 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNL2Repo-Bench: Towards Long-Horizon Repository Generation Evaluation of Coding Agents
Dec 14, 2025Recent advances in coding agents suggest rapid progress toward autonomous software development, yet existing benchmarks fail to rigorously evaluate the long-horizon capabilities required to build complete software systems. Most prior evaluations focus on localized code generation, scaffolded completion, or short-term repair tasks, leaving open the question of whether agents can sustain coherent reasoning, planning, and execution over the extended horizons demanded by real-world repository construction. To address this gap, we present NL2Repo Bench, a benchmark explicitly designed to evaluate the long-horizon repository generation ability of coding agents. Given only a single natural-language requirements document and an empty workspace, agents must autonomously design the architecture, manage dependencies, implement multi-module logic, and produce a fully installable Python library. Our experiments across state-of-the-art open- and closed-source models reveal that long-horizon repository generation remains largely unsolved: even the strongest agents achieve below 40% average test pass rates and rarely complete an entire repository correctly. Detailed analysis uncovers fundamental long-horizon failure modes, including premature termination, loss of global coherence, fragile cross-file dependencies, and inadequate planning over hundreds of interaction steps. NL2Repo Bench establishes a rigorous, verifiable testbed for measuring sustained agentic competence and highlights long-horizon reasoning as a central bottleneck for the next generation of autonomous coding agents.
Graph Out-of-Distribution Detection via Test-Time Calibration with Dual Dynamic Dictionaries
Nov 17, 2025A key challenge in graph out-of-distribution (OOD) detection lies in the absence of ground-truth OOD samples during training. Existing methods are typically optimized to capture features within the in-distribution (ID) data and calculate OOD scores, which often limits pre-trained models from representing distributional boundaries, leading to unreliable OOD detection. Moreover, the latent structure of graph data is often governed by multiple underlying factors, which remains less explored. To address these challenges, we propose a novel test-time graph OOD detection method, termed BaCa, that calibrates OOD scores using dual dynamically updated dictionaries without requiring fine-tuning the pre-trained model. Specifically, BaCa estimates graphons and applies a mix-up strategy solely with test samples to generate diverse boundary-aware discriminative topologies, eliminating the need for exposing auxiliary datasets as outliers. We construct dual dynamic dictionaries via priority queues and attention mechanisms to adaptively capture latent ID and OOD representations, which are then utilized for boundary-aware OOD score calibration. To the best of our knowledge, extensive experiments on real-world datasets show that BaCa significantly outperforms existing state-of-the-art methods in OOD detection.
Accelerating Multi-Objective Collaborative Optimization of Doped Thermoelectric Materials via Artificial Intelligence
Apr 11, 2025The thermoelectric performance of materials exhibits complex nonlinear dependencies on both elemental types and their proportions, rendering traditional trial-and-error approaches inefficient and time-consuming for material discovery. In this work, we present a deep learning model capable of accurately predicting thermoelectric properties of doped materials directly from their chemical formulas, achieving state-of-the-art performance. To enhance interpretability, we further incorporate sensitivity analysis techniques to elucidate how physical descriptors affect the thermoelectric figure of merit (zT). Moreover, we establish a coupled framework that integrates a surrogate model with a multi-objective genetic algorithm to efficiently explore the vast compositional space for high-performance candidates. Experimental validation confirms the discovery of a novel thermoelectric material with superior $zT$ values in the medium-temperature regime.
Structural Entropy Guided Unsupervised Graph Out-Of-Distribution Detection
Mar 05, 2025With the emerging of huge amount of unlabeled data, unsupervised out-of-distribution (OOD) detection is vital for ensuring the reliability of graph neural networks (GNNs) by identifying OOD samples from in-distribution (ID) ones during testing, where encountering novel or unknown data is inevitable. Existing methods often suffer from compromised performance due to redundant information in graph structures, which impairs their ability to effectively differentiate between ID and OOD data. To address this challenge, we propose SEGO, an unsupervised framework that integrates structural entropy into OOD detection regarding graph classification. Specifically, within the architecture of contrastive learning, SEGO introduces an anchor view in the form of coding tree by minimizing structural entropy. The obtained coding tree effectively removes redundant information from graphs while preserving essential structural information, enabling the capture of distinct graph patterns between ID and OOD samples. Furthermore, we present a multi-grained contrastive learning scheme at local, global, and tree levels using triplet views, where coding trees with essential information serve as the anchor view. Extensive experiments on real-world datasets validate the effectiveness of SEGO, demonstrating superior performance over state-of-the-art baselines in OOD detection. Specifically, our method achieves the best performance on 9 out of 10 dataset pairs, with an average improvement of 3.7\% on OOD detection datasets, significantly surpassing the best competitor by 10.8\% on the FreeSolv/ToxCast dataset pair.
