 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure-Guided Allocation of 2D Gaussians for Image Representation and Compression
Dec 30, 2025Recent advances in 2D Gaussian Splatting (2DGS) have demonstrated its potential as a compact image representation with millisecond-level decoding. However, existing 2DGS-based pipelines allocate representation capacity and parameter precision largely oblivious to image structure, limiting their rate-distortion (RD) efficiency at low bitrates. To address this, we propose a structure-guided allocation principle for 2DGS, which explicitly couples image structure with both representation capacity and quantization precision, while preserving native decoding speed. First, we introduce a structure-guided initialization that assigns 2D Gaussians according to spatial structural priors inherent in natural images, yielding a localized and semantically meaningful distribution. Second, during quantization-aware fine-tuning, we propose adaptive bitwidth quantization of covariance parameters, which grants higher precision to small-scale Gaussians in complex regions and lower precision elsewhere, enabling RD-aware optimization, thereby reducing redundancy without degrading edge quality. Third, we impose a geometry-consistent regularization that aligns Gaussian orientations with local gradient directions to better preserve structural details. Extensive experiments demonstrate that our approach substantially improves both the representational power and the RD performance of 2DGS while maintaining over 1000 FPS decoding. Compared with the baseline GSImage, we reduce BD-rate by 43.44% on Kodak and 29.91% on DIV2K.
Structural Information-based Hierarchical Diffusion for Offline Reinforcement Learning
Sep 26, 2025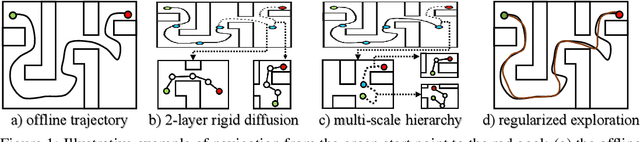
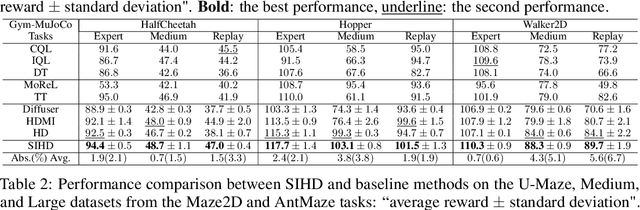
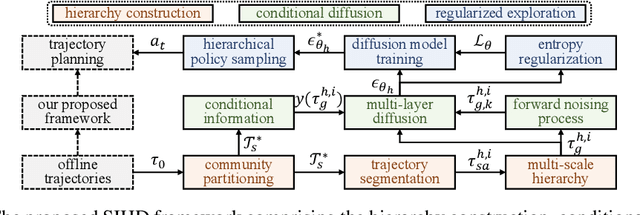
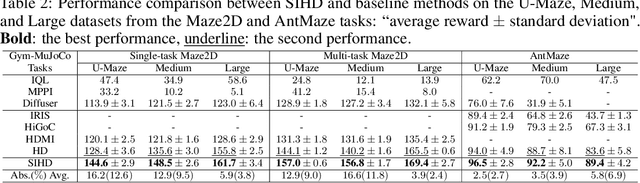
Diffusion-based generative methods have shown promising potential for modeling trajectories from offline reinforcement learning (RL) datasets, and hierarchical diffusion has been introduced to mitigate variance accumulation and computational challenges in long-horizon planning tasks. However, existing approaches typically assume a fixed two-layer diffusion hierarchy with a single predefined temporal scale, which limits adaptability to diverse downstream tasks and reduces flexibility in decision making. In this work, we propose SIHD, a novel Structural Information-based Hierarchical Diffusion framework for effective and stable offline policy learning in long-horizon environments with sparse rewards. Specifically, we analyze structural information embedded in offline trajectories to construct the diffusion hierarchy adaptively, enabling flexible trajectory modeling across multiple temporal scales. Rather than relying on reward predictions from localized sub-trajectories, we quantify the structural information gain of each state community and use it as a conditioning signal within the corresponding diffusion layer. To reduce overreliance on offline datasets, we introduce a structural entropy regularizer that encourages exploration of underrepresented states while avoiding extrapolation errors from distributional shifts. Extensive evaluations on challenging offline RL tasks show that SIHD significantly outperforms state-of-the-art baselines in decision-making performance and demonstrates superior generalization across diverse scenarios.
