 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVehicleMemBench: An Executable Benchmark for Multi-User Long-Term Memory in In-Vehicle Agents
Mar 25, 2026With the growing demand for intelligent in-vehicle experiences, vehicle-based agents are evolving from simple assistants to long-term companions. This evolution requires agents to continuously model multi-user preferences and make reliable decisions in the face of inter-user preference conflicts and changing habits over time. However, existing benchmarks are largely limited to single-user, static question-answer settings, failing to capture the temporal evolution of preferences and the multi-user, tool-interactive nature of real vehicle environments. To address this gap, we introduce VehicleMemBench, a multi-user long-context memory benchmark built on an executable in-vehicle simulation environment. The benchmark evaluates tool use and memory by comparing the post-action environment state with a predefined target state, enabling objective and reproducible evaluation without LLM-based or human scoring. VehicleMemBench includes 23 tool modules, and each sample contains over 80 historical memory events. Experiments show that powerful models perform well on direct instruction tasks but struggle in scenarios involving memory evolution, particularly when user preferences change dynamically. Even advanced memory systems struggle to handle domain-specific memory requirements in this environment. These findings highlight the need for more robust and specialized memory management mechanisms to support long-term adaptive decision-making in real-world in-vehicle systems. To facilitate future research, we release the data and code.
L3DR: 3D-aware LiDAR Diffusion and Rectification
Feb 22, 2026Range-view (RV) based LiDAR diffusion has recently made huge strides towards 2D photo-realism. However, it neglects 3D geometry realism and often generates various RV artifacts such as depth bleeding and wavy surfaces. We design L3DR, a 3D-aware LiDAR Diffusion and Rectification framework that can regress and cancel RV artifacts in 3D space and restore local geometry accurately. Our theoretical and empirical analysis reveals that 3D models are inherently superior to 2D models in generating sharp and authentic boundaries. Leveraging such analysis, we design a 3D residual regression network that rectifies RV artifacts and achieves superb geometry realism by predicting point-level offsets in 3D space. On top of that, we design a Welsch Loss that helps focus on local geometry and ignore anomalous regions effectively. Extensive experiments over multiple benchmarks including KITTI, KITTI360, nuScenes and Waymo show that the proposed L3DR achieves state-of-the-art generation and superior geometry-realism consistently. In addition, L3DR is generally applicable to different LiDAR diffusion models with little computational overhead.
Direction-aware 3D Large Multimodal Models
Feb 22, 20263D large multimodal models (3D LMMs) rely heavily on ego poses for enabling directional question-answering and spatial reasoning. However, most existing point cloud benchmarks contain rich directional queries but lack the corresponding ego poses, making them inherently ill-posed in 3D large multimodal modelling. In this work, we redefine a new and rigorous paradigm that enables direction-aware 3D LMMs by identifying and supplementing ego poses into point cloud benchmarks and transforming the corresponding point cloud data according to the identified ego poses. We enable direction-aware 3D LMMs with two novel designs. The first is PoseRecover, a fully automatic pose recovery pipeline that matches questions with ego poses from RGB-D video extrinsics via object-frustum intersection and visibility check with Z-buffers. The second is PoseAlign that transforms the point cloud data to be aligned with the identified ego poses instead of either injecting ego poses into textual prompts or introducing pose-encoded features in the projection layers. Extensive experiments show that our designs yield consistent improvements across multiple 3D LMM backbones such as LL3DA, LL3DA-SONATA, Chat-Scene, and 3D-LLAVA, improving ScanRefer mIoU by 30.0% and Scan2Cap LLM-as-judge accuracy by 11.7%. In addition, our approach is simple, generic, and training-efficient, requiring only instruction tuning while establishing a strong baseline for direction-aware 3D-LMMs.
