 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Fine-grained Renal Vasculature Segmentation: Full-Scale Hierarchical Learning with FH-Seg
Feb 07, 2025Accurate fine-grained segmentation of the renal vasculature is critical for nephrological analysis, yet it faces challenges due to diverse and insufficiently annotated images. Existing methods struggle to accurately segment intricate regions of the renal vasculature, such as the inner and outer walls, arteries and lesions. In this paper, we introduce FH-Seg, a Full-scale Hierarchical Learning Framework designed for comprehensive segmentation of the renal vasculature. Specifically, FH-Seg employs full-scale skip connections that merge detailed anatomical information with contextual semantics across scales, effectively bridging the gap between structural and pathological contexts. Additionally, we implement a learnable hierarchical soft attention gates to adaptively reduce interference from non-core information, enhancing the focus on critical vascular features. To advance research on renal pathology segmentation, we also developed a Large Renal Vasculature (LRV) dataset, which contains 16,212 fine-grained annotated images of 5,600 renal arteries. Extensive experiments on the LRV dataset demonstrate FH-Seg's superior accuracies (71.23% Dice, 73.06% F1), outperforming Omni-Seg by 2.67 and 2.13 percentage points respectively. Code is available at: https://github.com/hrlblab/FH-seg.
Cross-Species Data Integration for Enhanced Layer Segmentation in Kidney Pathology
Aug 17, 2024Accurate delineation of the boundaries between the renal cortex and medulla is crucial for subsequent functional structural analysis and disease diagnosis. Training high-quality deep-learning models for layer segmentation relies on the availability of large amounts of annotated data. However, due to the patient's privacy of medical data and scarce clinical cases, constructing pathological datasets from clinical sources is relatively difficult and expensive. Moreover, using external natural image datasets introduces noise during the domain generalization process. Cross-species homologous data, such as mouse kidney data, which exhibits high structural and feature similarity to human kidneys, has the potential to enhance model performance on human datasets. In this study, we incorporated the collected private Periodic Acid-Schiff (PAS) stained mouse kidney dataset into the human kidney