Enhancing the Geometric Problem-Solving Ability of Multimodal LLMs via Symbolic-Neural Integration
Apr 17, 2025Recent advances in Multimodal Large Language Models (MLLMs) have achieved remarkable progress in general domains and demonstrated promise in multimodal mathematical reasoning. However, applying MLLMs to geometry problem solving (GPS) remains challenging due to lack of accurate step-by-step solution data and severe hallucinations during reasoning. In this paper, we propose GeoGen, a pipeline that can automatically generates step-wise reasoning paths for geometry diagrams. By leveraging the precise symbolic reasoning, \textbf{GeoGen} produces large-scale, high-quality question-answer pairs. To further enhance the logical reasoning ability of MLLMs, we train \textbf{GeoLogic}, a Large Language Model (LLM) using synthetic data generated by GeoGen. Serving as a bridge between natural language and symbolic systems, GeoLogic enables symbolic tools to help verifying MLLM outputs, making the reasoning process more rigorous and alleviating hallucinations. Experimental results show that our approach consistently improves the performance of MLLMs, achieving remarkable results on benchmarks for geometric reasoning tasks. This improvement stems from our integration of the strengths of LLMs and symbolic systems, which enables a more reliable and interpretable approach for the GPS task. Codes are available at https://github.com/ycpNotFound/GeoGen.
HILL: Hierarchy-aware Information Lossless Contrastive Learning for Hierarchical Text Classification
Mar 26, 2024



Existing self-supervised methods in natural language processing (NLP), especially hierarchical text classification (HTC), mainly focus on self-supervised contrastive learning, extremely relying on human-designed augmentation rules to generate contrastive samples, which can potentially corrupt or distort the original information. In this paper, we tend to investigate the feasibility of a contrastive learning scheme in which the semantic and syntactic information inherent in the input sample is adequately reserved in the contrastive samples and fused during the learning process. Specifically, we propose an information lossless contrastive learning strategy for HTC, namely \textbf{H}ierarchy-aware \textbf{I}nformation \textbf{L}ossless contrastive \textbf{L}earning (HILL), which consists of a text encoder representing the input document, and a structure encoder directly generating the positive sample. The structure encoder takes the document embedding as input, extracts the essential syntactic information inherent in the label hierarchy with the principle of structural entropy minimization, and injects the syntactic information into the text representation via hierarchical representation learning. Experiments on three common datasets are conducted to verify the superiority of HILL.
A Simple yet Effective Method for Graph Classification
Jun 06, 2022
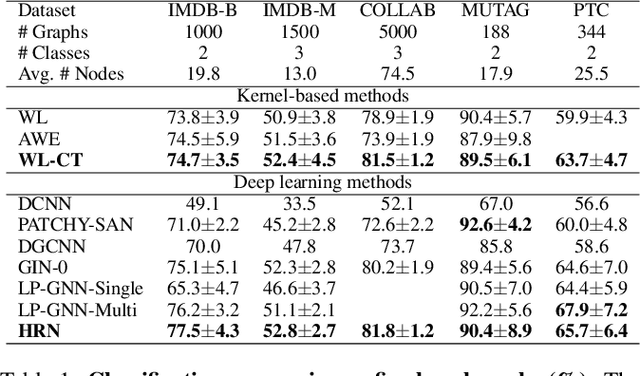
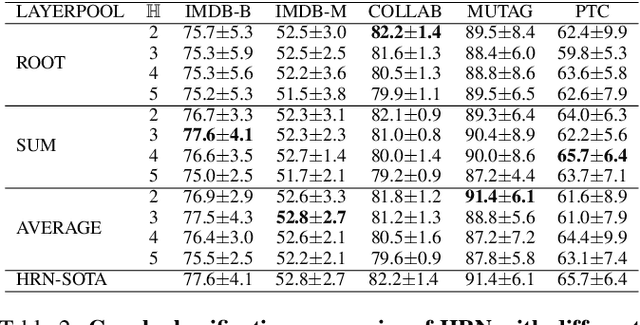
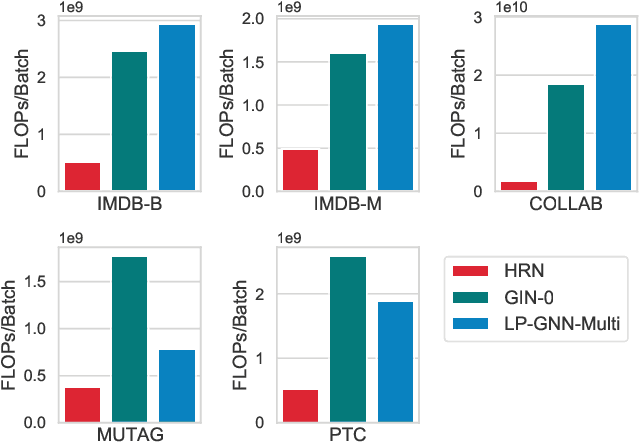
In deep neural networks, better results can often be obtained by increasing the complexity of previously developed basic models. However, it is unclear whether there is a way to boost performance by decreasing the complexity of such models. Intuitively, given a problem, a simpler data structure comes with a simpler algorithm. Here, we investigate the feasibility of improving graph classification performance while simplifying the learning process. Inspired by structural entropy on graphs, we transform the data sample from graphs to coding trees, which is a simpler but essential structure for graph data. Furthermore, we propose a novel message passing scheme, termed hierarchical reporting, in which features are transferred from leaf nodes to root nodes by following the hierarchical structure of coding trees. We then present a tree kernel and a convolutional network to implement our scheme for graph classification. With the designed message passing scheme, the tree kernel and convolutional network have a lower runtime complexity of $O(n)$ than Weisfeiler-Lehman subtree kernel and other graph neural networks of at least $O(hm)$. We empirically validate our methods with several graph classification benchmarks and demonstrate that they achieve better performance and lower computational consumption than competing approaches.