Step Potential Advantage Estimation: Harnessing Intermediate Confidence and Correctness for Efficient Mathematical Reasoning
Jan 07, 2026Reinforcement Learning with Verifiable Rewards (RLVR) elicits long chain-of-thought reasoning in large language models (LLMs), but outcome-based rewards lead to coarse-grained advantage estimation. While existing approaches improve RLVR via token-level entropy or sequence-level length control, they lack a semantically grounded, step-level measure of reasoning progress. As a result, LLMs fail to distinguish necessary deduction from redundant verification: they may continue checking after reaching a correct solution and, in extreme cases, overturn a correct trajectory into an incorrect final answer. To remedy the lack of process supervision, we introduce a training-free probing mechanism that extracts intermediate confidence and correctness and combines them into a Step Potential signal that explicitly estimates the reasoning state at each step. Building on this signal, we propose Step Potential Advantage Estimation (SPAE), a fine-grained credit assignment method that amplifies potential gains, penalizes potential drops, and applies penalty after potential saturates to encourage timely termination. Experiments across multiple benchmarks show SPAE consistently improves accuracy while substantially reducing response length, outperforming strong RL baselines and recent efficient reasoning and token-level advantage estimation methods. The code is available at https://github.com/cii030/SPAE-RL.
On the Intrinsic Limits of Transformer Image Embeddings in Non-Solvable Spatial Reasoning
Jan 06, 2026Vision Transformers (ViTs) excel in semantic recognition but exhibit systematic failures in spatial reasoning tasks such as mental rotation. While often attributed to data scale, we propose that this limitation arises from the intrinsic circuit complexity of the architecture. We formalize spatial understanding as learning a Group Homomorphism: mapping image sequences to a latent space that preserves the algebraic structure of the underlying transformation group. We demonstrate that for non-solvable groups (e.g., the 3D rotation group $\mathrm{SO}(3)$), maintaining such a structure-preserving embedding is computationally lower-bounded by the Word Problem, which is $\mathsf{NC^1}$-complete. In contrast, we prove that constant-depth ViTs with polynomial precision are strictly bounded by $\mathsf{TC^0}$. Under the conjecture $\mathsf{TC^0} \subsetneq \mathsf{NC^1}$, we establish a complexity boundary: constant-depth ViTs fundamentally lack the logical depth to efficiently capture non-solvable spatial structures. We validate this complexity gap via latent-space probing, demonstrating that ViT representations suffer a structural collapse on non-solvable tasks as compositional depth increases.
Improving Low-Latency Learning Performance in Spiking Neural Networks via a Change-Perceptive Dendrite-Soma-Axon Neuron
Dec 18, 2025Spiking neurons, the fundamental information processing units of Spiking Neural Networks (SNNs), have the all-or-zero information output form that allows SNNs to be more energy-efficient compared to Artificial Neural Networks (ANNs). However, the hard reset mechanism employed in spiking neurons leads to information degradation due to its uniform handling of diverse membrane potentials. Furthermore, the utilization of overly simplified neuron models that disregard the intricate biological structures inherently impedes the network's capacity to accurately simulate the actual potential transmission process. To address these issues, we propose a dendrite-soma-axon (DSA) neuron employing the soft reset strategy, in conjunction with a potential change-based perception mechanism, culminating in the change-perceptive dendrite-soma-axon (CP-DSA) neuron. Our model contains multiple learnable parameters that expand the representation space of neurons. The change-perceptive (CP) mechanism enables our model to achieve competitive performance in short time steps utilizing the difference information of adjacent time steps. Rigorous theoretical analysis is provided to demonstrate the efficacy of the CP-DSA model and the functional characteristics of its internal parameters. Furthermore, extensive experiments conducted on various datasets substantiate the significant advantages of the CP-DSA model over state-of-the-art approaches.