NC-NCD: Novel Class Discovery for Node Classification
Jul 25, 2024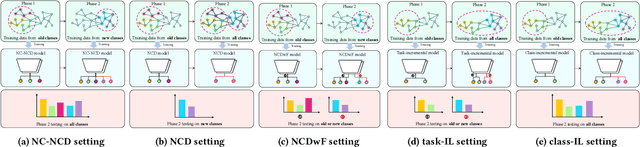

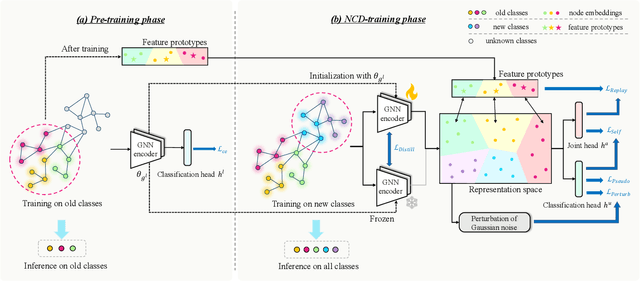
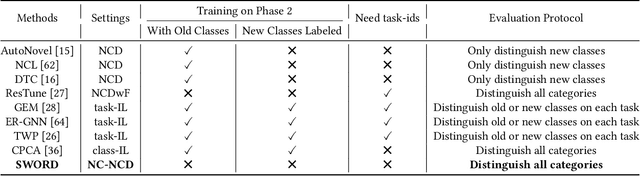
Novel Class Discovery (NCD) involves identifying new categories within unlabeled data by utilizing knowledge acquired from previously established categories. However, existing NCD methods often struggle to maintain a balance between the performance of old and new categories. Discovering unlabeled new categories in a class-incremental way is more practical but also more challenging, as it is frequently hindered by either catastrophic forgetting of old categories or an inability to learn new ones. Furthermore, the implementation of NCD on continuously scalable graph-structured data remains an under-explored area. In response to these challenges, we introduce for the first time a more practical NCD scenario for node classification (i.e., NC-NCD), and propose a novel self-training framework with prototype replay and distillation called SWORD, adopted to our NC-NCD setting. Our approach enables the model to cluster unlabeled new category nodes after learning labeled nodes while preserving performance on old categories without reliance on old category nodes. SWORD achieves this by employing a self-training strategy to learn new categories and preventing the forgetting of old categories through the joint use of feature prototypes and knowledge distillation. Extensive experiments on four common benchmarks demonstrate the superiority of SWORD over other state-of-the-art methods.
HILL: Hierarchy-aware Information Lossless Contrastive Learning for Hierarchical Text Classification
Mar 26, 2024



Existing self-supervised methods in natural language processing (NLP), especially hierarchical text classification (HTC), mainly focus on self-supervised contrastive learning, extremely relying on human-designed augmentation rules to generate contrastive samples, which can potentially corrupt or distort the original information. In this paper, we tend to investigate the feasibility of a contrastive learning scheme in which the semantic and syntactic information inherent in the input sample is adequately reserved in the contrastive samples and fused during the learning process. Specifically, we propose an information lossless contrastive learning strategy for HTC, namely \textbf{H}ierarchy-aware \textbf{I}nformation \textbf{L}ossless contrastive \textbf{L}earning (HILL), which consists of a text encoder representing the input document, and a structure encoder directly generating the positive sample. The structure encoder takes the document embedding as input, extracts the essential syntactic information inherent in the label hierarchy with the principle of structural entropy minimization, and injects the syntactic information into the text representation via hierarchical representation learning. Experiments on three common datasets are conducted to verify the superiority of HILL.