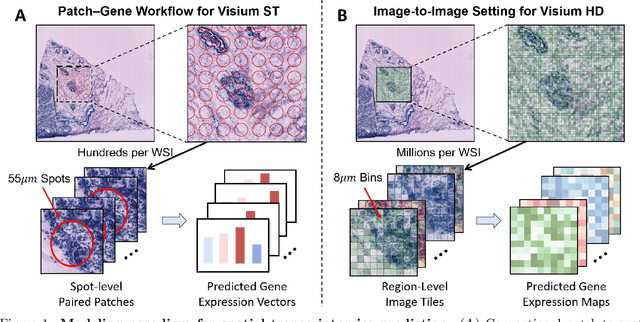
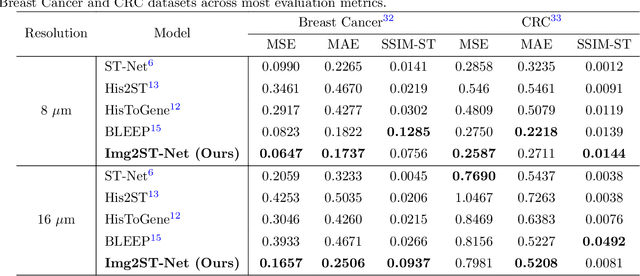
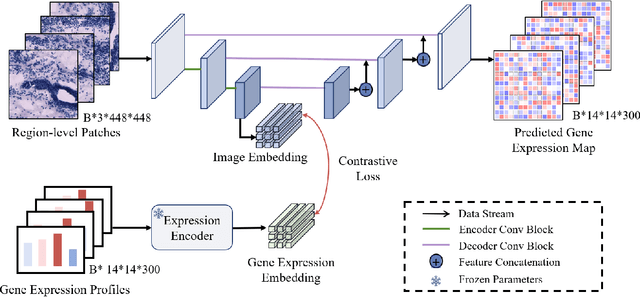
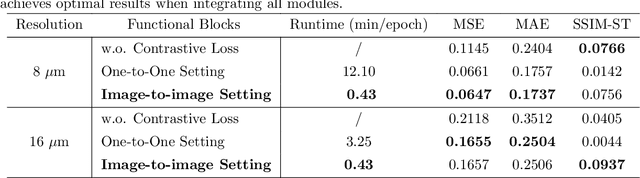
Recent advances in multi-modal AI have demonstrated promising potential for generating the currently expensive spatial transcriptomics (ST) data directly from routine histology images, offering a means to reduce the high cost and time-intensive nature of ST data acquisition. However, the increasing resolution of ST, particularly with platforms such as Visium HD achieving 8um or finer, introduces significant computational and modeling challenges. Conventional spot-by-spot sequential regression frameworks become inefficient and unstable at this scale, while the inherent extreme sparsity and low expression levels of high-resolution ST further complicate both prediction and evaluation. To address these limitations, we propose Img2ST-Net, a novel histology-to-ST generation framework for efficient and parallel high-resolution ST prediction. Unlike conventional spot-by-spot inference methods, Img2ST-Net employs a fully convolutional architecture to generate dense, HD gene expression maps in a parallelized manner. By modeling HD ST data as super-pixel representations, the task is reformulated from image-to-omics inference into a super-content image generation problem with hundreds or thousands of output channels. This design not only improves computational efficiency but also better preserves the spatial organization intrinsic to spatial omics data. To enhance robustness under sparse expression patterns, we further introduce SSIM-ST, a structural-similarity-based evaluation metric tailored for high-resolution ST analysis. We present a scalable, biologically coherent framework for high-resolution ST prediction. Img2ST-Net offers a principled solution for efficient and accurate ST inference at scale. Our contributions lay the groundwork for next-generation ST modeling that is robust and resolution-aware. The source code has been made publicly available at https://github.com/hrlblab/Img2ST-Net.
IRS: Incremental Relationship-guided Segmentation for Digital Pathology
May 28, 2025Continual learning is rapidly emerging as a key focus in computer vision, aiming to develop AI systems capable of continuous improvement, thereby enhancing their value and practicality in diverse real-world applications. In healthcare, continual learning holds great promise for continuously acquired digital pathology data, which is collected in hospitals on a daily basis. However, panoramic segmentation on digital whole slide images (WSIs) presents significant challenges, as it is often infeasible to obtain comprehensive annotations for all potential objects, spanning from coarse structures (e.g., regions and unit objects) to fine structures (e.g., cells). This results in temporally and partially annotated data, posing a major challenge in developing a holistic segmentation framework. Moreover, an ideal segmentation model should incorporate new phenotypes, unseen diseases, and diverse populations, making this task even more complex. In this paper, we introduce a novel and unified Incremental Relationship-guided Segmentation (IRS) learning scheme to address temporally acquired, partially annotated data while maintaining out-of-distribution (OOD) continual learning capacity in digital pathology. The key innovation of IRS lies in its ability to realize a new spatial-temporal OOD continual learning paradigm by mathematically modeling anatomical relationships between existing and newly introduced classes through a simple incremental universal proposition matrix. Experimental results demonstrate that the IRS method effectively handles the multi-scale nature of pathological segmentation, enabling precise kidney segmentation across various structures (regions, units, and cells) as well as OOD disease lesions at multiple magnifications. This capability significantly enhances domain generalization, making IRS a robust approach for real-world digital pathology applications.
MagNet: Multi-Level Attention Graph Network for Predicting High-Resolution Spatial Transcriptomics
Feb 28, 2025