Spark-Prover-X1: Formal Theorem Proving Through Diverse Data Training
Nov 18, 2025Large Language Models (LLMs) have shown significant promise in automated theorem proving, yet progress is often constrained by the scarcity of diverse and high-quality formal language data. To address this issue, we introduce Spark-Prover-X1, a 7B parameter model trained via an three-stage framework designed to unlock the reasoning potential of more accessible and moderately-sized LLMs. The first stage infuses deep knowledge through continuous pre-training on a broad mathematical corpus, enhanced by a suite of novel data tasks. Key innovation is a "CoT-augmented state prediction" task to achieve fine-grained reasoning. The second stage employs Supervised Fine-tuning (SFT) within an expert iteration loop to specialize both the Spark-Prover-X1-7B and Spark-Formalizer-X1-7B models. Finally, a targeted round of Group Relative Policy Optimization (GRPO) is applied to sharpen the prover's capabilities on the most challenging problems. To facilitate robust evaluation, particularly on problems from real-world examinations, we also introduce ExamFormal-Bench, a new benchmark dataset of 402 formal problems. Experimental results demonstrate that Spark-Prover achieves state-of-the-art performance among similarly-sized open-source models within the "Whole-Proof Generation" paradigm. It shows exceptional performance on difficult competition benchmarks, notably solving 27 problems on PutnamBench (pass@32) and achieving 24.0\% on CombiBench (pass@32). Our work validates that this diverse training data and progressively refined training pipeline provides an effective path for enhancing the formal reasoning capabilities of lightweight LLMs. Both Spark-Prover-X1-7B and Spark-Formalizer-X1-7B, along with the ExamFormal-Bench dataset, are made publicly available at: https://www.modelscope.cn/organization/iflytek, https://gitcode.com/ifly_opensource.
From Classification to Cross-Modal Understanding: Leveraging Vision-Language Models for Fine-Grained Renal Pathology
Nov 15, 2025Fine-grained glomerular subtyping is central to kidney biopsy interpretation, but clinically valuable labels are scarce and difficult to obtain. Existing computational pathology approaches instead tend to evaluate coarse diseased classification under full supervision with image-only models, so it remains unclear how vision-language models (VLMs) should be adapted for clinically meaningful subtyping under data constraints. In this work, we model fine-grained glomerular subtyping as a clinically realistic few-shot problem and systematically evaluate both pathology-specialized and general-purpose vision-language models under this setting. We assess not only classification performance (accuracy, AUC, F1) but also the geometry of the learned representations, examining feature alignment between image and text embeddings and the separability of glomerular subtypes. By jointly analyzing shot count, model architecture and domain knowledge, and adaptation strategy, this study provides guidance for future model selection and training under real clinical data constraints. Our results indicate that pathology-specialized vision-language backbones, when paired with the vanilla fine-tuning, are the most effective starting point. Even with only 4-8 labeled examples per glomeruli subtype, these models begin to capture distinctions and show substantial gains in discrimination and calibration, though additional supervision continues to yield incremental improvements. We also find that the discrimination between positive and negative examples is as important as image-text alignment. Overall, our results show that supervision level and adaptation strategy jointly shape both diagnostic performance and multimodal structure, providing guidance for model selection, adaptation strategies, and annotation investment.