dataset for joint training. The results showed that after introducing cross-species homologous data, the semantic segmentation models based on CNN and Transformer architectures achieved an average increase of 1.77% and 1.24% in mIoU, and 1.76% and 0.89% in Dice score for the human renal cortex and medulla datasets, respectively. This approach is also capable of enhancing the model's generalization ability. This indicates that cross-species homologous data, as a low-noise trainable data source, can help improve model performance under conditions of limited clinical samples. Code is available at https://github.com/hrlblab/layer_segmentation.
Adaptive Asymmetric Label-guided Hashing for Multimedia Search
Jul 26, 2022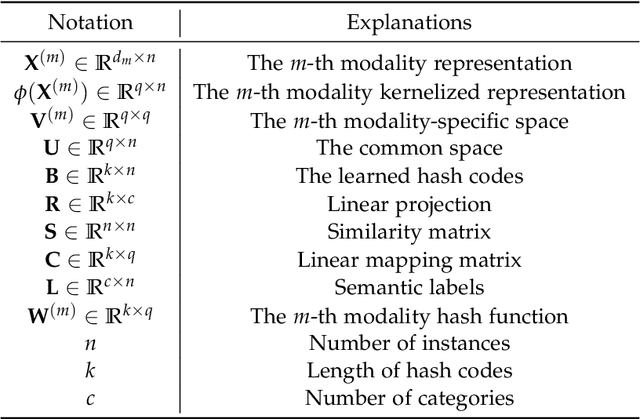
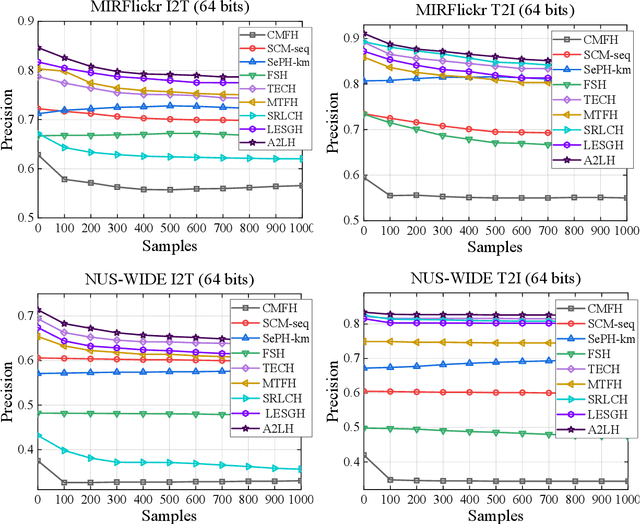
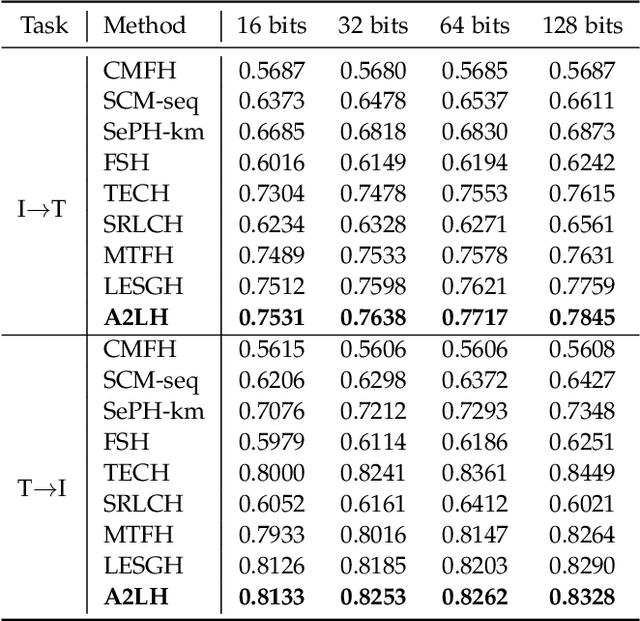
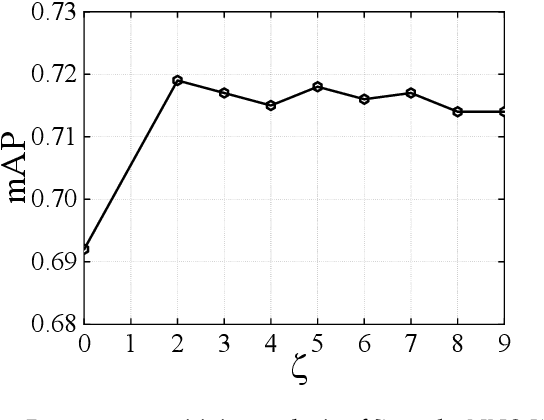
With the rapid growth of multimodal media data on the Web in recent years, hash learning methods as a way to achieve efficient and flexible cross-modal retrieval of massive multimedia data have received a lot of attention from the current Web resource retrieval research community. Existing supervised hashing methods simply transform label information into pairwise similarity information to guide hash learning, leading to a potential risk of semantic error in the face of multi-label data. In addition, most existing hash optimization methods solve NP-hard optimization problems by employing approximate approximation strategies based on relaxation strategies, leading to a large quantization error. In order to address above obstacles, we present a simple yet efficient Adaptive Asymmetric Label-guided Hashing, named A2LH, for Multimedia Search. Specifically, A2LH is a two-step hashing method. In the first step, we design an association representation model between the different modality representations and semantic label representation separately, and use the semantic label representation as an intermediate bridge to solve the semantic gap existing between different modalities. In addition, we present an efficient discrete optimization algorithm for solving the quantization error problem caused by relaxation-based optimization algorithms. In the second step, we leverage the generated hash codes to learn the hash mapping functions. The experimental results show that our proposed method achieves optimal performance on all compared baseline methods.