The rapid development of spatial transcriptomics (ST) offers new opportunities to explore the gene expression patterns within the spatial microenvironment. Current research integrates pathological images to infer gene expression, addressing the high costs and time-consuming processes to generate spatial transcriptomics data. However, as spatial transcriptomics resolution continues to improve, existing methods remain primarily focused on gene expression prediction at low-resolution spot levels. These methods face significant challenges, especially the information bottleneck, when they are applied to high-resolution HD data. To bridge this gap, this paper introduces MagNet, a multi-level attention graph network designed for accurate prediction of high-resolution HD data. MagNet employs cross-attention layers to integrate features from multi-resolution image patches hierarchically and utilizes a GAT-Transformer module to aggregate neighborhood information. By integrating multilevel features, MagNet overcomes the limitations posed by low-resolution inputs in predicting high-resolution gene expression. We systematically evaluated MagNet and existing ST prediction models on both a private spatial transcriptomics dataset and a public dataset at three different resolution levels. The results demonstrate that MagNet achieves state-of-the-art performance at both spot level and high-resolution bin levels, providing a novel methodology and benchmark for future research and applications in high-resolution HD-level spatial transcriptomics. Code is available at https://github.com/Junchao-Zhu/MagNet.
KPIs 2024 Challenge: Advancing Glomerular Segmentation from Patch- to Slide-Level
Feb 11, 2025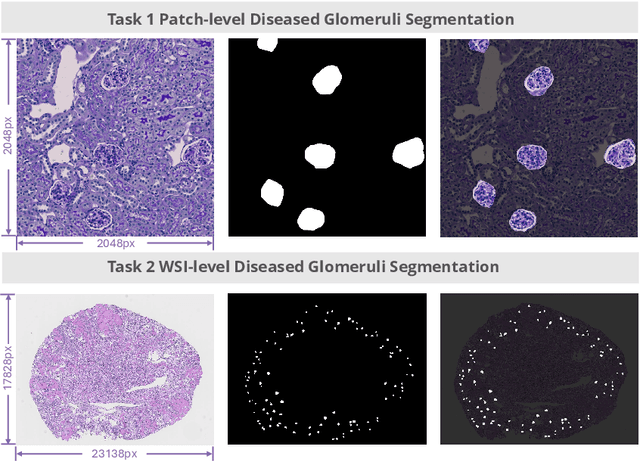

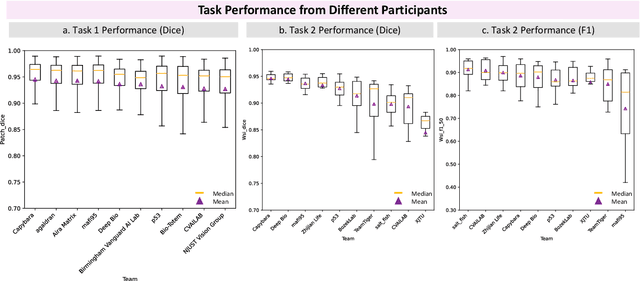

Chronic kidney disease (CKD) is a major global health issue, affecting over 10% of the population and causing significant mortality. While kidney biopsy remains the gold standard for CKD diagnosis and treatment, the lack of comprehensive benchmarks for kidney pathology segmentation hinders progress in the field. To address this, we organized the Kidney Pathology Image Segmentation (KPIs) Challenge, introducing a dataset that incorporates preclinical rodent models of CKD with over 10,000 annotated glomeruli from 60+ Periodic Acid Schiff (PAS)-stained whole slide images. The challenge includes two tasks, patch-level segmentation and whole slide image segmentation and detection, evaluated using the Dice Similarity Coefficient (DSC) and F1-score. By encouraging innovative segmentation methods that adapt to diverse CKD models and tissue conditions, the KPIs Challenge aims to advance kidney pathology analysis, establish new benchmarks, and enable precise, large-scale quantification for disease research and diagnosis.