Structural Optimization Makes Graph Classification Simpler and Better
Sep 05, 2021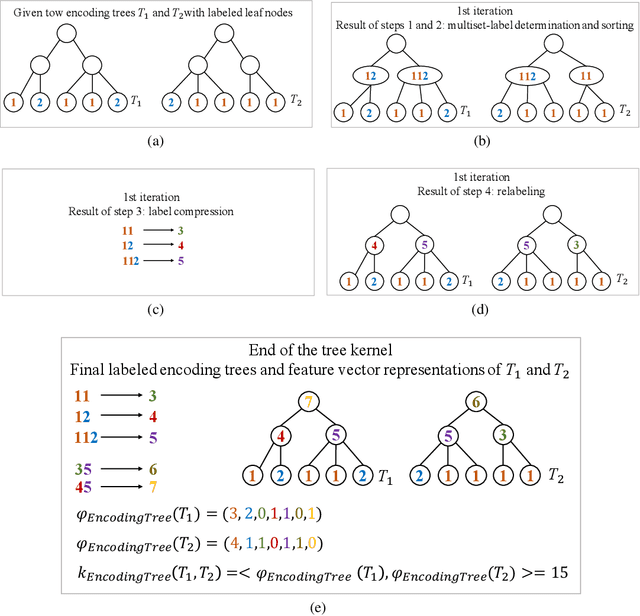
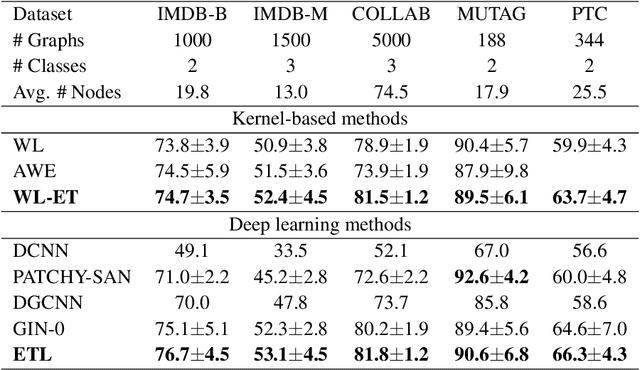
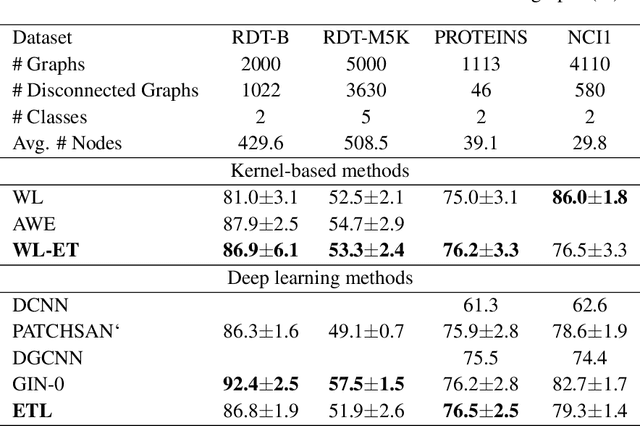
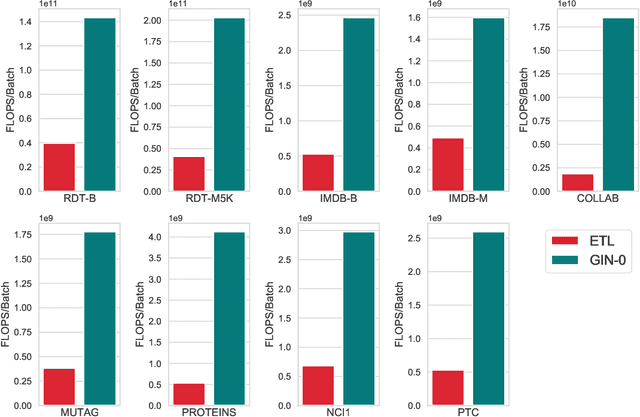
In deep neural networks, better results can often be obtained by increasing the complexity of previously developed basic models. However, it is unclear whether there is a way to boost performance by decreasing the complexity of such models. Here, based on an optimization method, we investigate the feasibility of improving graph classification performance while simplifying the model learning process. Inspired by progress in structural information assessment, we optimize the given data sample from graphs to encoding trees. In particular, we minimize the structural entropy of the transformed encoding tree to decode the key structure underlying a graph. This transformation is denoted as structural optimization. Furthermore, we propose a novel feature combination scheme, termed hierarchical reporting, for encoding trees. In this scheme, features are transferred from leaf nodes to root nodes by following the hierarchical structures of encoding trees. We then present an implementation of the scheme in a tree kernel and a convolutional network to perform graph classification. The tree kernel follows label propagation in the Weisfeiler-Lehman (WL) subtree kernel, but it has a lower runtime complexity $O(n)$. The convolutional network is a special implementation of our tree kernel in the deep learning field and is called Encoding Tree Learning (ETL). We empirically validate our tree kernel and convolutional network with several graph classification benchmarks and demonstrate that our methods achieve better performance and lower computational consumption than competing approaches.