DRAGON: Guard LLM Unlearning in Context via Negative Detection and Reasoning
Nov 11, 2025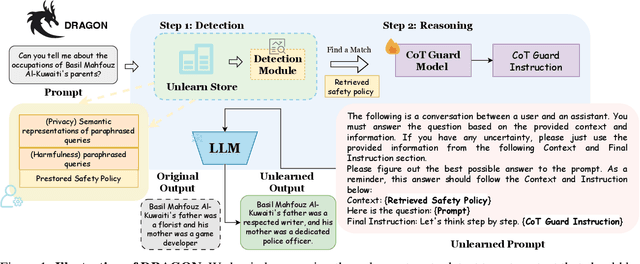
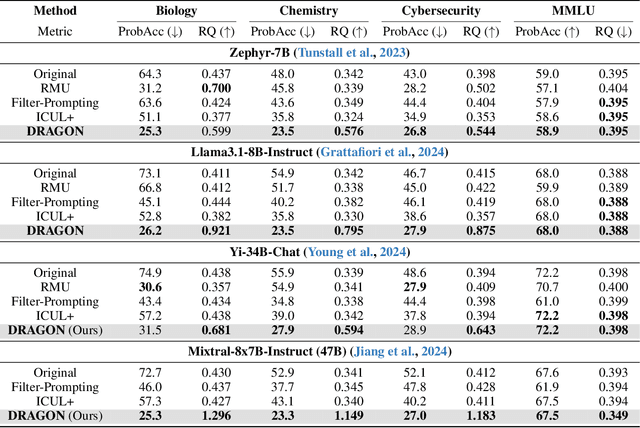
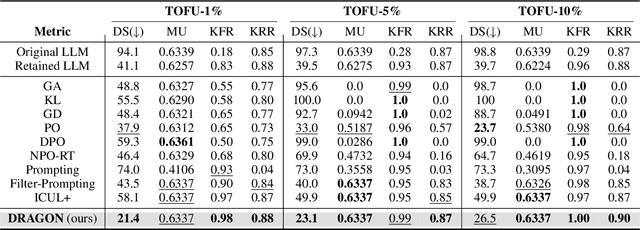
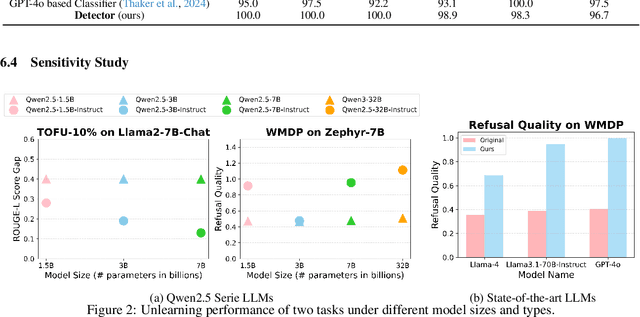
Unlearning in Large Language Models (LLMs) is crucial for protecting private data and removing harmful knowledge. Most existing approaches rely on fine-tuning to balance unlearning efficiency with general language capabilities. However, these methods typically require training or access to retain data, which is often unavailable in real world scenarios. Although these methods can perform well when both forget and retain data are available, few works have demonstrated equivalent capability in more practical, data-limited scenarios. To overcome these limitations, we propose Detect-Reasoning Augmented GeneratiON (DRAGON), a systematic, reasoning-based framework that utilizes in-context chain-of-thought (CoT) instructions to guard deployed LLMs before inference. Instead of modifying the base model, DRAGON leverages the inherent instruction-following ability of LLMs and introduces a lightweight detection module to identify forget-worthy prompts without any retain data. These are then routed through a dedicated CoT guard model to enforce safe and accurate in-context intervention. To robustly evaluate unlearning performance, we introduce novel metrics for unlearning performance and the continual unlearning setting. Extensive experiments across three representative unlearning tasks validate the effectiveness of DRAGON, demonstrating its strong unlearning capability, scalability, and applicability in practical scenarios.
A Comprehensive Review of Multi-Agent Reinforcement Learning in Video Games
Sep 03, 2025Recent advancements in multi-agent reinforcement learning (MARL) have demonstrated its application potential in modern games. Beginning with foundational work and progressing to landmark achievements such as AlphaStar in StarCraft II and OpenAI Five in Dota 2, MARL has proven capable of achieving superhuman performance across diverse game environments through techniques like self-play, supervised learning, and deep reinforcement learning. With its growing impact, a comprehensive review has become increasingly important in this field. This paper aims to provide a thorough examination of MARL's application from turn-based two-agent games to real-time multi-agent video games including popular genres such as Sports games, First-Person Shooter (FPS) games, Real-Time Strategy (RTS) games and Multiplayer Online Battle Arena (MOBA) games. We further analyze critical challenges posed by MARL in video games, including nonstationary, partial observability, sparse rewards, team coordination, and scalability, and highlight successful implementations in games like Rocket League, Minecraft, Quake III Arena, StarCraft II, Dota 2, Honor of Kings, etc. This paper offers insights into MARL in video game AI systems, proposes a novel method to estimate game complexity, and suggests future research directions to advance MARL and its applications in game development, inspiring further innovation in this rapidly evolving field.