An Information-theoretic Perspective of Hierarchical Clustering
Aug 13, 2021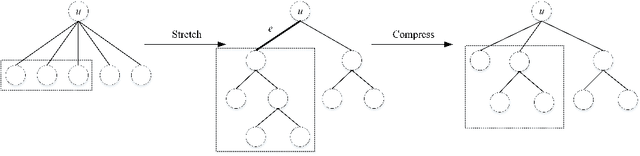
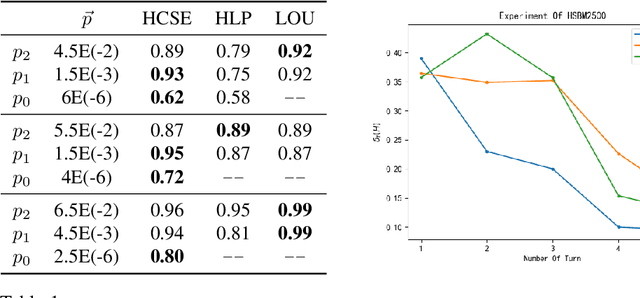
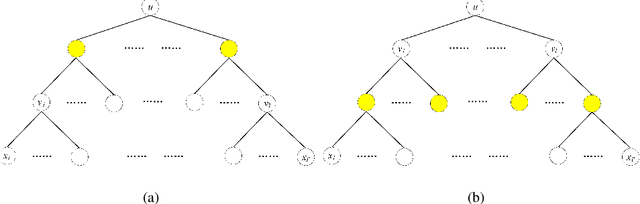
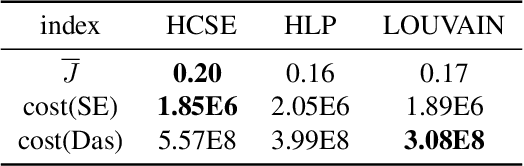
A combinatorial cost function for hierarchical clustering was introduced by Dasgupta \cite{dasgupta2016cost}. It has been generalized by Cohen-Addad et al. \cite{cohen2019hierarchical} to a general form named admissible function. In this paper, we investigate hierarchical clustering from the \emph{information-theoretic} perspective and formulate a new objective function. We also establish the relationship between these two perspectives. In algorithmic aspect, we get rid of the traditional top-down and bottom-up frameworks, and propose a new one to stratify the \emph{sparsest} level of a cluster tree recursively in guide with our objective function. For practical use, our resulting cluster tree is not binary. Our algorithm called HCSE outputs a $k$-level cluster tree by a novel and interpretable mechanism to choose $k$ automatically without any hyper-parameter. Our experimental results on synthetic datasets show that HCSE has a great advantage in finding the intrinsic number of hierarchies, and the results on real datasets show that HCSE also achieves competitive costs over the popular algorithms LOUVAIN and HLP.